Software Cells #6: Connecting Applications
In my last posting I tried to put Software Cells into perspective. And as it turned out, they prefectly fill a gap that existed between COP/OOP and SOA. With Software Cells we can seamlessly stack levels of abstraction onto each other from single statement to groups of Solutions which I call Software Societies.
However, I one piece of the Software Cell puzzle is still missing: How do Applications communicate with each other? So far I´ve depicted Software Cells as bordering on one another when they use each other´s services.
There was no gap between the Applications because I concencrated on intra-Application structures and Hosts. But talking about Core logic and SQL Server as an Application Host is not enough. Technologies like System.Net or .NET Remoting need find a place in the Software Cell model. So let´s step back and see, what we´re talking about:
I think it´s very beneficial to go back to the roots of programming and state once more:
All software is about I/O.
A single IL Add op-code is about IO like a service in a SOA is about IO. On all levels of abstraction of the software universe as depicted in my last posting the structures described take some input and produce some output. Without input and output software simply makes no sence.
An IL op-code takes its input from the stack and produces output on the stack. An Application might get its input from the user thru the frontend and send its output to a database. Or a service might read input from a database and send output via SMTP. Input and output of course can be as simple or as complex as needed. The simplest case of input is the "signal" to start producing output, i.e. an empty input. But output is never empty, otherwise a software structure would have no purpose (besides heating the environment by exercising the CPU :-).
But software of course also is about processing information. Something has to be done with the input to produce the output. So in the middle between input and output there is some logic:
input ---> processing logic ---> output
Sure, this is by no means some grand new insight. But sometimes it´s important to remind ourselves of the very basics to understand the brand new.
Fortunately tranlating this old truth to the Software Cells world is easy:
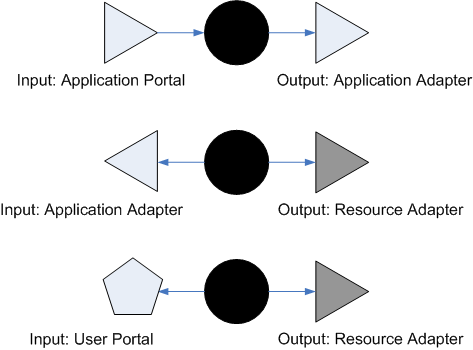
As you can see, Software Cells map the general input-processing-output to concrete structures in an Application: Processing is done in the Core of an Application. Adapters and Portals are responsible for collecting input and distributing output. (This very clear separation of concerns I find a real advantage of Software Cells compared to the layering model. Whereas for many developers it is difficult to decide, what code belongs into a data access layer, it is easy to know, what´s logic and what´s pure I/O.)
I´d say, it´s very obvious that Console.WriteLine(...) sends output to the console. The same is true if WriteLine() is called on some TextWriter() connected to a stream over TCP/IP. Input on the other hand can be collected using ReadLine() on some stream. But what about a WinForms frontend? It´s the same. mytextbox.Text = ... sends output to a GUI frontend and calling mylogic.Process(mytextbox.Text) sends input to the processing logic. Even though modern UIs are event driven, they nevertheless are I/O "devices".
But what about System.Net or .NET Remoting or even ADO.NET? To put it very bluntly and a little provocatively: These technologies, too, are only just I/O technologies. They just differ in the level of abstraction, the transport technology, data format and the programming model. But nevertheless they are all just about I/O. However, where the input data exactly comes from - whether from a hardware data sampling device or from a database - and where output exactly goes to - on a TCP/IP connection or a database or a file - is not important for the processing logic. The respective APIs of the I/O Adapters/Portals are responsible for managing all this.
This brings me back to the purpose of the Adapter and Portal structures: Their task is just to connect the logic to an I/O "device" and bridge the gap between the data models of Core logic and I/O "device". If the Core´s domain is insurance contract management, then it want´s to "think" on that level and does not want to concern itself with whether those contracts later on are stored in a RDBMS or a file or are send to some other service for further processing. The Core logic just want´s to use an Adapter/Portal on its level of abstraction and e.g. call myAdapter.StoreContract(mycontract). The purpose (interface) of the call is clear, the implementation is opaque, it´s a black box.
To make this more tangible let´s look at a set of Applications and how the communicate with each other.
