OpenXML to parse your office documents
ECMA OpenXml is a recognized open standard for saving and retrieving office documents that enables cross-platform document porting and sharing. The Office 2007 uses this format for its data persistence for word, excel and power point lineups. There is a OpenXml SDK CTP available for it to download from MSDN, which lets you create your own office component that works on universal format.
Now, using OpenXml SDK creating office components is easier than before, also it promises to bring you cross product and platform flavor.
OpenXml document generally looks like
<w:document w:xmlns="http://schemas.openxmlformats.org/wordprocessingml/2006/main"> <w:body> <w:p> // items goes here </w:p> </w:body> </w:document>
<w:p> wraps up every paragraph and below it goes all the style elements and text nodes. Now, the reason why I mentioned this OpenXml here is LINQ. In a moment, I will show how it is possible to create an easy word document parser using the OpenXml SDK and a bit LINQ.
Now starting , you have to add the following reference to your project.
This Dll comes a part of the OpenXml SDK , you can either copy it to your project or ref it from where it is installed, it is not installed in GAC. So, I supplied it with the download provided with this post as well.
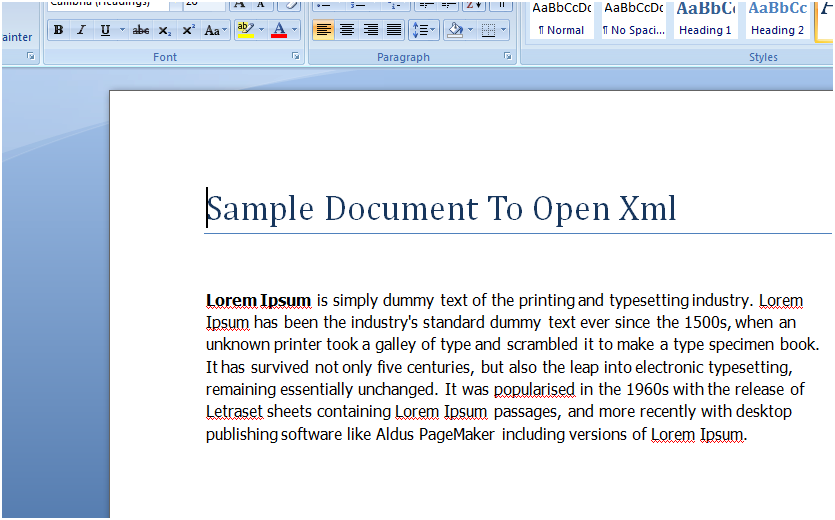
This is the sample document that we will be parsing using LINQ and OpenXml SDK.The main thing to do so, is to create the processing document, which takes a file path / stream and a bool value named readWriteMode, true means both way.
using (WordprocessingDocument doc = WordprocessingDocument.Open(_path, true)) { MainDocumentPart mPart = doc.MainDocumentPart; using (StreamReader reader = new StreamReader(mPart.GetStream())) { } }
Now, the starting node for the processing doc is MainDocumentPart, which is divided up into several OpenXmlPart derived objects (base of all the document parts), we can work with the whole document or with smaller parts basis on our data need. Anyway, next and the only thing is to get around a stream for the XML doc and process it with LINQToXML.
XDocument xDocument = XDocument.Load(XmlReader.Create(reader));
So , the step is to use XmlReader.Create to get a clean XML and then pass it to XDocument , as there are special characters in the stream, which the XDocument cant process directly.
We also need to create XNameSpace and XName elements, which will be used to query the document for what we are looking.
XNamespace w = "http://schemas.openxmlformats.org/wordprocessingml/2006/main"; // the elements we will be looking for data. XName rPr = w + "pPr"; XName p = w + "p";
Finally, its all LINQ to get the list of text blocks and styles attached to them , in case of this document there are three blocks (1. Title 2. br 3. Text). The parsing and fill up looks like the following, here a lot of null checks are used to avoid pitfalls , as the nodes are not consistent all the way down.
var query = from element in xDocument.Descendants(p) select new Document { ItemProperty = element.Element(rPr) != null ? ((from sElement in element.Descendants(rPr) select new ItemProperty { Style = sElement.IsEmpty == false ? (sElement.Element(w + "pStyle") != null ? sElement.Element(w + "pStyle").Attribute(w + "val").Value : string.Empty) : string.Empty, Lang = sElement.IsEmpty == false ? (sElement.Element(w + "lang") != null ? (sElement.Element(w + "lang").Value ?? string.Empty) : string.Empty) : string.Empty }).First<ItemProperty>()) : null, Text = element.Value == string.Empty ? "<br/>" : element.Value }; return query.ToList<Document>();
In the code, Document is the custom class that looks like
public class ItemProperty { public string Style { get; set; } public string Lang { get; set; } } public class Document { public string Text { get; set; } private ItemProperty _itemProperty = new ItemProperty(); public ItemProperty ItemProperty { get; set; } }
That's it , we got the document in the memory , now either we can print it in console or make our custom viewer to show it, but for the time being I will print the lines on console :-)
// the function whose code is shown above IList<Document> list = GetParagraphs(); foreach (Document doc in list) { Console.WriteLine(doc.ItemProperty.Style + ":" + doc.Text); }
Download the full source here
Have Fun!!
