Enterprise .Net
Morteza Manavi
-
NHibernate for Entity Framework Developers: Part 1 – Fluent NHibernate
The approach to managing persistent data has been a key design decision in every software project we’ve worked on. Given that persistent data isn’t a new or unusual requirement for .NET applications, you’d expect to be able to make a simple choice among similar, well-established persistence solutions. Each of the competing solutions has various advantages and disadvantages, but they all share the same scope and overall approach.
Having said that, making the right decision requires a fairly good knowledge of the ORM solutions currently available for .NET. In other words, if all you know is one ORM and one only, then you won't have much of a choice in there, you always have to go with the only framework that you know of and sometimes it might not be the best solution for your specific project. Entity Framework could be a viable option, an approach to persistence, proposes to provide a ORM solution with the full commercial support and backing of Microsoft. But is that really enough reason for us to simply ignore just about everything else?What is NHibernate and Why Should You Care?

NHibernate is an ambitious open source project that aims to be a complete solution to the problem of managing persistent data in .NET. NHibernate is a .NET port of the very popular and successful Java Hibernate library and is one of the most mature, powerful ORM frameworks available in .NET today, an important option and one that you shouldn't ignore. What is the Goal of This Post?
From my experience with the .NET user community, I know that the first thing many developers (especially those with a history of using MS tools and frameworks like EF) say when it comes to NHibernate is that it's a sophisticated framework and has a steep learning curve. In this series of posts I'll walk you through the process of building a project with NHibernate and will show how you can leverage your EF knowledge to get up and running with NH as quickly and easily as possible.
This writing is not a debate on EF vs. NHibernate, nor is a comparison to show which one is better than the other. I'll just present the advantages and drawbacks of the two approaches to you and will show their solutions for various persistence problems. My hope is that at the end it gives you an insight to conclude which one is a better persistence solution for your specific project.A Note For Those Who Never Worked with Any ORM Before
Keep reading! The title of this series might be a bit misleading as I don't assume any knowledge of EF when explaining NHibernate, of course being familiar with one ORM solution like EF would help but is absolutely not a requirement so with a little extra effort, you can learn NHibernate just like the EF developers.Your First NHibernate Project
Open your Visual Studio and create a new Console Application project. Before you can start coding your first NHibernate application, you need to reference NHibernate binaries. NHibernate 3.1.0.GA can be downloaded from here. Download and extract the zip file to some location on your drive. The next step is to reference the required binaries in your new project. To do this, follow these steps:- Right-click the project and select Add Reference...
- Click the Browse... button and navigate to the folder where NHibernate binaries are extracted.
- Open Required_Bins folder and select NHibernate.dll. Click OK to add this reference to your project.
- Right-click again on the the project and select Add Reference... and navigate to the folder where NHibernate binaries are extracted.
- This time open Required_For_LazyLoading folder and then Castle folder.
- Add a reference to NHibernate.ByteCode.Castle.dll.
Creating a Domain Model
Just like my other posts on EF Code First, this post takes a top-down approach; it assumes that you’re starting with a domain model and trying to derive a new SQL schema but this time with NHibernate. When you’re using NHibernate, entities are implemented as POCOs, a back-to-basics approach that essentially consists of using unbound classes in the business layer which leads to the notion of persistence ignorance in our applications. This results in entities with less coupling that are easier to modify, test, and reuse. EF also supports this pattern starting from its second version (aka EF 4.0).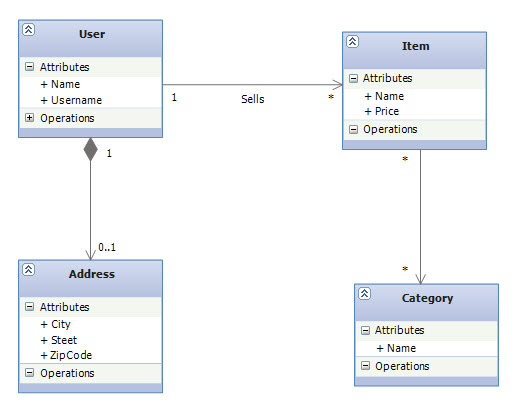
The following shows the POCO classes that form the object model for this domain: public class User { public User() { Items = new List<Item>(); } public virtual int UserId { get; private set; } public virtual string Name { get; set; } public virtual string Username { get; set; } public virtual Address Address { get; set; } public virtual IList<Item> Items { get; set; } public virtual void AddItem(Item item) { item.Seller = this; Items.Add(item); } } public class Address { public virtual string Steet { get; set; } public virtual string City { get; set; } public virtual string ZipCode { get; set; } } public class Item { public Item() { Categories = new List<Category>(); } public virtual int ItemId { get; private set; } public virtual string Name { get; set; } public virtual double Price { get; set; } public virtual User Seller { get; set; } public virtual IList<Category> Categories { get; set; } } public class Category { public Category() { Items = new List<Item>(); } public virtual int CategoryId { get; private set; } public virtual string Name { get; set; } public virtual IList<Item> Items { get; set; } public virtual void AddItem(Item item) { item.Categories.Add(this); Items.Add(item); } }
The POCO classes are pretty straight forward, except you might wondering what the AddItem methods are for in there, for now, think of the code in the AddItem (a convenience method) as implementing a strong bidirectional association in the object model. How Mappings are Specified in NHibernate?
