.NET naked - See these hitherto unpublished pictures of the .NET Framework architecture
Have you ever thought about the quality of your code? Well, I bet. Have you ever strived for a sound architecture of your software solutions? Well, I hope. Do you have a process in place to constantly monitor the quality of your software´s architecture and code? Well, you should. But not only should you. Every single software team should. Planning for quality and constant qualitiy monitoring should be the fundamental activities in any software project.
Sounds self-evident? Well, it does, but still it seems to be very, very hard for many software teams to implement such self-evidence. Why? There seem to be several reasons like a tradition to focus mainly on functionality/correctness and performance or a lack of formal education or a comparatively small number of tools.
So the quality situation still is pretty dire in the software industry despite all the discussions around pair programming, unit testing, patterns, refactoring, modelling approaches etc. But how can this be improved? Of course, more quality conciousness and better education helps. Easy to use tools, though, would help even more, because they would cater to constant lack of time of many programmers. They need to be so focused on churning out code that their time to look left and right to learn a new tool not helping them to code faster is very limited.
The xUnit family of tools is an example for such a quality improvement tool. The concept is easy to grasp, the tools integrate well into the IDE or at least into the development process, and quality checks are easy to set up. Great! But this helps only code correctness.
What, for example, about the structural qualities of a software? Refactoring tools like ReSharper are targeting this, but are working only on the architectural micro level of classes; plus they are not conerned with analysis. You have to smell necessary refactorings and then use the tool.
NDepend is another tool assessing software structure quality. But its output is hard to read and read-only.
Then there is Sotograph which might be the most comprehensive single tool to analyse even large software systems. I like it quite a bit, as my report on a recent workshop shows. However, I think it´s not really easy to use and still to expensive for many programming shops.
Dependency Structure Matrix
The other day, though, I stumbled over yet another software quality assessment tool: Lattix LDM. And what impressed me immediately was it´s easy to understand output based on the intuitive concept of the Dependency Structure Matrix (DSM).
Instead of trying to visualize complex systems (of classes or components) as a usual dependency graph like this:
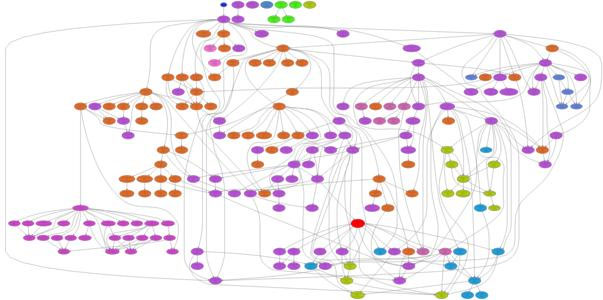
Fig. 1: Some Python classes
Lattix LDM shows them using a matrix, e.g.
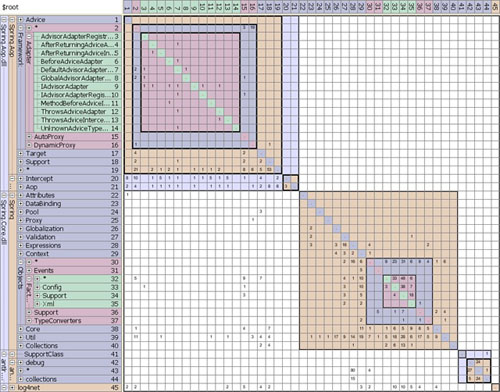
Fig. 2: The Spring.Net Framework
Isn´t that a much clearer picture? More structured? Who wants to follow all those lines in dependency graphs once the number of elements surpasses maybe 20 or 30? It becomes a maze!
If, yes, if a software has a decent structure, a dependency graph makes sense because artifacts can be arranged in groups and layers and dependencies are mostly unidirectional. But what if the macro and micro structure of a software is not decent - which is very likely for many software projects? Then a dependency graph becomes just a sophisticated wallpaper. Dependency graphs simply don´t scale.
