Adventures in F# - F# 101 Part 6 (Lazy Evaluation)
Where We Are
Before we begin today, let's catch up to where we are today:
- Part 1 - Basic functional programming
- Part 2 - Currying and Tuples
- Part 3 - Scope, Recursion and Anonymous Functions
- Part 4 - History of F#, Operators and Lists
- Part 5 - Pattern Matching
Lazy Evaluation
Another fascinating topic in the land of functional programming is lazy evaluation. This technique is basically delaying the execution of a given code block until it is needed. Imagine for a minute that you have a function that is basically an if-else function. This function would take a boolean condition, and if false, it will execute the second block of code. The last thing you'd want to do is evaluate the else statement if the if is true and the results could be disastrous. Instead, we can delay that result until we ultimately need it. But why is it useful? Well, think of infinite calculations, or infinite loops, the last thing you want to do is evaluate all of them, and instead do it lazily on command.
It's one of the more important features in languages such as Haskell where Simon Peyton Jones, the principal designer of the Glasgow Haskell Compiler (GHC), really likes this features and talks about it extensively on DotNetRocks Episode 310. By default, all function parameters computation are delayed by default. If you'd like to see more about Haskell's lazy evaluation of a Fibonacci sequence, check it out on the HaskellWiki.
Back to F# now. When we talk about a pure functional language, the compiler should be free to choose which order to evaluate the argument expressions. Instead, F# does allow for side effects in this way, such as printing to the console, writing to a file, etc, so being able to hold off on those kinds of items just aren't possible. F# by default does not perform lazy evaluation, instead has what is called eager evaluation. To take advantage of lazy loading, use the lazy keyword in the creation of your function and wrap the area to be lazy evaluated inside that block. You then use the Lazy.force function to evaluate the expression. Once that is called for the first time, the results is then cached for any subsequent call. Let's walk through a quick sample of how that works:
#light
let lazyMultiply =
lazy
(
let multiply = 4 * 4
print_string "This is a side effect"
multiply
)
let forcedMultiply1 = Lazy.force lazyMultiply
let forcedMultiply2 = Lazy.force lazyMultiply
What you'll notice from the above sample is that I intentionally put a side effect inside my lazy evaluated code. But, since the evaluation only happens once, then I should only see it in my console once, and sure enough, when you run it, it does. This is called memoization, which is a form of caching. This uses the Microsoft.FSharp.Control.Lazy class. But, I wonder how it's actually done through the magic of IL. Since I think C# is a little bit more readable, let's crack open .NET Reflector and take a look.
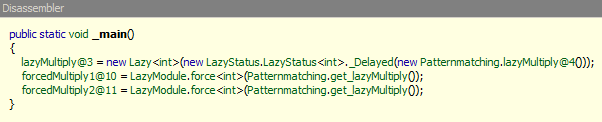
What we notice is that it creates a new class for us called lazyMultiply. There is a lot of syntactic sugar behind the scenes, but as you can see, it's calling the same get_lazyMultiply function off my main class. It's nothing more than a simple property that does this:
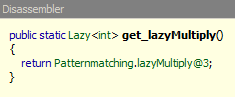
If you'd like to dig more into the guts of how that works exactly, check out Jomo Fisher's blog post about the Lazy Keyword here. I'm definitely glad to see F# team members blogging about these sorts of things.
Lazy Collections?
F# also has the notion of lazy collections. What this means is that you can calculate the items in your collection upon demand. Some of the collections inside the F# library may also cache those results as well. We have two types that we're interested in, the LazyList class (full name: Microsoft.FSharp.Compatibility.FSharp.LazyList in FSharp.Compatibility.dll) and the Seq class (full name: Microsoft.FSharp.Collections.Seq in FSharp.Core.dll).
The LazyList is a list which caches the results of the computed results on the items inside the collection. In order to create a truly lazy list, you must use the unfold function. What this does is returns a list of values in a sequence starting with the given seed. The computation itself isn't computed until the first one is accessed. The rest of the elements are calculated by the residual and I'll show you that below:
#light
let sequence = LazyList.unfold (fun x -> Some(x , x + 1)) 1
let first20 = LazyList.take 20 sequence
print_any first20
What the above sample allows us to do is create a list of infinite numbers, starting at the seed of 1. But, the values aren't computed until the first is accessed, and then the results are cached. But, in order to access any value out of them, you need to take x number of values from them. The LazyList provides that capability to do that with the take function. What you'll also notice is that we can use the None or Some functions. The Some function, as shown above has its first value as the starting value, and the second value is what it will be like the next time it will be called. The None function, not shown above, represents the end of the list.
You may also use the Seq class to represent these lazy values. Think of the Seq as the magic collection class inside F# as it compatible with most, if not all arrays, and most collections as well.
But, what does that code look like as well? Very interesting question. Let's take a look at the main function first:
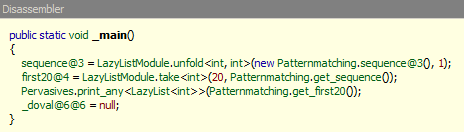
Ok, so that looks a bit interesting. So, what does the sequence@3 really look like. What we see is that we're giving it a seed of 1 and then getting the first 20 from the list. Let's now take a look at the sequence@3. What's we're interesting in is not the actual constructor, but the Invoke method as you remember, it's a lazy list.
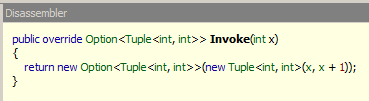
So, as you can see, it sure enough looks like we had in our code from above with a heck of a lot more angle brackets. I'm sure that's why some of the var stuff was introduced in C# 3.0 was to hide this ugliness.
Conclusion
Just to wrap things up here on a Friday, I hope you enjoyed looking at some of the possibilities of lazy loading. This could also help with Abstract Syntax Trees, loading of data from files, XML documents, etc. The real power is to take infinite data loops and take chunks of them at a time. And we really don't have to worry about the stack as well when we do this. I hope you've enjoyed the series so far and there are a few more things I'd want to cover before I consider this series done. Until next time...
