Silverlight Crossdomain Access Workarounds
I was testing out some typography with Silverlight and figured I’d try grab some text from Wikipedia. I started with the naive approach:
private void GetText() { WebClient webClient = new WebClient(); webClient.DownloadStringCompleted += new DownloadStringCompletedEventHandler(webClient_DownloadStringCompleted); webClient.DownloadStringAsync(new Uri("http://en.wikipedia.org/wiki/george_washington/")); } void webClient_DownloadStringCompleted(object sender, DownloadStringCompletedEventArgs e) {
//This next line throws an exception string fullText = e.Result;
//Do some neat stuff... }
That throws a pretty ambiguous exception: 'e.Result' threw an exception of type 'System.Reflection.TargetInvocationException'. The InnerException just shows “Security Error.” The source of the Security Error is that Wikipedia doesn’t have a Crossdomain ( crossdomain.xml) policy file.
Best Case: Site supports crossdomain.xml or clientaccesspolicy.xml
A lot’s been written about the Site Of Origin policy for both browsers and RIA clients like Silverlight and Flash, so I won’t rehash them in too much detail. The idea is that, for security reasons, code running in a webpage (Javascript, Silverlight, or Flash) should generally only be able to access the domain that hosts the webpage. Silverlight followed Flash’s lead and allows for cross-domain calls if the site it’s accessing has a crossdomain.xml file which permits it. This doesn’t really protect against cross-site scripting (XSS) attacks, since – as Rick Strahl noted – any malicious site can post a crossdomain.xml file (e.g. http://evilsite.com/crossdomain.xml) and RIA’s will then be allowed to pass information home. Rather, this is a safeguard against cross-site request forgery (XSRF) attacks. I think Steve Sanderson’s comment sums this up pretty well:
What you're missing is the CRSF scenario. Current browsers prohibit me, from www.pirate.com, using script to cause a GET or POST request to www.bank.com and actually reading the response data back in my script that I host onwww.pirate.com. This is important because requests sent to www.bank.com will include the cookies for that domain and may therefore be treated as authenticated requests, for which the server will return sensitive information. You don't want that sensitive information to be retrievable by the script running in www.pirate.com.
This […] allows cross-domain requests to read data across domains *only* if the target domain opts-in on a *per-request* basis. Obviously, www.bank.com isn't going to opt in for any sensitive URLs, but it might choose to do so for some kind of non-sensitive API (stock quotes or whatever).
So, crossdomain protection means that I can use a potentially evil Silverlight application without worrying that it’s going to use my browser context to try to access my bank or e-mail or other trusted data, because my bank isn’t going to allow cross-domain access. So evilsite.com can “phone home” with any cookies it has access to, but it can’t use my authenticated status to make requests to my bank.
Tim Heuer has written several good posts on cross-domain issues. I especially recommend his crossdomain.xml helpers for Visual Studio if you need to write your own crossdomain.xml file to expose your own services.
The Silverlight Web Services Team blog has some good troubleshooting tips in case you’re having trouble connecting to a site which has a crossdomain.xml file, and you can use this simple Silverlight Cross Domain Policy File Checker to quickly check sites. My top recommendations:
- Make sure you’re not testing from a file:// URL, since websites running under file:// can’t make cross-domain calls. You need to test with an http:// page – for instance, using a test ASPX page running in the Visual Studio WebDev.exe test server.
- Browse to the crossdomain.xml file (e.g. http://twitter.com/crossdomain.xml) to make sure that it’s there.
- Test in Fiddler, Firebug, or the IE Web Developer Toolbar to watch network traffic and verify your Silverlight app is trying to connect to the right URL for crossdomain.xml.
- Build a very simple test Silverlight app which does nothing but make the cross-domain call.
Note: clientaccesspolicy.xml vs. crossdomain.xml
Silverlight supports a subset of Flash’s crossdomain.xml file format, but doesn’t allow for fine grained control. If you’re exposing your own services to Silverlight, you’ll want to look at clientaccesspolicy.xml; if you’re supporting Flash and Silverlight you should ideally have both. However, in this post I’m concentrating on accessing external resources, which at this point are more likely to have crossdomain.xml due to the fact that it works on Flash as well.