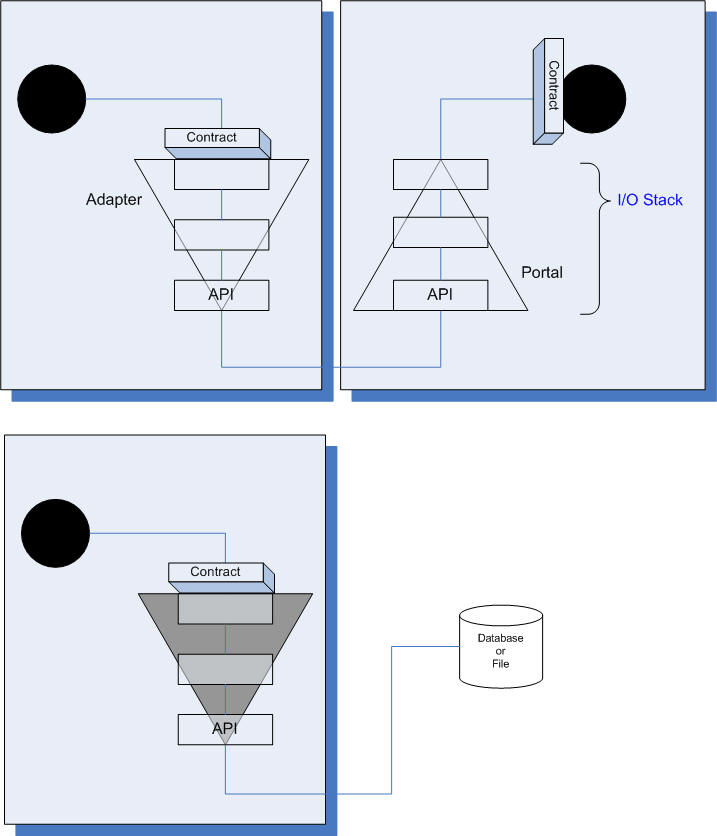
Sofware Cells - or to be more precise: the Core logic - always communicate with the outside world via a stack of I/O layers. If you think of the 7 layers of OSI you´re right on. It´s the same here with Adapters and Portals:
- Each layer in the I/O stack has the same purpose to send/receive data.
- Each layer is on a different level of abstraction, e.g. the top level is concerned with objects, the lowest level with bytes on a stream.
However, the number of layers within an Adapter/Portal is not fixed. A minimum of 2, though, makes sense: The bottom layer is always the raw API, the top layer is on the abstraction level of the Core. (To find an API on the level of the Core probably will be rare.)
Also, please don´t limit your thinking to the typical network I/O scenarios when you think about the communication stacks of Adapters/Portals. I´m serious when I say, .NET Remoting and ADO.NET are to be considered the same from the point of view of the Core logic. For me there is no essential difference between calling remote logic via .NET Remoting or via an ADO.NET DbCommand. And there is no essential difference between returning results from such a call as a parameter on a stack or as a resultset via a SQL Server pipe from within a C# stored procedure. It´s all the same.
Communication technologies like System.Net, .NET Remoting, Web services, MSMQ, and ADO.NET of course differ in several respects, e.g. level of abstraction (System.Net: low, .NET Remoting: high) or data model (.NET Remoting: objects, ADO.NET: simple data types or resultsets) or programming model (.NET Remoting: RPC, MSMQ: message based) or synchronicity (ADO.NET: (primarily) sync, MSMQ: async) or persistence (ADO.NET: persistent, System.Net: transient). But that does not make those technologies fundamentally different. Again: it´s all just about I/O or communication.
The implication for software development, though, is important: Don´t try to figure out complicated things like "What is business logic?" or "Is it ok to put business logic in the frontend?". Just clearly separate logic from I/O. Separate Core from Adapters/Portals.
And don´t get confused with all those technologies/standards like Web services, System.IO, System.Net, .NET Remoting, MSMQ, Serviced Components, Indigo, ADO.NET, SQL XML - or even SMTP, POP3. Which to choose from this ever growing set of options, is determined by several factors, which should be pretty clear, if you know your problem domain and have chosen the Hosts for your Software Cells. E.g. if an Application needs to call logic within another whose Host is SQL Server, then ADO.NET is the likely choise - but you also could choose SQL XML or SOAP. But if you need to connect two Console Hosts then .NET Remoting probably would come to your mind first.
