Coordination structures beat RPC - or: How to keep your mental health while working on distributed software
I received a couple of comments on my posting on how bad RPC can be for your mental health. Although the feedback was positive and agreed with my statements, some expressed concern as to what an alternative to RPC-syntax could be. I thus feel encouraged to elaborate on how I think any software developer can avoid damage to his/her mental health ;-)
If subroutine call syntax like
int r = Calc(a, b);
suggests, a service is guaranteed to be carried out immediately and synchronously by "someone you know intimately", then we should first clarify how situations might look, where this syntax is not appropriate. Let me phrase the following recommendation:
Don´t use subroutine call syntax, if
- a service will not be carried out immediately, or
- you don´t want to wait for the service to finish its work, or
- you don´t know the service agent intimately (including where it resides), or
- you have doubts the service is available right now at all.
In addition there is one more premise of subroutine calls: You pretty much know exactly what service you need. So whenever you don´t know (or don´t want to know) what service or services should work on a piece of information, then you should not try to use subroutine calls.
Ok, so what does that mean? To find out, we need to look at the two sides of a subroutine call, the caller and the callee, or client and service:
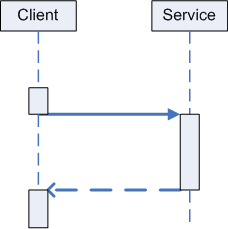
This is the usual case. Client and service know each other well and the usual "quality of service" (QoS) criteria are met; the service can fulfill the promise of direct subroutine call syntax.
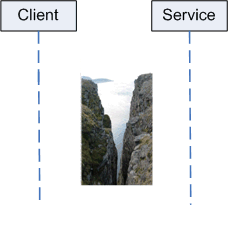
But this picture of harmony and easieness should change in your mind, once the QoS fulfillment is not guaranteed. Once communication between client and service is not stack based anymore, a chasm opens between caller and callee:
Trying to bridge this chasm using the same form (notation) for communication, I think, is plain wrong. Whether client and service are separated by a thread boundary, or an AppDomain boundary, or a process boundary does not matter. In any case there needs to be bridge across the chasm and this bridge should be obvious to anybody looking at the code.
Hiding the bridge and thereby suggesting "You can fully trust this subroutine service call. All´s well, it will fulfill its promise." would be (self-)deception. And being deceived sure is something nobody really likes.
As a solution I propose to always (!) - sorry, Ingo, for trying to set up a rule again ;-) - use an explicit bridge to cross the chasm or to make the bridge very clear that´s used under the hood of any RPC-style remote service invocation anyway:
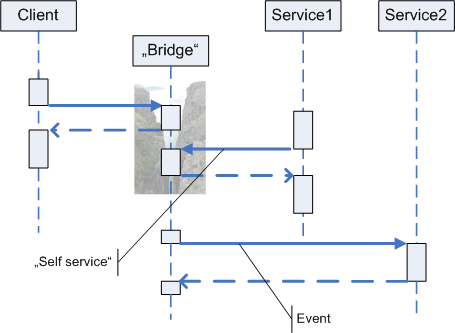
Using the term "bridge" here, does not mean, I´m talking about the Bridge design pattern. Right to the contrary: I don´t want to hide the chasm behind layers of abstraction. (Although the technical details of how the chasm is bridged are not important to client or service and should be hidden from them.)
Rather, if you like to think in patterns, I´m talking about some kind of Mediator, i.e. an entity that "encapsulates how a set of objects interact".
But I´d like to get more general. I´d like to call the "bridge" just a coordination structure. It´s some kind of code which helps to coordinate the work of client and service. Sometimes this coordination structure (or entity) is small, sometimes it´s a large piece of infrastructure. In any case it means an indirection in the communication between client and service and it represents some kind of data structure.
Now, how does a client change when a coordination structure is introduced or just made explicit? The client does not call the service directly anymore; instead it interacts with the coordination structure:
CalcRequest req = new CalcRequest(a, b);
calcCoordQueue.Enque(req, new CalcResponseHandlerDelegate(CalcResponseHandler));
...
void CalcResponseHandler(CalcResponse resp) { ... }
From this code, you can´t glean, where and when the service will be fulfilling the request. It might run on a different thread or on a different machine - or even in the same thread as the caller. You just don´t know. And that´s a good thing. It´s the prerequisite for a clean distribution of code.