DSMs on the other hand scale well. Take for example this view into the architecture of the .NET Framework:
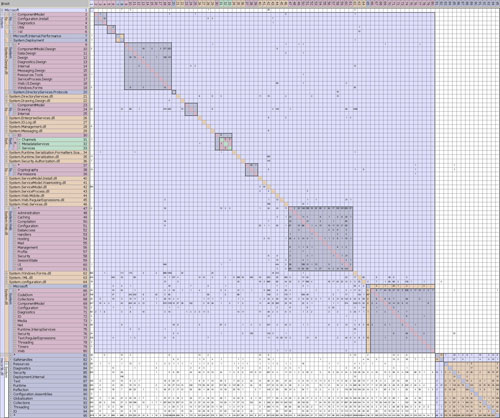
Fig. 3: A large scale overview of the .NET Framework Base Class Library
Within one minute after selecting the .NET Framework assemblies I was able to browse through the architecture of the base class library. Arrangement of assemblies in "layers" (or basic top-down dependencies) was done by Lattix LDM automatically - as far as possible.
That´s what impressed me about the Lattix tool: ease of use, quick results, simple concept (DSM). Although it´s still Java based, has comparatively slow GUI (due to Swing?) and does not have (at least on my Windows machine) the polished look I´d like for my tools, it was of immediate value for me.
A DSM view on software is merciless in its clarity. You don´t get mired in tedious layout work, but rather the tool strips naked the software you throw at it. You even see the bare bones of it, the dependency skelleton on any level you like. The physical level of assemblies and types comes for free within a couple of seconds. Even a rough layering can be established automatically. Beyond that you can group artifacts manually to arrive at a more conceptual view.
DSM patterns
Although I call a DSM view intuitive and clear, it needs a little explanation. So how does it work? There is some pretty introductory literature online, e.g. [1], but much more already describes various applications of DSM. Otherwise it seems, the basics are explained only in expensive books like [2]. Luckily, though, the manufacturers of Lattice LDM provide quite a good introduction to (their use of) DSMs themselves. Start here and then check out their white papers.
Right now let me just sketch the basic patterns to look out for:
Strict Layers
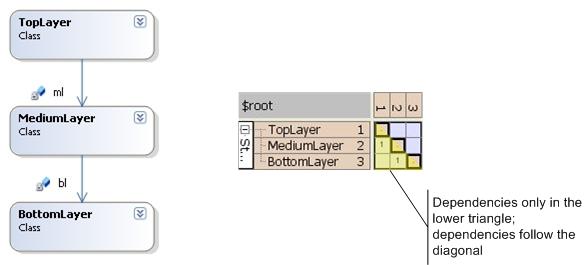
Fig. 4
The matrix shows all analyzed artifacts as rows and columns. At the intersection of a column with a row the strength of the dependency is noted.
In the DSM of Fig. 4 you can see how TopLayer is dependent on MediumLayer since column 1 (corresponding to row 1, TopLayer) has written a 1 in the cell where it intersects with row 2 (MediumLayer).
So reading a DSM in column-row order (col, row) means "depends on" or "uses", e.g. (1,2)=1 depends on 2, TopLayer uses MediumLayer.
Using (row, col) instead means "is used by", e.g. (2,1)=2 is used by 1, MediumLayer is used by TopLayer.
Layers
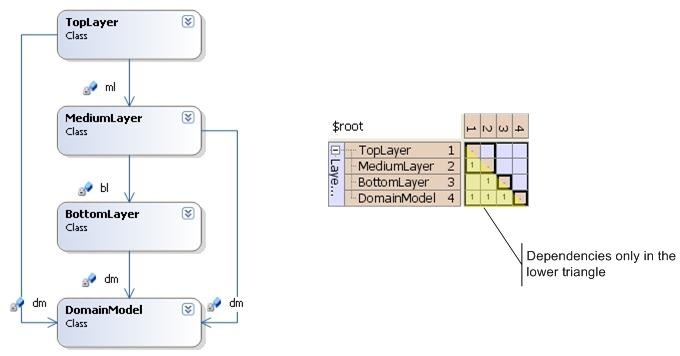
Fig. 5
If you give up strict layering and allow higher layers to depend on any lower layer, you still get a DSM where all dependencies are located below the main matrix diagonal. With this pattern in your mind look back at Fig. 2 above. I guess you immediately get an impression of the overall architectural quality of Spring.Net: It´s pretty neatly layered; most dependencies are located in the lower triangle of the DSM.