Just like EF, NHibernate gives you different ways to specify mappings for your persistent classes. You can use XML files, CLR attributes or Fluent API.- Mapping using XML The ability of mapping classes with XML is what NHibernate inherits from Hibernate, where usually each persistent class has an XML mapping file ends with the .hbm.xml extension and is embedded in the same assembly as the mapped class file. This is analogous to an EF's Edmx file but unlike Edmx files, these HBM mapping documents are lightweight, human readable, easily hand-editable and can be easily manipulated by version-control systems. Although Visual Studio comes with a designer support for Edmx files, but the problem is that this support is somewhat limited and you sometimes have to drill down to the underlying XML file to define your desired mapping or behavior, examples like creating a TPC mapping or defining QueryViews. I personally didn't find editing the raw XMLs in Edmx files (and dealing with an Edmx file in general) a fun practice and I think this is a common feeling throughout the community as we see more and more developers are leaning toward Code First development to keep their projects away from an Edmx file.
- Attribute-oriented Mapping Alternatively, you can use CLR attributes defined in the NHibernate.Mapping.Attributes library to provide all the information NHibernate needs to map your classes. This is comparable to the new attributes that the latest release of EF (EF 4.1) provides in System.ComponentModel.DataAnnotations namespace which you can use to map your classes when doing EF Code First development except that EF annotations are not complete and you often have to resort to fluent API to do the mappings (Examples like creating a TPC mapping, customizing a TPH mapping, specifying cascade deletes on associations or customizing the mapping for a many-to-many association.).
- Fluent Mapping Fluent mapping is based on a Fluent Interface that allows you to map your entities completely in code, with all the compile-time safety and refactorability that it brings. Just like the fluent API in EF Code First, Fluent NHibernate project provides an alternative to NHibernate's standard XML mapping files. As a result, rather than writing XML documents, you write mappings in strongly typed C# (or VB) code. It's even has a concept called Auto Mapping which is a mechanism for automatically mapping all your entities based on a set of conventions. This is very similar to the EF Code First as they both follow the convention over configuration principle. In this post we use Fluent NHibernate to map our persistent classes since this allows for easy refactoring, improved readability and more concise and elegant code. More importantly, if you used Code First fluent API before, you'll find this approach very familiar.
Adding Fluent NHibernate to the Project

Fluent NHibernate is a separate open source project that needs to be referenced in your project before you can start using its fluent interfaces to map your persistent classes. You can download the binaries from here. Once you've got a copy on your local machine, right-click the project and select Add Reference... and then reference the FluentNHibernate.dll assembly which is inside the extracted folder from the zip file you downloaded. Mapping Entities and Components
In EF Code First, we use EntityTypeConfiguration class to define a mapping for an entity. We derive from this class to create a mapping, and use its constructor to control how our entity is persisted. Fluent NHibernate has the same approach except that it differs between an entity and a value object in essence that if you are mapping an entity you'd use ClassMap and if you are mapping a value object you'd use ComponentMap class. The reason for this naming is because NHibernate uses the term component for a user-defined class that is persisted to the same table as the owning entity. A Component is the exact same concept as a Complex Type in EF: an object that has no individual identity. The following code shows how to register the Address class as a component as well as how to specify UserId as the object identifier:class UserMap : ClassMap<User> { public UserMap() { Id(u => u.UserId); Component(u => u.Address); } }
Associations in Entity Framework and NHibernate
As you may know, foreign keys in the first release of EF were not exposed on entities, something we know by the the name of independent associations. These associations were managed which means they had their own independent entry in the ObjectStateManager where each entry (of course) has its own EntityState. These independent associations make a few things such as N-Tier and concurrency really difficult. For example, concurrency checks were performed on relationships independently of the concurrency checks performed on entities, and there was no way to opt out of these relationship concurrency checks. The result was that your services must carry the original values of relationships and set them on the context before changing relationships. Because of this and a few other problems, these associations eventually became deprecated in the second release of EF and a new type of association called foreign key associations has been introduced where foreign keys were exposed in the persistent classes along with their related object references (aka navigation properties). The concurrency problem has been solved because now the relationship is simply a property of the entity, and if the entity passes its concurrency check, no further check is needed. Now you can change a relationship just by changing the foreign key value.
