Azure Service Bus - Batching Brokered Messages
Azure Service Bus - Batched Sends
There are scenarios when messages need to be sent in bulk. For example: you recieve a message with CSV-like data and generate multiple messages (message per record in the file). To gain performance, generated messages can be batched and sent out in an atomic operation.
Azure Service Bus has an ability to batch outgoing messages as an atomic send operation using MessageSender.SendBatchAsync() API. It works great as long as the total size of the messages in the batch does not exceed 256KB. One possible solution could be dividing brokered messages in into chunks and send multiple batches. An attempt like this was implemented by Paolo Salvatori in ServiceBusExtensions. Unfortunately, there's a caveat to this approach. The idea of this grouping is based on evaluating the size of the each BrokeredMessage and adding messages to a batch while total size is below the 256K limit. What's the problem with that? The devil is in details.
Sending an individual message to get its` proper size does not sound like a superb idea. So what are the options?
One option would be to group BrokeredMessages based on a rough size estimate and divide those into groups of batched. Among challenges are things such as custom properties (message headers). Since those are defined as Dictionary<string, object>, while estimating the size of keys is not a big issue, doing the same for values can be a challenge.
Another option is to determine the size of a future message before it becomes BrokeredMessage, adding to it some overhead of serialization that takes place once the message is sent out. Among the benefits that I found with this approach are:
- Ability to estimate size based on the structure of messages relevant to the application and not general BrokeredMessage that has to cater every possible scenario. For example: in my solution headers are always strings. Size calculation of custom headers becomes very straight forward.
- Knowing what standard properties of BrokeredMessage are utilized and how (MessageId, SessionID, PartitionKey, etc.) allows to buffer estimated size accordingly.
- Knowing your payload (future BrokeredMessage body) helps to determine the size when serializing messages.
On top of that, an additional percentage can be added to
emulate some overhead that is going to be added when
messages are sent out. I was experimenting with different
message sizes, and padding percentages and results were
consistent. In my case, I tried with the body as a
byte[] and as a Stream to see the
difference.
Code
Native message structure
public class Message
{
public string MessageId { get; set; }
public byte[] Body { get; set; }
public Dictionary<string, string> Headers { get; set; }
}
Estimation code
public long GetEstimatedMessageSize()
{
const int assumeSize = 256;
var standardPropertiesSize = GetStringSizeInBytes(Message.MessageId) +
assumeSize + // ContentType
assumeSize + // CorrelationId
4 + // DeliveryCount
8 + // EnqueuedSequenceNumber
8 + // EnqueuedTimeUtc
8 + // ExpiresAtUtc
1 + // ForcePersistence
1 + // IsBodyConsumed
assumeSize + // Label
8 + // LockedUntilUtc
16 + // LockToken
assumeSize + // PartitionKey
8 + // ScheduledEnqueueTimeUtc
8 + // SequenceNumber
assumeSize + // SessionId
4 + // State
8 + // TimeToLive
assumeSize + // To
assumeSize; // ViaPartitionKey;
var headers = Message.Headers.Sum(property => GetStringSizeInBytes(property.Key) + GetStringSizeInBytes(property.Value));
var bodySize = Message.Body.Length;
var total = standardPropertiesSize + headers + bodySize;
var padWithPercentage = (double)(100 + messageSizePaddingPercentage) / 100;
var estimatedSize = (long)(total * padWithPercentage);
return estimatedSize;
}
private static int GetStringSizeInBytes(string value) => value != null ? Encoding.UTF8.GetByteCount(value) : 0;
Standard properties that are not of type
string can be hardcoded for their size. And if
your system doesn't utilize any of the string-based standard
properties, no need to pad size with
assumeSize.
Benchmark results
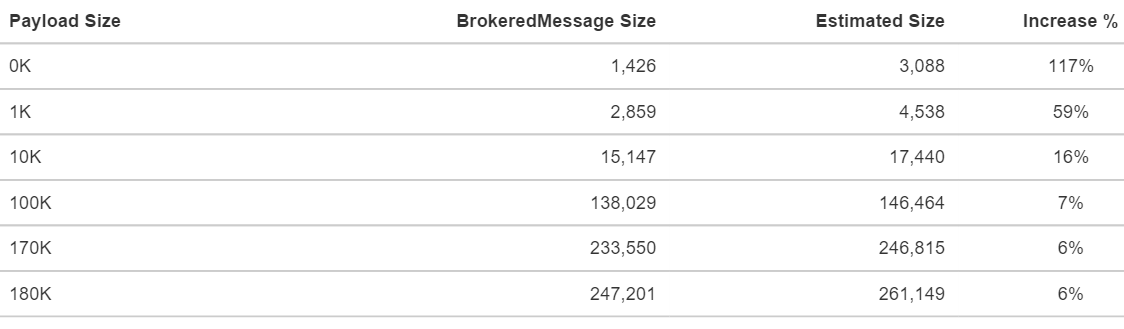
With padding of 5% and assumed size of 256 bytes for the properties that I'm potentially going to use, the results came out quite interesting.
Body type: byte[]
Body type: Stream
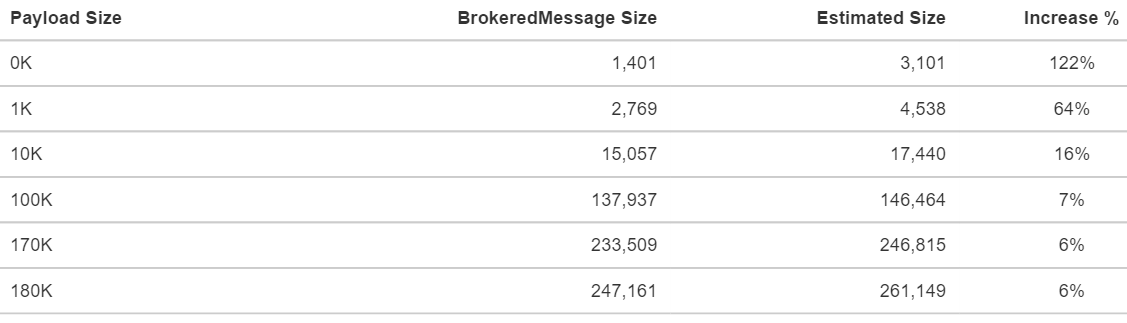
While the small messages padding and estimates are significantly higher, for messages over 10K that gap is significantly reduced.
Conclusions
The method I've described here is one of a few options. It allows to overcome the current shortcoming of the native method to send messages in a batch, until ASB team comes up with a better solution.