Is there life beyond WCF? - or: Communication always is about shared data structures
While pondering about how to get a grip on software architecture, I now and again of course stumble upon questions on communication between distributed software parts. WCF then springs up as the state-of-the-art technology to answer those questions. But more and more I´m asking myself: Is WCF all there is we need to know about communication in distributed software? Is it the holy grail with its beautiful abstraction over SOAP, WSDL, COM+, HTTP, MSMQ etc.?
The longer I´m thinking about this, the more I´d say, no WCF is not the end, it´s hardly the beginning. WCF is the foundation for technologies to come which will make it truely easy to communicate in distributed software systems. WCF is (just) a wrapper around many basic intricacies of message based communication. It hides the ugly details of a communication model that´s very different from local method calls. In that it will make communication as much easier as sockets made it easier compared to lower level APIs in the OSI stack of communication layers.
WCF thus is a necessary and overdue unification and abstraction. But despite all its features WCF still is in the tradition of basic socket communication. WCF is about FIFO and streams of bytes flowing from here to there and maybe back.
And this made me think. What´s communication in software about anyway?
Communication always is about a data structure. And thus communication is not different from code, meaning: there is only code and no communication. Or to put it differently: Bits flowing back and forth (mostly) can be neglected from an application programmer´s point of view; what is important, though, is the code and the data structure it implements. Also, what´s important is where the control over a the data structure is at each point in time.
Let me illustrate what I mean:
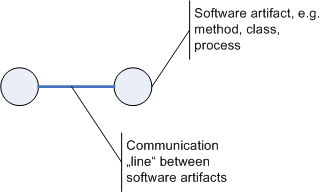
Often our software diagrams contain to different kinds of "entities": software artifacts and communication "lines". We´re describing software using graphs. Code is depicted as vertices, communication is depicted as edges. That´s great and easy to understand.
But my feeling is, this becomes a problems once you forget, that communication does not come for free. And also I find this depiction limiting, since it lures you into thinking, communication always goes through some kind of pipe. Because what the above picture suggests is something like this:

There are hard working software artifacts at two ends of a pipeline. The pipeline is just some kind of channel to let data flow between the "data factories".
Spaces instead of edges
Well, that´s a nice analogy that appropriate very often. But unless you´re aware it´s just an analogy and because of that probably only one of many possible analogies, it´s also a limiting view of software interaction.
Hence let me change the software diagram to show how software communication really works:
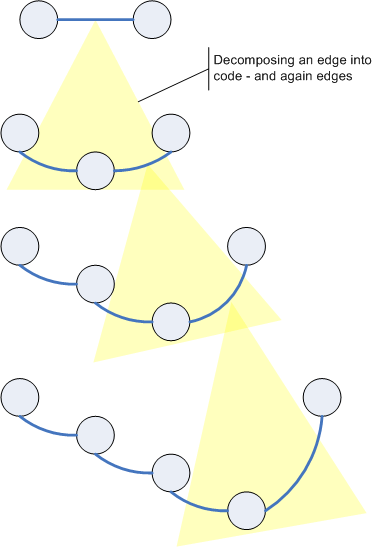
Between the communicating parties there is no direct connection. If you like, you can think of this connection being a hardware cable or a RAM chip. That´s fine - but pretty irrelevant from an application programmer´s point of view. Rather communication always manifests itself in another piece of code. So an edge can be represented as a piece of code sitting between the originally connected software artifacts. Of course this edge-code then is again connected with those software artifacts by edges - which in turn can be represented as a piece of code etc.
Since edges don´t seem to go away in the above picture, let me use another depiction to make clear, what I mean:
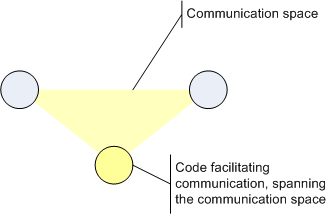
See, there are no edges anymore. Instead of an edge there is a space where communication takes place. And this space is spanned by some special communication code.