Equally possible, though, would be MSMQ or - and this might surprise you - ADO.NET. MSMQ is an established communication technology for message based async communication. But what about ADO.NET? Isn´t that a database API, not a communication API? You´re right. That´s how it´s positioned usually. But what is a database? To put it provocatively: A database is like a message queue (which is often implemented using a database engine), which is like a file (which sure is the container for all database data), which is like a message (which is just a serialized form of data) on a wire. So, a database can be viewed as a container for data to be "exchanged" between different applications in space and time. The main difference between a message in a queue containing customer information and the same customer information in a database is, that the message has a target, whereas the data in the database "just sits there and waits to be picked up." But still, the data an Application outputs to a database sooner or later will be the input for some other (or the same) Application. The database is "just" an intermediate store between processing steps.
Or to put it differently: Today there is so much talk about interfaces/contracts between software on different platforms and versioning of those interfaces. But what usually is not seen is, that the most long lasting interfaces between solutions are RDBMS databases. Their lifetime is often measured in decades whereas Web service interfaces are comparatively much more volatile. (By the way, this emphasizes the importance of sound information modelling in databases and hiding their internal structures behind a strict contract.) Communication thus is not only in space, but also in time.
But now back to Software Cells. What does this all mean for designing Solutions consiting of Applications consisting of Core and Adapters/Portals?
Applications can be connected to resources and other Applications by a large number of different I/O or communication technologies. That means drawing Software Cells like I did so far, pretty quickly will become unwieldy. Thus, despite the compact look of a Software Cell "tissue" you´ll sooner or later want to move them apart and connect them with lines:
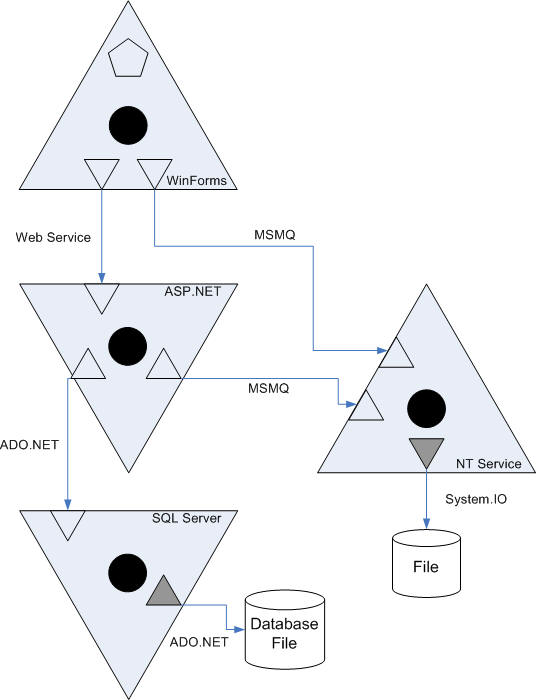
This notation is more flexible than the original one, I´d say. It easily lets you connect Applications over larger distances within a drawing, allows several connections to/from an Application, and gives you space to add technology descriptions to the connections between Adapter and Portal. Separate concerns are clearly separated: domain knowledge and functions are located within the Core, infrastructure for I/O is located at the Applications´ boundaries and in the inter cellular space. And the "ecosystem" (infrastructure) in which the Core works is represented by the Hosts.
I´d say that pretty much wraps up Software Cells. The technological puzzle pieces fall clearly into their places. No more wondering about what an NT Service is compared to COM+. No more wondering about how the ADO.NET and Web service API for SQL Service differ. Fundamentally they are in the same categories: Hosts and communication technologies. And you choose between them by comparing their features like programming model, data model, communication model, infrastructure, deployment etc.
And you never need to wonder again whether SQL Server 2005 is an application server not that you can write C# stored procedures. The simple answer is: Yes, it is an application server, or better: it is an Application Host like COM+ is and IIS and a console EXE.
So you can choose freely among all those options to find the best layout for your Core logic. Fear not to distribute "logic" across several Applications. That´s perfectly ok. Put it in the "frontend", put it in a database server. Just draw a clear line between logic and I/O, set up contracts between your Applications and components.
This is the essential message of Software Cells.