I have mixed feelings about these foreign key associations. On the one hand, it's not managed anymore and doesn’t expose us to all the problems of independent associations but on the other hand, foreign keys are part of the impedance mismatch problem and should not be in the object model. They add noise to the persistence classes and they even introduce some new problems. For example, having foreign keys as well as object references for relationship navigation presents the problem of two different artifacts representing one relationship – this introduces complexity and now you have to make sure that you keep these two in sync.
On the other hand, the NHibernate association model is interesting. Foreign keys correctly don't need to be part of the entities but at the same time NHibernate doesn’t "manage" persistent associations. It's kind of the best of two worlds approach. In NHibernate, if you want to manipulate an association, you must write exactly the same code you would write without NHibernate. If an association is bidirectional, both sides of the relationship must be considered. As you can see in the model, the Employee class, for example, doesn't reflect the ProductId foreign key from the database. Next, you'll see how associations are mapped in NHibernate.Associations in NHibernate are Directional
It’s important to understand that NHibernate associations are all inherently unidirectional. As far as NHibernate is concerned, the association from Item to User is a different association than the association from User to Item. To EF developers, this might seems strange; I’ll merely observe that this decision was made because unlike EF, NHibernate objects aren’t bound to any context. In NHibernate applications, the behavior of a nonpersistent instance is the same as the behavior of a persistent instance.
Because associations in NHibernate are directional, we call the association from Item to User a many-to-one association (many Items sold by one user, hence many-to-one). You can now conclude that the inverse association from User to Item is a one-to-many association. The following shows the mapping code with Fluent NHibrenate for the Item entity:public class ItemMap : ClassMap<Item> { public ItemMap() { Id(i => i.ItemId); Map(i => i.Name); Map(i => i.Price); References(i => i.Seller) .Column("UserId") .Not.Nullable(); } }
The References method creates a many-to-one relationship between two entities. So far we have created a unidirectional many-to-one association. The column UserId in the Item table is a foreign key to the primary key of the User table. Making the Association Bidirectional
Now let's have a look at the mapping for the User entity as the other end of the User-Item association. Here we use the HasMany method to create a one-to-many association from User to Item:public class UserMap : ClassMap<User> { public UserMap() { Id(u => u.UserId); Map(u => u.FullName).Length(50); Map(u => u.UserName).Not.Nullable().Unique(); Component(u => u.Address); HasMany(u => u.Items) .Cascade.All() .Inverse() .KeyColumn("UserId"); } }
The mapping defined by the KeyColumn method is a foreign-key column of the associated Item table. Note that we specified the same foreign-key column name in this collection mapping as we specified in the mapping for the many-to-one association. Now we have two different unidirectional associations mapped to the same foreign key. At this point, all we need to do is to tell NHibernate to treat this as a bidirectional association. The Inverse method tells NHibernate that the collection is a mirror image of the many-to-one association on the other side and we are done. Mapping a Many-to-Many Association
HasManyToMany method creates a many-to-many relationship and we use it to map the association between Item and Category entities. In NHiberbate, a bidirectional association always requires that you set both ends of the association and a many-to-many association is not an exception:public class CategoryMap : ClassMap<Category> { public CategoryMap() { Id(c => c.CategoryId); Map(c => c.Name); HasManyToMany(c => c.Items) .Cascade.All() .Table("ItemCategory"); } }
public class ItemMap : ClassMap<Item> { public ItemMap() { Id(i => i.ItemId); Map(p => p.Name); Map(i => i.Price); References(i => i.Seller) .Column("UserId") .Not.Nullable(); HasManyToMany(i => i.Categories) .Cascade.All() .Inverse() .Table("ItemCategory"); } }
