Free OCR software? You may already have it...
Update (2011): This post describes using a little know feature of Microsoft Office which does a good job with OCR. It was written 5 years ago, but still gets a lot of traffic. Unfortunately, Office 2010 removes that feature (Microsoft Office Document Imaging).
There are a few workarounds for this:
- You can still install Microsoft Office Document Imaging for free using the instructions here: http://support.microsoft.com/kb/982760
- There are number of free OCR options listed here: http://alternativeto.net/software/freeocr/
Summary
OCR (Optical Character Recognition) can really come in handy. For example, I previously wrote about how I use Timesnapper as a black box to recover work which would otherwise be lost. Since most of my work is text based (C#, SQL, HTML, documentation, communications, etc.), the obvious next step is to grab the code from a screenshot. Of course I can retype it, but OCR would be better.
There are some great commercial OCR packages out there. My company recently used OmniPage Pro in a project which loaded data from hundreds of PowerPoint slides into SQL Server for reporting and analysis1. OmniPage is great software, but it costs $149 for the basic version, which doesn't really make sense if you're just using it to avoid retyping a little text from a screenshot every now and then.
I looked around for free OCR software, and was a little bit surprised that there wasn't much out there. Here's a rundown of what I found, wrapping up with a program that wasn't technically free, but I already had it. There's a good chance you've got it, too.
GOCR
I first tried out GOCR (a.k.a. JOCR). The easiest way to try it out is the GOCR Win Frontend, which installs GOCR as well. My opinion matched Pitor's:
To let things be clear - gocr is not ready, to say the least. Personally I'd even say the effect of trying to OCR a page is so crappy it is not even worth installing the gocr engine (seems like the total rewrite in 0.40 did not help much). And I am talking about an ascii black text on a white page, without other elements. Gocr seems to go all the way down here - error in 98% of recognized characters, randomly added spaces, etc. For example: content is C unrir in gocr, sounds like drunken elvish to me.
Tesseract OCR
Yeah, there's been some chatter in the blogospheres and internets about Tesseract since Google assisted in re-releasing it as an open source project. I have no doubts that the press alone (not to mention Google's involvement) will propel Tesseract towards OCR fame and fortune, but it sounds like it's not usable at this point:
It only is configured to build under MSVC++6 for Windows.
It only accepts uncompressed bitonal tiffs.
It's command-line only.
No GUI.
It performed abysmally on the provided testimage.tif
But it did build. :)
Microsoft Office Document Imaging
On accident, I stumbled across Microsoft Office Document Imaging. It's included Microsoft Office Tools ("Microsoft Office \ Microsoft Office Tools" folder in the start menu, default installation location is "C:\Program Files\Common Files\Microsoft Shared\MODI\11.0\"). The interface looks a "My First VB5 Application" reject, but it works great.
It handles scanned documents via TWAIN. The image import's a bit lame - it only handles TIF files. You can convert to TIF in just about any graphics application (e.g. MSPAINT - open the file, Save As TIF file). An easier method is to just copy the image to the clipboard and paste as a new page into MODI.
Here's a quick walkthrough of how I grabbed some text from a PDF2.
Step 1. I selected the text I wanted to OCR with Cropper (output set to Clipboard)

Step 2. I opened Microsoft Office Document Imaging and loaded my image with Page / Paste Page
Step 3. I ran the OCR process by clicking on the "funky eye" toolbar button (or in the Tools menu)
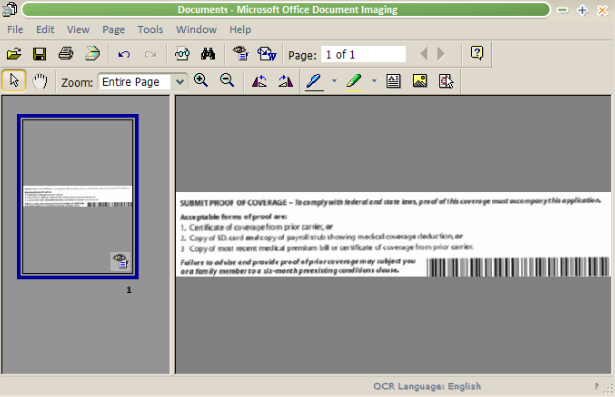
Step 4. Click the Export to Word toolbar button
Step 5. Copy the text and paste it where you want it
In this case, it was an e-mail. I've done the same thing to grab SQL or C# code which I then paste into the editor and compile (Ctrl-F5 for SQL, Ctrl-Shift-B for C#) to catch the things that didn't make it through the OCR cleanly.
I haven't tried it, but apparently you can automate MODI from .NET.
1 Yes, it sounds insane, but it actually worked, and the business value of the data more than justified it.
2 Yes, you can select and copy text in a PDF. This is just an example, but in this case the final result of the OCR'd text was a lot cleaner than the oddly mangled and mis-formatted text I got from the PDF select / copy approach.