
Tales from the Evil Empire
Bertrand Le Roy's blog
-
Secrets of the Grey Beards: drawing circles with additions and shifts
A long time ago, before GPUs, before multicore processors and gigabytes of RAM, clever algorithms were the only way to render complex graphics in real-time. Those algorithms are now mostly forgotten as nobody needs them or is interested in them. Nobody? Well, almost. I like to reverse-engineer the clever tricks programmers of that era were using (in fact, I was one of them), and I hope you'll follow me on this exploration.
-
Use explicit Lambdas with LINQ
Here's an interesting bug... What's wrong with this code?
-
A breaking change in .NET argument exception message formatting
A quick reference post about an interesting change in the way .NET formats argument exception messages. This tripped me up when debugging a test that was failing on .NET Core / 6.0 whereas it had been passing forever and still passes on .NET Framework / 4.7. The test was expecting a specific error message. Because .NET Core apparently has changed the format string used for argument exception messages, that expectation was broken.
-
3D before GPUs Part 1: Dungeon Master
In this series, I'll reverse-engineer algorithms from video games dating back to that time when the CPU was all you had. Today, we're looking at Dungeon Master, a fantastic game by FTL that set the gold standard for RPGs for the years to follow. It looked amazing, and still does to this day. It changed everything.
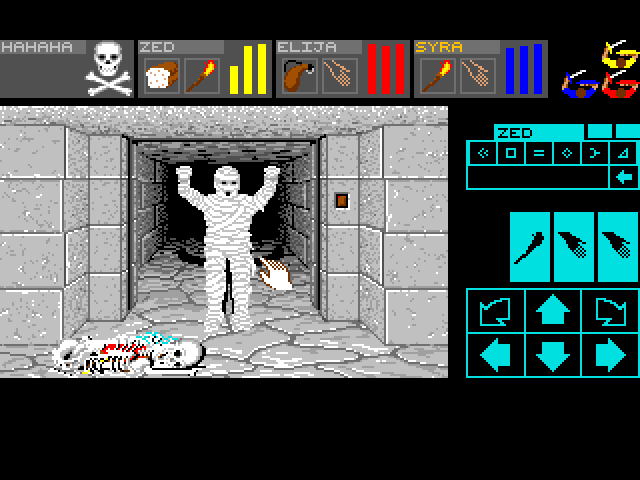
-
LunrCore, a lightweight search library for .NET
 I'm pretty much convinced almost all applications need search. No matter what you're building, you'll likely handle data, and no matter how well you organize it, a good text search is often the fastest way for your users to find what they're looking for. As such, search should be a commodity, a feature that should be as easy as possible to integrate. I'm so convinced of that in fact that my day job is on Azure Cognitive Search, a Microsoft product that provides search as a service and makes indexing smart by adding a customizable pipeline of AI and machine learning enrichments.
I'm pretty much convinced almost all applications need search. No matter what you're building, you'll likely handle data, and no matter how well you organize it, a good text search is often the fastest way for your users to find what they're looking for. As such, search should be a commodity, a feature that should be as easy as possible to integrate. I'm so convinced of that in fact that my day job is on Azure Cognitive Search, a Microsoft product that provides search as a service and makes indexing smart by adding a customizable pipeline of AI and machine learning enrichments. -
Why I dislike tuple return types
Tuples are great additions to C#. They're simple immutable structures made of a small number of members organized in a specific order. For example, a point on a plane could be represented as a pair of X and Y coordinates, or a person's name could be represented as a title, first, middle and last names. If the types are that simple, and have no custom logic associated with them, using a tuple looks like a lightweight and simple implementation that requires a lot less effort than a simple class or struct. Dynamic and functional languages have long enjoyed tuples, of course, but I like how the C# implementation manages to stay true to the core tenets of the language, in particular type safety.
-
The case of the defined undefined property
 I like JavaScript, for some reason, I really do, and I still write and maintain a few open source JavaScript projects. It’s undeniable that it has bad parts though, that remain today, even in strict ES2017. In this post, I want to show you one that builds an interesting bug farm.
I like JavaScript, for some reason, I really do, and I still write and maintain a few open source JavaScript projects. It’s undeniable that it has bad parts though, that remain today, even in strict ES2017. In this post, I want to show you one that builds an interesting bug farm. -
Quantum computing and topological qubits explained clearly
Don't let yourself be intimidated by all the quantum jargon. The bases of quantum computing are not that complicated, and I can explain them to anyone who understands programming, classical logic gates, the bare minimum about complex numbers and linear algebra… I'll do so in the light of Microsoft's recent announcement of a new discovery that could bring us much more stable quantum computers.
-
Orchard Harvest 2017–Orchard Core CMS
For the last presentation of the day, Sébastien explained what Orchard Core is all about. Orchard Core runs on ASP.NET Core, and as a consequence is leaner, faster, and cross-platform. One big change is that its content is persisted as documents instead of relational tables.
-
Orchard Harvest 2017–YesSql
Sébastien Ros gave a surprise demo of YesSql, the document database interface over relational databases that powers Orchard Core’s data access. YesSql stores plain objects into documents stored on a relational database. It supports SQL Server, MySql, Postgre, Sqlite, LightningDB, and in-memory. YesSql also allows for querying those objects using queryable indexes. Those indexes are projections of documents into structured tables, that only exist for the purpose of being queried.