Today´s communication structures
Now, what does this code facilitating communication do? I like to call it a communication structure or even a coordination structure. This code always implements some kind of data structure sitting between the communicating parties. The purpose of its data structure is to enable communication and not permanently storing data. It helps the coordination of the cooperation of code accessing it.
Sometime code accesses this coordination structure sequentially, sometimes code accesses it in parallel. (The latter case is the more interesting one ;-)
You might now ask, "But where is the data structure when calling methods?" And the answer is: It´s the stack. And the whole purpose of the method call and method definition syntax is to hide the stack (or any other data structure, like registers) from you. Local communication (within the same address space) usually uses the stack which is invisible - but nevertheless present:
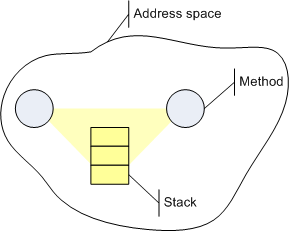
The compiler generates the code to put the actual parameters on the stack, transfer control to the called code, and later on clear the stack. Back in the good ole times when we all were still programming assembler we were aware of this all the time. We had to think hard about whether to pass parameters on the stack or in registers. The communication structure so to speak always was on our mind. Then came higher level languages and we don´t want and need to see it anymore. Great!
Enter distributed computing! The communication structure between software parts running in parallel or not living in the same address space is not the stack. Instead we´re talking about message orientation, since communication mostly uses streams to pass bytes to and fro. However, RPC and Web services made this fundamental change in the basic communication structure transparent for application programmers. It´s well know how contraproductive this abstraction in many cases was.
But today with WCF this has changed. WCF is not trying tell you, communication between distributed parts of a software system is like calling code locally. Rather, the WCF message is messages. WCF acknowledges the fundamental difference between a stack and a stream and encourages to adapt your thinking.
The WCF message is: Be aware of the channel! Because a channel it is, through which communication flows between distributed software parts:
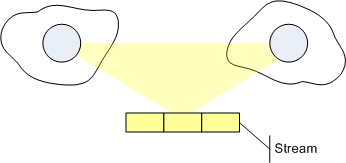
A stack is a LIFO data structure. A channel is a FIFO data structure. This difference alone should make it obvious how different communication in distributed software is from local method calls.
Nevertheless, code using WCF to communicate can pretty much look like code communicating via the stack. Why is that? Because a LIFO and a FIFO have well defined "input and output points". Both are not random access, but impose strict rules. Both say: data can only go in here, and data can leave only over there. The single entry and exit to the data structure makes it possible (and pretty intuitive) to model interaction with it using method calls:
int r = DoSomething(a, b);
This can mean "Push a and b on the stack, later pop the result off the stack and put it into r." or it could mean "Enque a, enque b, wait for a response on another queue and put it into r."
At the receiving side the code of DoSomething() can pop the actual parameters off the stack or dequeue them. The code can either be explicitly called to do this or can already run in parallel and wait. In any case, since there is only one place to look for the data (top of stack or head of queue) it can be modelled like an ordinary method receiving its input via parameters.
Tomorrow´s communication structures
Now, here comes the 10,000 dollar question: Is this all that´s to communication in distributed systems?
The answer is yes, if you look at current and widely established technology. Code is just using either the stack or a stream/queue to communicate and is happy doing so. Or not? The more I think about it, the more I lean towards no as an answer.
Stack and queue are just the only communication structures we have. So they are our only hammers - and thus every communication problem looks like a nail. Our thinking is constrained by these to (pre)dominant communication structures.
But if we´d take a look from 30,000 feet we´d see, they are just two very common, but nevertheless special cases of communication structures. Think of the possibilities you had, if you were not limited in your choice of communication structures. Think how intuitive cooperation between distributed software parts could be modeled, if you could use not only LIFO and FIFO data structures, but lists, trees, arrays, sets, dictionaries and what not!