When you map a bidirectional many-to-many association, you must declare one end of the association using Inverse method to define which side’s state is used to update the link table. I chose the Item entity to be the inversed end of this many-to-many association. This setting tells NHibernate to ignore changes made to the Categories collection and use the other end of the association— the items collection —as the representation that should be synchronized with the database. NHibernate Configuration and Schema Generation
The object model and its mappings are ready and now all we need to do is to wire them to NHibernate. Fluent NH can help us with this as well since it provides an API for completely configuring NHibernate for use with your application, all in code. The following shows how:ISessionFactory factory = Fluently.Configure() .Database(MsSqlConfiguration.MsSql2008 .ConnectionString(c => c.FromConnectionStringWithKey("SQLExpress"))) .Mappings(m => m.FluentMappings.AddFromAssemblyOf<Program>()) .ExposeConfiguration(config => { SchemaExport schemaExport = new SchemaExport(config); schemaExport.Drop(true, true); schemaExport.Create(true, true); }) .BuildSessionFactory();
Fluently.Configure starts the configuration process. The Database method is where you specify your database configuration using the database configuration API. ExposeConfiguration is optional, but allows you to alter the raw Configuration object. BuildSessionFactory is the final call, and it creates the NHibernate SessionFactory instance from your configuration. We'll take a closer look at ISessionFactory and other NHibernate's core interfaces in the next post.
As you may have noticed, this code also generates the DDL from the object model and executes it against the target database but with one caveat: You need to manually create the database yourself before running this code since NHibernate will not create the database for you. Like the class name suggests (SchemaExport), it only creates the schemas in the database. After creating the database, you can run this code as many times as you want, as it is designed just like EF Code First's DropCreateDatabaseAlways strategy.SQL Schema
The presented object model will result in the creation of the following schema in the database: 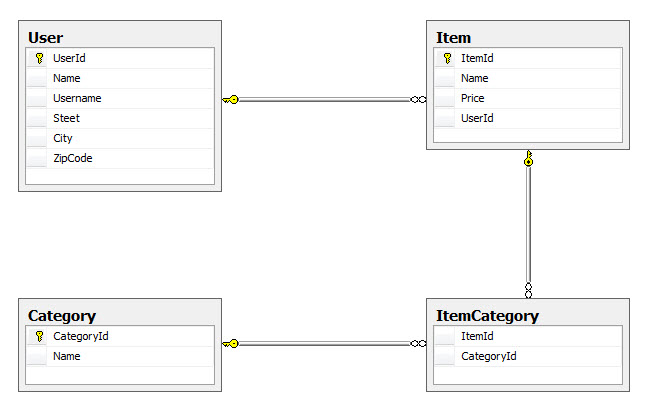
Source Code
Click here to download the source code for the project that we have built in this post.Summary
In this post, we take a high-level look at NHibernate and its mapping system by running a simple example. We also saw how to configure NHibernate with Fluent NHibernate, a technique similar to EF Fluent API which saves us from dealing with XML mapping files. This post sets the basis for the next part where we will focus more on the dynamic behavioral aspects of NHibernate, something that comes into play at runtime and we'll see how it differs from EF in that area.* A QueryView is a mapping that allows you to override the default mapping for an entity and return a new read-only strong type. This way, you can get the benefit of a projection, but return an entity instead of an anonymous type which you can’t pass around from one method to another. -
Associations in EF Code First: Part 6 – Many-valued Associations
This is the sixth and last post in a series that explains entity association mappings with EF Code First. I've described these association types so far: Support for many-valued associations is an absolutely basic feature of an ORM solution like Entity Framework. Surprisingly, we’ve managed to get this far without needing to talk much about these types of associations. Even more surprisingly, there is not much to say on the topic—these associations are so easy to use in EF that we don’t need to spend a lot of effort explaining it. To get an overview, we first consider a domain model containing different types of associations and will provide necessary explanations around each of them. Since this is the last post in this series, I'll show you two tricks at the end of this post that you might find them useful in your EF Code First developments. Many-valued entity associations
A many-valued entity association is by definition a collection of entity references. One-to-many associations are the most important kind of entity association that involves a collection. We go so far as to discourage the use of more exotic association styles when a simple bidirectional many-to-one/one-to-many will do the job. A many-to-many association may always be represented as two many-to-one associations to an intervening class. This model is usually more easily extensible, so we tend not to use many-to-many associations in applications.Introducing the OnlineAuction Domain Model