Fig. 4 so to speak shows the architectural ideal: a strictly layered system. Each artifact (be it classes or assemblies or conceptual groups) is only dependent on one other artifact layered below it. This leads to a very scarcely populated DSM where all dependencies are parallel to the main diagonal of the matrix. To get the same "feeling" by looking at a dependency graph would take you much longer, I´d say. Remember: I´m talking about a system you did not do the design for (or which has deviated much from you initial design). Also, in a larger dependency graph it´s hard to see in which direction the dependencies run. With a DSM, though, you just check, if a dependency is in the lower or upper triangle.
Local "components"
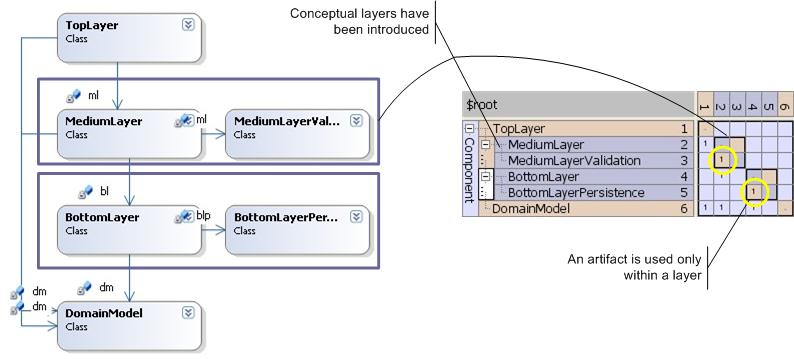
Fig. 6
Once you start to group artifacts into conceptual subsystems you probably want to know, how far they are "visible", how far reaching their dependencies are, whether they cross the subsystem boundaries. Fig. 6 shows a simple system with two subsystems and in the DSM you can see, that MediumLayerValidation and BottomLayerPersistence are used only within their respective subsystems: Any dependencies on them are located within their subsystem´s square. These artifacts are thus only of local relevance/visibility.
Cyclic dependencies
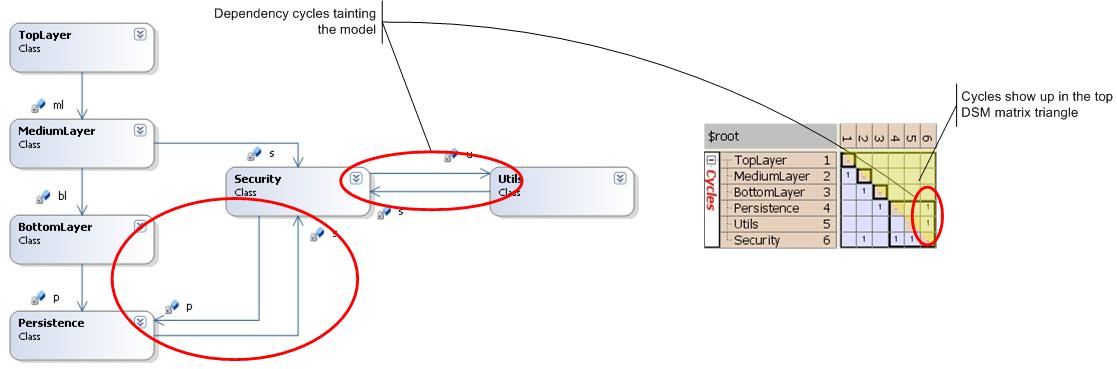
Fig. 7
The bane of all architectures are cyclic dependencies among artifacts. They increase the complexity of a software and make the build process difficult. Since long thus one of the basic software architectural principles is: Avoid cyclic dependencies, instead strive for a directed acyclic graph (DAG).