Second Best: JSON Requests
JSON requests get a free ride – they can connect to any any site, regardless of whether they have a crossdomain.xml file. That’s probably because JSON is just an object notation (name/value pairs and ordered lists), rather than direct script. While it can be used for evil (via the evil eval()), it’s more of a serialization format than a script. Regardless of the reasons, it’s allowed to cross domains when other calls can’t.
Joshua Allen recently wrote about making JSON requests from Silverlight. His method depends on some Javascript methods being included in the host webpage, but it’s possible to append the Javascript to your DOM from Silverlight if you’re writing an embeddable widget (say, for instance, for the MIX09 10K Challenge).
Read Joshua’s post for the full details, but the basic idea is that you have an injection script in your page, like this:
function injectScript(url) { var head = document.getElementsByTagName(‘head’)[0]; var script = document.createElement(’script’); script.type = ‘text/javascript’; script.src = url; head.appendChild(script); };
Then we invoke the injection script from our Silverlight application:
HtmlPage.Window.Invoke("injectScript", url);
The script source needs to point to a URL that returns JSON, and preferably wrapped in a callback function call, like this:
callback({"info": "important info here"}
Then (continuing to quote Joshua Allen’s example), the Javascript callback calls into a scriptable method in our Silverlight application:
function callback(obj) {
var silverlight = document.getElementById("silverlight");
if (silverlight) {
silverlight.Content.Page.PassData(JSON.stringify(obj));
}
};
Note 1: About that JSON object
The call to JSON.stringify() is natively supported in IE8, Firefox 3.1, and is slowly working its way into Webkit (Safari, Chrome). But it’s easy to add JSON for other browsers by using the parser distributed on json.org: http://www.json.org/json2.js
Note 2: About that Callback
By convention, most API’s that return JSON will take a parameter for the name of the callback function. For instance, here we’re telling the html-whitelist service to call mySuperFunction with the results:
Flickr defaults to jsonFlickrApi, but allows you to override the callback name with &jsoncallback=muSuperFunction
returns this (only showing the first image):
mySuperFunction({
"title": "Recent Uploads tagged silverlight",
"link": "http://www.flickr.com/photos/tags/silverlight/",
"description": "",
"modified": "2008-12-11T19:22:44Z",
"generator": "http://www.flickr.com/",
"items": [
{
"title": "NEC Biglobe album viewer",
"link": "http://www.flickr.com/photos/adamkinney/3100209567/",
"media": {"m":"http://farm4.static.flickr.com/3294/3100209567_43d738e294_m.jpg"},
"date_taken": "2008-12-11T11:22:44-08:00",
"description": "description here…",
"published": "2008-12-11T19:22:44Z",
"author": "nobody@flickr.com (adKinn)",
"author_id": "83775906@N00",
"tags": "album silverlight deepzoom necbiglobe"
}
]
})
Note 3: What to do with that JSON data?
In this sample I’m just passing the JSON data back to my Silverlight application as a string. You’re not on your own dealing with parsing that string, though – the System.Runtime.Serialization.Json namespace can handle that for you. Corey Schuman’s written a nice walkthrough on how to consume a JSON object in Silverlight.
No JSON? Don’t waste your time on IFRAME / JSONP hacks
I spent some time looking into ways to pull data from a URL that doesn’t supply data in JSON format. My conclusion is that it’s a bad idea. While you may be able to sneak something by an older browser, you’re essentially hacking at this point, and newer browsers will block it.
For instance, let’s try to create an IFRAME and load the content:
public Page() { InitializeComponent(); HtmlPage.RegisterScriptableObject("Page", this); iframe = HtmlPage.Document.CreateElement("iframe"); iframe.Id = "invisibleIframe"; iframe.SetProperty("src", url); iframe.SetStyleAttribute("display", "none"); iframe.SetAttribute("onload", "contentLoaded"); // call a function which calls silverlight.Content.Page.Loaded() HtmlElement body = (HtmlElement)HtmlPage.Document.GetElementsByTagName("body")[0]; body.AppendChild(iframe); } [ScriptableMember] public void Loaded() { HtmlWindow content = (HtmlWindow)iframe.GetProperty("contentWindow"); HtmlElement doc = (HtmlElement)content.GetProperty("document"); HtmlElement body = (HtmlElement)doc.GetProperty("body"); string innerHTML = (string)body.GetProperty("innerHTML"); Output.Text = innerHTML; }
While that will cause an IFRAME to be created and load the document, the IFRAME content isn’t accessible to Silverlight (or to Javascript functions running in the page, for that matter). Makes sense, the Single Origin Policy is being enforced.