The model we introducing here is related to an online auction system. OnlineAuction site auctions many different kinds of items. Auctions proceed according to the “English auction” model: users continue to place bids on an item until the bid period for that item expires, and the highest bidder wins. A high-level overview of the domain model is shown in the following class diagram: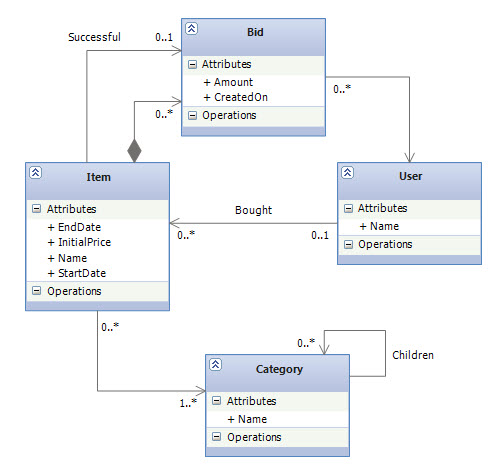
Each item may be auctioned only once, so we have a single auction item entity named Item. Bid is associated directly with Item. The Object Model
The following shows the POCO classes that form the object model for this domain:public class User { public int UserId { get; set; } public string Name { get; set; } public virtual ICollection<Item> BoughtItems { get; set; } } public class Item { public int ItemId { get; set; } public string Name { get; set; } public double InitialPrice { get; set; } public DateTime StartDate { get; set; } public DateTime EndDate { get; set; } public int? BuyerId { get; set; } public int? SuccessfulBidId { get; set; } public virtual User Buyer { get; set; } public virtual Bid SuccessfulBid { get; set; } public virtual ICollection<Bid> Bids { get; set; } public virtual ICollection<Category> Categories { get; set; } } public class Bid { public int BidId { get; set; } public double Amount { get; set; } public DateTime CreatedOn { get; set; } public int ItemId { get; set; } public int BidderId { get; set; } public virtual Item Item { get; set; } public virtual User Bidder { get; set; } } public class Category { public int CategoryId { get; set; } public string Name { get; set; } public int? ParentCategoryId { get; set; } public virtual Category ParentCategory { get; set; } public virtual ICollection<Category> ChildCategories { get; set; } public virtual ICollection<Item> Items { get; set; } }
The Simplest Possible Association
The association from Bid to Item (and vice versa) is an example of the simplest possible kind of entity association. You have two properties in two classes. One is a collection of references, and the other a single reference. This mapping is called a bidirectional one-to-many association. The property ItemId in the Bid class is a foreign key to the primary key of the Item entity, something that we call a Foreign Key Association in EF 4. We defined the type of the ItemId property as an int which can't be null because we can’t have a bid without an item—a constraint will be generated in the SQL DDL to reflect this. We use HasRequired method in fluent API to create this type of association:class BidConfiguration : EntityTypeConfiguration<Bid> { internal BidConfiguration() { this.HasRequired(b => b.Item) .WithMany(i => i.Bids) .HasForeignKey(b => b.ItemId); } }
An Optional One-to-Many Association Between User and Item Entities
Each item in the auction may be bought by a User, or might not be sold at all. Note that the foreign key property BuyerId in the Item class is of type Nullable<int> which can be NULL as the association is in fact to-zero-or-one. We use HasOptional method to create this association between User and Item (using this method, the foreign key must be a Nullable type or Code First throws an exception):class ItemConfiguration : EntityTypeConfiguration<Item> { internal ItemConfiguration() { this.HasOptional(i => i.Buyer) .WithMany(u => u.BoughtItems) .HasForeignKey(i => i.BuyerId); } }
A Parent/Child Relationship
In the object model, the association between User and Item is fairly loose. We’d use this mapping in a real system if both entities had their own lifecycle and were created and removed in unrelated business processes. Certain associations are much stronger than this; some entities are bound together so that their lifecycles aren’t truly independent. For example, it seems reasonable that deletion of an item implies deletion of all bids for the item. A particular bid instance references only one item instance for its entire lifetime. In this case, cascading deletions makes sense. In fact, this is what the composition (the filled out diamond) in the above UML diagram means. If you enable cascading delete, the association between Item and Bid is called a parent/child relationship, and that's exactly what EF Code First does by default on associations created with the HasRequired method.