Since DAG is the goal it´s important to be able to quickly spot any violations of this principle. In dependency graphs of even modest complexity this is difficult. But with a DSM it´s easy. Look at Fig. 7: Cycles appear as dependencies above the diagonal. Reading in column-row manner we find: (5,6)=Utils depends on Security, but also Security depends on Utils (6,5).
Once you decide to arrange your artifacts in a certain order from top to bottom thereby suggesting a layering, any dependencies not following this direction from top to bottom show up in the top triangle. And if they don´t go away after rearranging the artifacts - e.g. by moving Utils below Security - you are truely stuck with a cycle.
Again look at Fig. 2 and zoom in on a part of the DSM showing a seemingly heavy cyclic dependency:

Fig. 8: Cyclic dependencies seem to exist within a part of Spring.Net
Almost all dependencies of within subsystem Spring.Objects.Factory are located above the diagonal. No good.
But we can rearrange the "layers" within the subsystem and arrive at a much nicer picture:
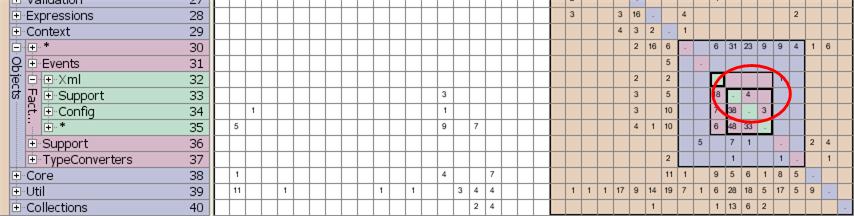
Fig. 9: By rearrangement of some artifacts almost all cyclic dependencies within the part in question of Spring.Net could be resolved
Almost all cycles are good. And the layering sounds ok: Xml is the top layer depending on all lower layers, * is the basic layer, the "catch-all" layer servicing the others.
However, some cycles are still present: Even though Support heavily relies on Config, Config in turn also depends on Support. If this is acceptable or not would now require closer examination. I´m not familiar enough with Spring.Net as to be able to assess, if such a cyclic dependency is tenable. But the DSM easily drew my attention to this area of pontial problems. Try this with a dependency graph of a system you don´t know intimately.
.NET naked
After these preliminary explanations let´s have a look at the .NET Framework. What´s it´s architectural quality? Will Microsoft tell you? No. So why not have a look for yourself? You probably have looked at the innards of the BCL yourself many times using Lutz Roeder´s Reflector. It´s an invaluable tool and belongs into your toolchest. But Reflector just shows you the (regenerated) "source code" of the BCL. It does not tell you anything about the overall quality of the architecture. With Lattix LDM, though, you can as easily assess the structural quality of the .NET Framework as you can assess its code quality using Reflector.
Look at Fig. 3 for example: It´s a very big picture of the .NET Framework. It shows the dependencies within and between the System.* DLLs and mscorlib.dll. The overall impression might be good. System.* DLLs seem to depend heavily on mscorlib.dll. Sounds reasonable, sounds like at least two layers. Great!
But then there are some glitches: Why does [mscorlib.dll]System.Security depend on [System.dll]System.Security? Or is it really necessary to use System.Configuration.dll from mscorlib.dll if mscorlib.dll is so basic? But that might be nitpicking. Much more questionable are the seemingly heavy cyclic dependencies within subsystems like mscorlib.dll and System.Web.dll:
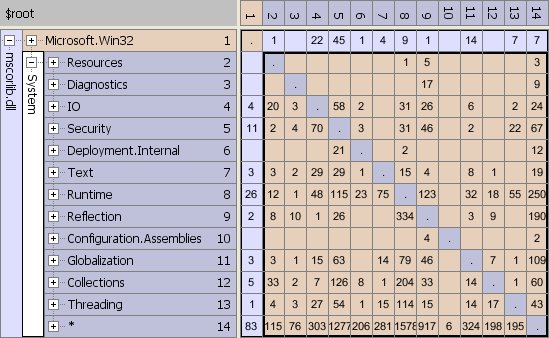
Fig. 10: Cyclic dependencies abound in the most fundamental library of the .NET Framework: mscorlib.dll
Fig. 10 shows so many dependencies in the upper triangle that it´s impossible to rearrange the subsystems to improve the situation much. mscorlib.dll simply contains many cyclic dependencies. The main culprits in this regard seem to be the subsystems/namespaces System.Runtime, System.Reflection and System. At the same time they provide many services to others and use many services of others.