It might sound so good, when .NET Remoting and Serviced Components and WCF tell you, "Hey, you can distribute your code transparently. A client does not need to see a difference between local and remote processing." But that´s the song of Ulysses´ sirens! Don´t let yourself be lured into thinking, you don´t need to take into account "how far apart" client and service will live in the end.
The contract between client and service who always will communicate locally needs to look different from a contract between client and service which only possibly might at some time in the future need to communicate remotely.
To make this distinction clear, I´m saying: Use ordinary subroutine calls to call local services. But always use indirect communication via a coordination structure whenever a service today or at some time in the future cannot be called directly. Make the boundary between a client and service easy to see in your code. This helps to build trust in you code. It makes it easier to maintain and evolve - even though it might mean, you need to write a little bit more code today.
So far I´ve been talking about the client side of a subroutine call. But what about the service side? What´s the promise of the subroutine definition syntax?
int Calc(int a, int b)
{
int result;
...
return result;
}
When writing such code you don´t think about whether the client waits for you to return a result or even if it is still alive at all. You just do whatever any service worker does: you fulfill the request as fast as possible. Whether you do that on your own thread or even on a different machine is of no concern to you. The only thing that´s for sure is, parameters come in on the stack and a result is returned via the stack. Who calls the service when, where the parameters come from, where the result goes to... all this the service does not know.
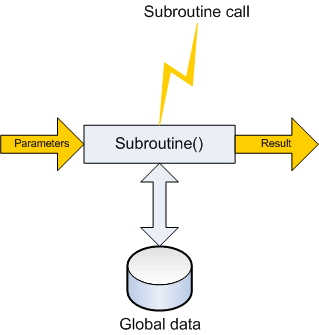
Hence I´d say: A subroutine is always an event handler. It has no control over when it´s called or who calls it, just like any button click event handler or a SQL Service Broker stored procedure.
What does that mean for receiving service requests? I´d say, it does not necessarily need to have an impact on how a service receives and handles requests. When implementing the service you don´t need to see a coordination structure, if a chasm needs to be bridged between you and your clients. Your service can pretty much look the same whether it´s called directly by a client or indirectly by a coordination structure. For the latter case, though, you need to register your service with the coordination structure. Your service then becomes a true event handler:
calcCoordQueue.RegisterRequestHandler(typeof(CalcRequest), new RequestHandlerDelegate(Calc));
...
CalcResponse Calc(CalcRequest req) { ... }
Instead of giving up control and waiting for events your service could be written to be "self servicing", i.e. interacting with the coordination structure directly to look for work.
void Calc()
{
while(true)
{
CalcRequest req = calcCoordQueue.Dequeue();
...
CalcResponse resp = ...
calcCoordQueue.Reply(req, resp);
}
}
For the usual FIFO service request, this might not be the most intuitive way to go. Fulfilling requests coming in on a queue is the canonical example for event-driven programming. But who says, coordination structures need to be FIFO-based? FIFO is still about military like orders: a client orders the fulfillment of a request - and the service better fulfills it as fast as possible.

But commands and orders are not the only way how results can be achieved. Since SOA values autonomy high, more peer like cooperation should enter how software parts deal with each other.
Clients and Service could be viewed as grouped around a common coordination structure, acting more like peers or servents than true clients and services. A coordination structure then would become a cooperation structure each peer accesses to get data to work on and insert results into.
So my bottom line is:
- In distributed software model communication between clients and services explicitly by using obvious coordination structures. It doesn´t make a difference whether client and service are running on different threads or on different machines. Also try to foresee future changes, stay flexible. If in doubt go for coordination structures.
- Use event-driven programming, i.e. implement services as event handlers whenever possible, especially in FIFO scenarios. It´s a way of decoupling the service from the coordination structure.
- If communication between clients and services becomes more complicated or at least cannot be modelled using the FIFO pattern switch to self-servicing services and let the access the coordination structure explicitly. If in doubt do so even if the coordination structure still is a FIFO.
If all this means waiving some convenience tools might be offering, I say: don´t bother. You´ll gain so much in code clarity and flexibility, you won´t miss this convenience much. And I promise you: there will be more technologies in the near future which will make it even easier to work with coordination or even cooperation structures on the .NET platform.