In a parent/child relationship, the parent entity is responsible for the lifecycle of its associated child entities. This is the same semantic as a composition using EF complex types, but in this case only entities are involved; Bid isn’t a value type. The advantage of using a parent/child relationship is that the child may be loaded individually or referenced directly by another entity. A bid, for example, may be loaded and manipulated without retrieving the owning item. It may be stored without storing the owning item at the same time. Furthermore, you reference the same Bid instance in a second property of Item, the single SuccessfulBid (take another look at the Item class in the object model above). Objects of value type can’t be shared.Many-to-Many Associations
The association between Category and Item is a many-to-many association, as can be seen in the above class diagram. a many-to-many association mapping hides the intermediate association table from the application, so you don’t end up with an unwanted entity in your domain model. That said, In a real system, you may not have a many-to-many association since my experience is that there is almost always other information that must be attached to each link between associated instances (such as the date and time when an item was added to a category) and that the best way to represent this information is via an intermediate association class (In EF, you can map the association class as an entity and map two one-to-many associations for either side.).
In a many-to-many relationship, the join table (or link table, as some developers call it) has two columns: the foreign keys of the Category and Item tables. The primary key is a composite of both columns. In EF Code First, many-to-many associations mappings can be customized with a fluent API code like this:class ItemConfiguration : EntityTypeConfiguration<Item> { internal ItemConfiguration() { this.HasMany(i => i.Categories) .WithMany(c => c.Items) .Map(mc => { mc.MapLeftKey("ItemId"); mc.MapRightKey("CategoryId"); mc.ToTable("ItemCategory"); }); } }
SQL Schema
The following shows the SQL schema that Code First creates from our object model: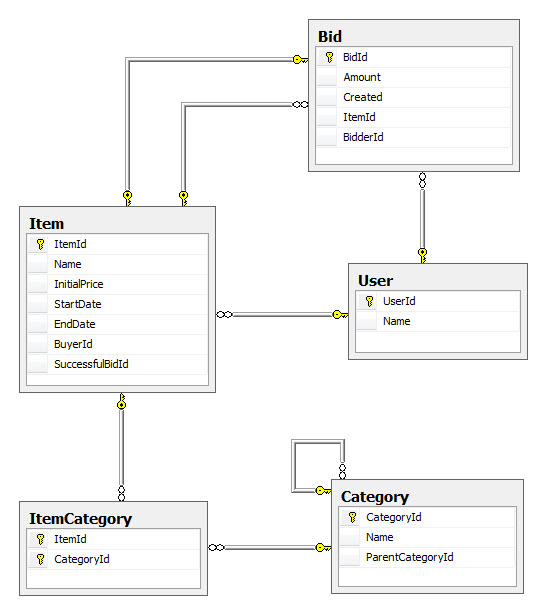
Get the Code First Generated SQL DDL
A common process, if you’re starting with a new application and new database, is to generate DDL with Code First automatically during development; At the same time (or later, during testing), a professional DBA verifies and optimizes the SQL DDL and creates the final database schema. You can export the DDL into a text file and hand it to your DBA. CreateDatabaseScript on ObjectContext class generates a data definition language (DDL) script that creates schema objects (tables, primary keys, foreign keys) for the metadata in the the store schema definition language (SSDL) file (in the next section, you'll see where this metadata come from):using (var context = new Context()) { string script = ((IObjectContextAdapter)context).ObjectContext.CreateDatabaseScript(); }