The large dependency numbers for System (see row/column 14) thereby suggest, Microsoft used it as a kind of "catch all" namespace, a general bucket for all sorts of stuff. But although it´s perfectly ok to have such a bucket in your system - many give it a general name like "Util" or "Helpers" - it´s strange to see this bucket to be dependent on so much other stuff. Because what that means is: the bucket functions as a change propagator. No only changes can affect much of the system, because it´s used by many other parts of the system. But also changes to other parts of the system can affect it, because the bucket depends on them - and thereby indirectly can affect again other parts. That does not sound good, I´d say.
mscorlib.dll cannot really be thought of as a layered system. Is that good or bad? Of course as a whole mscorlib.dll is a layer itself in any .NET software because all your programs rely on its basic services. It´s at the bottom of all .NET software. So far so good. But then, if you zoom in, the layering is gone. One of the most basic architectural principles is violated not here and there but pretty pervasively throughout the whole thing. That smells - as in "code smells" - bad. That smells like programming in a hurry. That smells like many cooks working on the same broth.

Fig. 11: System.Web.dll after some rearrangement
The second cyclic dependency ridden subsystem of the BCL seemed to be System.Web.dll according to Fig. 3. Upon closer examination, though, the situation is not as bad as it first appeared. Fig. 11 shows a close-up of System.Web.dll after some rearrangement of its subsystems. Quite some layering could be established - but again there are two "change propagators": System.Web.Configuration and System.Web. System.Web, the namespace root, also again is the general bucket for all sorts of stuff.
I´m sure, each one of the cyclic dependencies at some point made some sense to someone. But looking from the outside it´s sometimes hard to think of justifications for, say, dependencies of basic utility functionality (13) on the UI (6) or compilation functionality (4) on the UI as well as the other way around or cycles between compilation and configuration (14). Why has System.Web.dll not been structured in a cleaner way?
It kind of makes me shudder a bit to see the inner structure of such fundamental building blocks of all our software to be in this state. With all of Microsoft´s preaching about solution architecture, its promotion of multi-layer architectures it´s sad to see so many basic violations of these principles.
As a counter example look at another non-trivial system: the VistaDB database engine. It´s a full blown relational database engine/server written entirely in managed code and coming as a single 600 KB assembly. It consists of two large subsystems: the internal engine whose code got obfuscated and the public API. Fig. 12 shows the internal engine from 100,000 feet. It´s made up of some 400 classes, but the DSM shows, their dependencies are almost all below the diagonal (only visible as "shadows" in the pictures). VistaDB thus internally is nicely layered.

Fig. 12: Large scale view of the internal engine of VistaDB
When zooming in on the public part of VistaDB, the feeling of attention to architecture remains. Fig. 13 shows the API to nicely layered as well. The few lonely cyclic dependencies are neglible.

Fig. 13: The public API of VistaDB
Publishing software quality reports
There´s much talk on how the security of software systems can benefit from public reviews. This might work for some systems, and not for some others. I don´t know. But regardless what way is best to find security bugs I think the most import aspect of this discussion is publicly talking about software quality. In many other industries product quality (and I don´t mean functional correctness) is a main talking point for the sales force. They talk about details of how the production process is geared towards maximum quality; they wave official certificates of quality in front of you; they point out how important high quality ingrediences (subsystems) are for the product etc. For the building industry it´s even mandatory to register blueprints and quality calculations with the local authorities.
So the whole world seems to be concerned with quality and relentlessly shows it off.