Also a no-go: using the JSON approach on a URL that’s not returning JSON. Two problems:
- Script tags with an external source are evaluated when loaded, and if they’re not valid Javascript you’ll get an error message. For example:
<script src=”http://google.com></script>
will try to execute the HTML code of the Google home page as HTML and will throw Javascript errors (depending on the user’s browser settings). - We won’t be able to access the content that the script tag contains from Silverlight or Javascript – it’s blocked by the the Site Of Origin policy.
Are there ways to hack around this? Probably. But, I’m convinced that it’s a losing battle – if you get it to work, you’re taking advantage of a bug. Browsers are enforcing a rule, and if you find a way around the rule, you should expect that it’ll stop working at some point, or won’t work on all the browsers you want to support.
Crossdomain.xml and JSON Friendly Proxies
So, what do you do if you want access to a web resource, but the site doesn’t provide a crossdomain.xml policy or expose data in JSON format?
The answer is to use a proxy who does allow access. You can write your own, of course. I wrote some posts about that back in the Silverlight 1.1 days, but of course that showoff Tim Heuer’s gone and upstaged me with a super-nice post on how to call Amazon S3 Services from Silverlight 2 with a custom webservice proxy. And to add insult to injury, he topped it off with another post on reading data and RSS with Silverlight and no cross-domain policy. He points out Yahoo Pipes, which is a workable solution for many cases, with some important caveats:
Note on usage: The module will only fetch HTML pages under 200k and the page must also be indexable (I.E. allowed by the site's robots.txt file.) If you do not want your page made available to this module, please add it to your robots.txt file, or add the following tag into the page's <head> element:
<META NAME="ROBOTS" CONTENT="NOINDEX">
For example, I created a simple pipe which grabs the HTML from a page and returns it in any of the formats Pipes supports (including JSON):
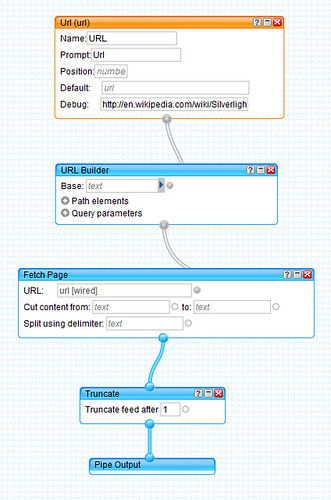
So, we can use it to scrape the HTML from the Silverlight page on Wikipedia and get access to the HTML content from our Silverlight application like this:
That Pipe is published and is freely accessible, so you can either use it or clone it for your own use if you’d like. So if you’re after HTML content, that approach works provided the page is indexable and is <200KB. If not, you can see if the content’s in the Wayback Machine, since archive.org has a crossdomain policy file. To get the latest version of a page from the Wayback Machine, just use this format: http://web.archive.org/URL, e.g. http://web.archive.org/http://microsoft.com. They don’t provide the content in JSON format, but you can get it via a WebClient request.
If you want access to data that’s got an RSS feed, you’ve got a lot more options. Feedburner supports crossdomain, and there are piles of Feed To JSON pipes on Yahoo Pipes, such as jsonifier. For instance, StackOverflow doesn’t (yet) support crossdomain access, but we can get a JSON feed of questions tagged with Silverlight (http://stackoverflow.com/feeds/tag/silverlight) with that jsonifier pipe:
and if we wanted it in XML format, we could just change the _render action:
Calls To Action
- Lobby sites which provide external data to support crossdomain.xml. Be sure to let them know that it will enable both Flash and Silverlight to access their data.
- I’ve started a community wiki at Stack Overflow to list sites which do support crossdomain.xml. Please add to the list if you know of some I missed.
- Write some cool mashups!
Epilogue
Oh, and wikipedia? The thing that got me started on this quest? It turns out that they do have an API that returns JSON.