LLBLGen Pro feature highlights: grouping model elements
(This post is part of a series of posts about features of the LLBLGen Pro system)
When working with an entity model which has more than a few entities, it's often convenient to be able to group entities together if they belong to a semantic sub-model. For example, if your entity model has several entities which are about 'security', it would be practical to group them together under the 'security' moniker. This way, you could easily find them back, yet they can be left inside the complete entity model altogether so their relationships with entities outside the group are kept.
In other situations your domain consists of semi-separate entity models which all target tables/views which are located in the same database. It then might be convenient to have a single project to manage the complete target database, yet have the entity models separate of each other and have them result in separate code bases.
LLBLGen Pro can do both for you. This blog post will illustrate both situations. The feature is called group usage and is controllable through the project settings. This setting is supported on all supported O/R mapper frameworks.
Situation one: grouping entities in a single model.
This situation is common for entity models which are dense, so many relationships exist between all sub-models: you can't split them up easily into separate models (nor do you likely want to), however it's convenient to have them grouped together into groups inside the entity model at the project level. A typical example for this is the AdventureWorks example database for SQL Server. This database, which is a single catalog, has for each sub-group a schema, however most of these schemas are tightly connected with each other: adding all schemas together will give a model with entities which indirectly are related to all other entities. LLBLGen Pro's default setting for group usage is AsVisualGroupingMechanism which is what this situation is all about: we group the elements for visual purposes, it has no real meaning for the model nor the code generated.
Let's reverse engineer AdventureWorks to an entity model. By default, LLBLGen Pro uses the target schema an element is in which is being reverse engineered, as the group it will be in. This is convenient if you already have categorized tables/views in schemas, like which is the case in AdventureWorks. Of course this can be switched off, or corrected on the fly.
When reverse engineering, we'll walk through a wizard which will guide us with the selection of the elements which relational model data should be retrieved, which we can later on use to reverse engineer to an entity model. The first step after specifying which database server connect to is to select these elements. below we can see the AdventureWorks catalog as well as the different schemas it contains. We'll include all of them.
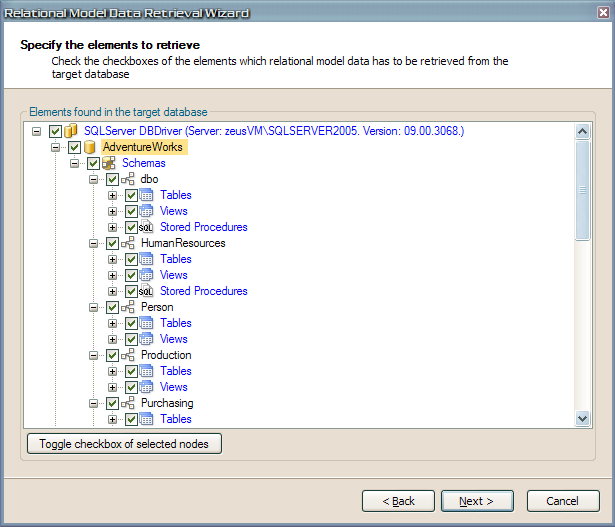
After the wizard completes, we have all relational model data nicely in our catalog data, with schemas. So let's reverse engineer entities from the tables in these schemas. We select in the catalog explorer the schemas 'HumanResources', 'Person', 'Production', 'Purchasing' and 'Sales', then right-click one of them and from the context menu, we select Reverse engineer Tables to Entity Definitions.... This will bring up the dialog below. We check all checkboxes in one go by checking the checkbox at the top to mark them all to be added to the project.
![sshot_[3]](https://aspblogs.blob.core.windows.net/media/fbouma/WindowsLiveWriter/LLBLGenProfeaturehighlightsgroupingmodel_ABCC/sshot_%255B3%255D_3.png)
As you can see LLBLGen Pro has already filled in the group name based on the schema name, as this is the default and we didn't change the setting. If you want, you can select multiple rows at once and set the group name to something else using the controls on the dialog. We're fine with the group names chosen so we'll simply click Add to Project. This gives the following result:
![sshot_[6]](https://aspblogs.blob.core.windows.net/media/fbouma/WindowsLiveWriter/LLBLGenProfeaturehighlightsgroupingmodel_ABCC/sshot_%255B6%255D_3.png)
(I collapsed the other groups to keep the picture small ;)). As you can see, the entities are now grouped. Just to see how dense this model is, I've expanded the relationships of Employee:
![sshot_[7]](https://aspblogs.blob.core.windows.net/media/fbouma/WindowsLiveWriter/LLBLGenProfeaturehighlightsgroupingmodel_ABCC/sshot_%255B7%255D_2.png)
As you can see, it has relationships with entities from three other groups than HumanResources. It's not doable to cut up this project into sub-models without duplicating the Employee entity in all those groups, so this model is better suited to be used as a single model resulting in a single code base, however it benefits greatly from having its entities grouped into separate groups at the project level, to make work done on the model easier.
Now let's look at another situation, namely where we work with a single database while we want to have multiple models and for each model a separate code base.
Situation two: grouping entities in separate models within the same project.
To get rid of the entities to see the second situation in action, simply undo the reverse engineering action in the project. We still have the AdventureWorks relational model data in the catalog. To switch LLBLGen Pro to see each group in the project as a separate project, open the Project Settings, navigate to General and set Group usage to AsSeparateProjects.
In the catalog explorer, select Person and Production, right-click them and select again Reverse engineer Tables to Entities.... Again check the checkbox at the top to mark all entities to be added and click Add to Project. We get two groups, as expected, however this time the groups are seen as separate projects. This means that the validation logic inside LLBLGen Pro will see it as an error if there's e.g. a relationship or an inheritance edge linking two groups together, as that would lead to a cyclic reference in the code bases.
To see this variant of the grouping feature, seeing the groups as separate projects, in action, we'll generate code from the project with the two groups we just created: select from the main menu: Project -> Generate Source-code... (or press F7 ;)). In the dialog popping up, select the target .NET framework you want to use, the template preset, fill in a destination folder and click Start Generator (normal). This will start the code generator process.
As expected the code generator has simply generated two code bases, one for Person and one for Production:
![sshot_[8]](https://aspblogs.blob.core.windows.net/media/fbouma/WindowsLiveWriter/LLBLGenProfeaturehighlightsgroupingmodel_ABCC/sshot_%255B8%255D_3.png)
The group name is used inside the namespace for the different elements. This allows you to add both code bases to a single solution and use them together in a different project without problems. Below is a snippet from the code file of a generated entity class.
//...
using System.Xml.Serialization;
using AdventureWorks.Person;
using AdventureWorks.Person.HelperClasses;
using AdventureWorks.Person.FactoryClasses;
using AdventureWorks.Person.RelationClasses;
using SD.LLBLGen.Pro.ORMSupportClasses;
namespace AdventureWorks.Person.EntityClasses
{
//...
/// <summary>Entity class which represents the entity 'Address'.<br/><br/></summary>
[Serializable]
public partial class AddressEntity : CommonEntityBase
//...
The advantage of this is that you can have two code bases and work with them separately, yet have a single target database and maintain everything in a single location. If you decide to move to a single code base, you can do so with a change of one setting. It's also useful if you want to keep the groups as separate models (and code bases) yet want to add relationships to elements from another group using a copy of the entity: you can simply reverse engineer the target table to a new entity into a different group, effectively making a copy of the entity. As there's a single target database, changes made to that database are reflected in both models which makes maintenance easier than when you'd have a separate project for each group, with its own relational model data.
Conclusion
LLBLGen Pro offers a flexible way to work with entities in sub-models and control how the sub-models end up in the generated code.