But what about software companies? They claim to have great products. But this (mostly) means, they claim to offer products with a certain set of features providing value to a certain target group. Those features are assumed to be correctly implemented (which is not always true, as we all know) and assumed to perform/scale well (which is not always true, as we all know).
However, nobody in the software business really tries to show off how they planned, implemented, and monitored other quality measures than correctness or performance. That means except for Open Source software we´re all using black boxes whose quality in terms of maintainability, understandability, or architectural stability we don´t know. I might be impressed by some software, it works just fine, slick GUI, high performance. I´m willing to pay the prices. But I don´t have a clue if its manufacturer is even able to maintain it over a longer period of time. I don´t know it the manufacturer attributes any importance to a clean and maintainable architecture/structure. I just see the surface of the software (its GUI/API, its performance/scalability). But is that enough?
The more I think about it, the more I get the feeling, we need to more openly discuss the quality of our software products. And I suggest - as a starting point - to proactively publish DSMs (and other quality metrics) along with our software. Quite somecompanies invest into blogs maintained by their development staff to open themselves to the public, to gain trust. Why not add to this policy a quality report for each release of the software somewhere on the company´s website?
Or to put it the other way around: Why don´t we start to demand such quality reports from the manufacturers of our tools? Think of it: The next time you evaluate a database or report generator or GUI grid component you ask the manufacturer for a DSM. Of course they won´t know what that is, but then you explain them. Tell them you´re interested in the quality measures they apply. Tell them you just want to get a feeling for the state of the architecture they base their software on. You can reassure them you´re not interested in any code details. It´s just the structure of the system - which gives you a first hint at how quality conscious the manufacturer might be. So I´m not talking about Open Source, I´m talking about Open Quality or Open Architecture.
I think, this is what we need to start to demand if we really mean to improve product quality in our industry. A simple DSM for each system could be a start. It´s easy to understand and provides a first rough overview. But more metrics and figures could follow: How is the testing process organized? Do they use a version control system? Is there continuous integration in place? How about code reviews?
You say this is devulging too much information? Well, I say the industry is just not used to as much openess about quality measures as other industries are. And our industry is ashamed about its low quality standards. It´s simply scared to reflect (in public) upon how it ensures quality. Because publishing quality figures determined by tools like NDepend or Sotograph or Lattix DSM is not to be confused with leaking critical information on implementation details to the competition. It´s more like publishing a financial statement like all large corporations need to do.
To show you that I mean what I say, here´s the DSM (Fig. 14) for my currently only "product", a small Microkernel. It´s not much, but it´s a start.

Fig. 14: The structure of my small Microkernel
But I will continue to make public DSMs and other metrics whenever I develop software be it commercial products or code to accompany a conference presentation or a series of articles (since I´m an author/consultant/conference speaker). And I will motivate my customers to do so for their products.
I can only gain by becoming open about the internal quality of my software. I will gain trust, because trust begins by opening yourself to others. I will gain product quality, because now I´m forced to think more about it, since eventually the results of my descisions get published. And my customers - be it buyers/users of my software or readers of my articles - will gain insight which gives them a better feeling once they need to make any descions.
Think about it. What will you tell your customers, once they start looking at your software using a tool like Lattix LDM and thrown about what they see? With managed code anybody can strip your software naked as I did with the .NET Framework and VistaDB and Spring.Net. Obfuscation might help a bit here, but in the end, assessing the quality of your software´s architecture relies on names only to a limited extent. You can´t obfuscate dependencies, you can´t hide spaghetti structures.
But maybe before you publish anything about your own software you want to start a more quality conscious life by looking at other´s software. Download NDepend or Lattix LDM and point them to the assemblies of your favorite grid or application framework. Because: Once in a while nothing can beat the fun of pointing fingers at others :-)
[Continue here for some replies to comments from readers of this posting.]
[1] Tyson R. Browning: Process Integration Using the Design Structure Matrix, Systems Engineering, Vol. 5, No. 3, 2002
[2] Karl Ulrich, Steven Eppinger: Product Design and Development, McGraw-Hill/Irwin; 3 edition (July 30, 2003), ISBN 0072471468