Archives
-
Of edges and vertices - another stab at reaching a more systematic view of software
I keep hearing, services (as in SOA) are about edges. If that´s the case, what are these edges connecting? There are no edges without vertices.
-
Building an associative (data)base - or: The Pile thinking applied
Ok, finally - after another digression on Pile fundamentals (and I guess, more needs to be said, but not right now) - I´ll quickly describe my prototype implementation of a Pile engine as well as a Pile agent/client to use it for searching in plain text files.
-
Folding the informational space - or: How Pile lets you transcend hierarchies of data
After some philosophical digressions now on to "More matter, less art" as Hamlet´s mother says. Lets step up the ladder of abstraction and look at how to put the elementary particle, those associations, to some tangible use. How about implementing a little full text search application? That´s what I did to check my understanding of Pile. Although there exists such an application at pileworks.org, I thought it would help me more to try to build it myself instead of just studying existing code.
-
Data is just an abstraction of associations - or: A philosophical interlude
In my previouse posting I´ve described the Pile view of the "world of data": focus on associations, not data. Todays I wanted to put meat on this theoretical skelleton and show you code I wrote. But first let me insert a little philosophical deviation. It might help to distinguish Pile from other (more or less novel) approaches to "data management" - and either draw more fire from the RDBMS camp or drive them off altogether :-) We´ll see...
-
Beyond WinFS - Let associations rule! - or: An introduction to Pile for mere mortals
Yesterday I wrote about why I think WinFS is a step forward - but in the end will not really solve the problem of the penned up data. WinFS´ data units (the objects, e.g. contacts, appointments and what not) simply are still too coarse grained. And even though WinFS puts relations between data units (or entities) more into the center of the stage, it is still bound by the general world view of "data is most important". However, as long as data is in the focus, associations between data are second. And as long as associations are second, we´ll have a hard time to map the multi contextuality of real world entities to software.
-
Musings on relations - or: WinFS is not enough
Have you had a look at WinFS? No, you should. It´s cool. Or maybe I should say: It could be even more cool, if it didn´t stop too early.
-
Gute Laune durch 'Computerbücher ins Altpapier'
Es ist so angenehm und doch so selten, dass ich auf einen Text im Web stoße, der mir einfach so spontan gute Laune macht. Aber jetzt ist es doch wieder passiert. Peter Braun hat seinem Unmut über den Zustand der Computer-Fachliteratur in einem Kolumnenbeitrag mit dem Titel 'Computerbücher ins Altpapier' im Dr. Web Magazin Luft gemacht. Und das ebenso direkt wie herzerfrischend.
-
Drei Herren mit guter Laune
Warum haben diese drei Herren so gute Laune? Hm... Sie stoßen auf etwas an, aber was...?
-
Storing Relations revisted - The hanging trees of Pile
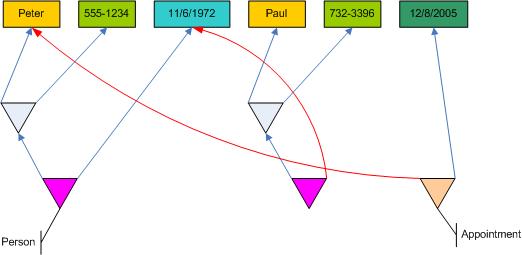
-
Storing Relations Instead of Data - Just a cool idea or a revolutionary new data storage paradigm?
Well, this idea of storing relations instead of data sounded very interesting - even though I did not fully understand it. And I guess, I still do not fully understand it - but Peter Krieg got me hooked. I´m always open for unusual cool new ideas, and this seems to be one. Later that day he did a keynote titled "When Powerpoint meets Doom" where he tried to explain the idea to a larger audience. Reactions where mixed, but I immediately ran out to get his book "Die paranoide Maschine - Computer zwischen Wahn und Sinn". (Sorry, this book is only available in German; but nevertheless I can recommend it for his quite refreshing view on what computers are and how they need to change, if we want them to become more "intelligent".)
-
Defining Components - A pragmatic look at software building blocks
Yesterday I argued, we´re really living in the decade of the component - and not in the good old objects or service hype days. Also I sketched out what I think is necessary to arrive at true software building blocks as the next higher level of abstraction above objects/classes: Contract First Design (CFD) and Microkernel based architecture.
-
The Decade of the Component - Service orientation is just the beginning
I guess, before I start my day, I need to get this out of my system: You know what´s happening right now? It´s the decade of the component! The 1970/80ies were the decade of structured programming, the 1990ies were the decade of object orientation - and now we´re right in the middle of the decade of component orientation.
-
The discourses go on: Ingo Rammer and I talk about designing interfaces between services
Listening to a discussion often offers a new view on a subject, because hearing contrasting thoughts next to each other sparks your own thoughts in a different way than reading a just an article explaining some subject. That´s why thinktecture now publishes its second email discourse on an software architectural topic.