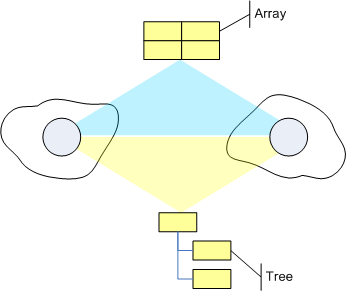
And if you like, you can still use a queue in distributed apps. But then you´d always be aware that you have a choice! (Actually you could even use a stack even in distributed solutions ;-)
Today you have the choice between passing information between local cooperating pieces of your code via stack or global variables. The general rule is to avoid globals variables and use the stack instead because this fosters decoupling. But sometimes global variables are easier and even necessary. Think about how to pass data into another thread. This can only (!) be done using global data structures. (Let´s leave aside the state parameter on ThreadPool.QueueUserWorkItem(). It´s also just hiding a communication structure.)
Virtual Shared Memory
Using global data structures sometimes even today is necessary for communication. And more choices for communication structures sure are a good thing. I guess you agree here; but you might say, "Well, what´s the point? I can use a global tree or use parameters to get data into a method I call."
My point is: We have and require this flexibility for local code, code running in the same address space. But we lack this flexibility in distributed systems!
For local code it´s implicit stack and explicit queue, stack, tree, list, array, set, dictionary etc.
For remote code it´s implicit stream.
That´s it.
I´d say: a poor choice of programming models this is for communication in distributed systems.
Especially if you consider there are solutions available since long. Tuple Space and Virtual Shared Memory (VSM) implementations are available since the 1980s. But they never really made it onto the Windows/.NET platform. JavaSpaces on the other hand is part of the J2EE platform. Why haven´t we really heard about TSpaces, Linda, Ruple, or Corso? Why have the successes of VSM on Apollo workstations been forgotten?
I don´t know. I really don´t know. But lately I´ve played with Corso for which a .NET binding exists. And I can tell you: it was great fun. Communication in distributed apps suddenly felt much easier. I even did not mind using a queue explicitly - because I felt I had a choice to change the communication structure at any time.
So what I´m looking for is a renaissance of VSM on Windows. And I´ll try to help it come about. I´m convinced, more choices are better than less.
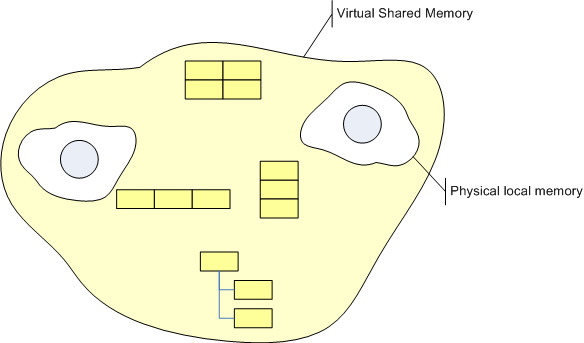
Having a ubiquitous VSM platform available would make programming in the small (local) and programming in the large (distributed) much more symmetrical. And if you´re in doubt and say, "Hey, but then we´d no longer see the fundamental difference between stack and stream based communication, since there would be just data structures and objects!" I´d answer: No, not necessarily. Like today you can hide a queue behind a method call. Or, on the other hand, yes, sure, and: that´s even the point about VSM!
The bad thing about object orientation in distributed systems in the past was not the objects, but the illusion, method calls were still for free. Hiding the data structure of distributed communication was bad. But once the data structure is visible again, interaction with it is explicit. So you can actually know what you´re doing. And then of course such shared communication structures are transactional meaning, you don´t have to fear interacting with them will drive network traffic through the roof.
I´d say: Let´s give VSM a try and see how far beyond WCF it can take us. WCF will of course stay important as a fundamental unification of several current concepts and technologies. But that doesn´t mean we can´t move up the abstraction ladder a bit, or does it?