You can then use one of the classes in the .Net File IO API like StreamWriter to write the script on the disk. 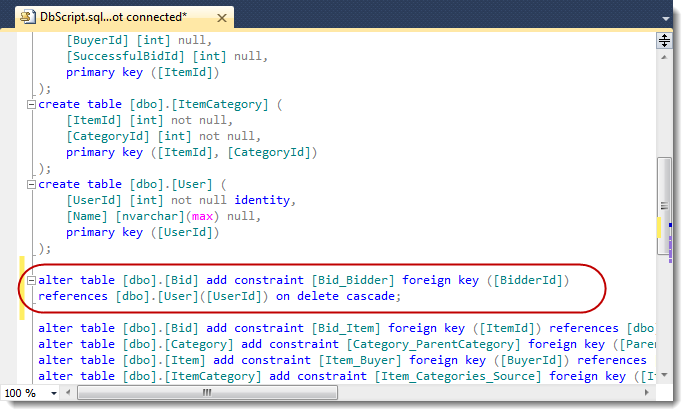
Note how Code First enables cascade deletes for the parent/child relationship between Item and Bid Get the Runtime EDM
One of the benefits of Code First development is that we don't need to deal with the Edmx file, however, that doesn't mean that the concept of EDM doesn't exist at all. In fact, at runtime, when the context is used for the first time, Code First derives the EDM (CSDL, MSL, and SSDL) from our object model and this EDM is even cached in the app-domain as an instance of DbCompiledModel. Having access to this generated EDM is beneficial in many cases. At the very least, we can add it to our solution and use it as a class diagram for our domain model. More importantly, we can use this EDM for debugging when there is a need to look at the model that Code First creates internally. This EDM also contains the conceptual schema definition language (CSDL) something that drives the EF runtime behavior. The trick is to use the WriteEdmx Method from the EdmxWriter class like the following code:using (var context = new Context()) { XmlWriterSettings settings = new XmlWriterSettings(); settings.Indent = true; using (XmlWriter writer = XmlWriter.Create(@"Model.edmx", settings)) { EdmxWriter.WriteEdmx(context, writer); } }
After running this code, simply right click on your project and select Add Existing Item... and then browse and add the Model.edmx file to the project. Once you added the file, double click on it and visual studio will perfectly show the edmx file in the designer: 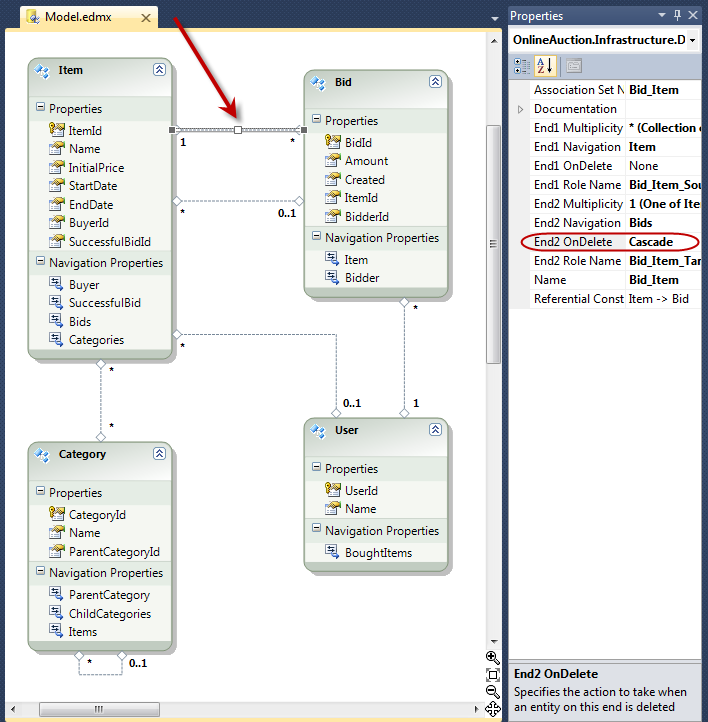
Also note how cascade delete is also enabled in the CSDL for the parent/child association between Item and Bid. Source Code
Click here to download the source code for the OnlineAuction site that we have seen in this post.Summary
In this series, we focused on the structural aspect of the object/relational paradigm mismatch and discussed one of the main ORM problems relating to associations. We explored the programming model for persistent classes and the EF Code First fluent API for fine-grained classes and associations. Many of the techniques we’ve shown in this series are key concepts of object/relational mapping and I am hoping that you'll find them useful in your Code First developments. -
Associations in EF Code First: Part 5 – One-to-One Foreign Key Associations
This is the fourth post in a series that explains entity association mappings with EF Code First. I've described these association types so far: - Part 1 – Introduction and Basic Concepts
- Part 2 – Complex Types
- Part 3 – Shared Primary Key Associations
- Part 4 – Table Splitting
- Part 5 – One-to-One Foreign Key Associations
- Part 6 – Many-valued Associations
Introducing the Revised Model
In this revised version, each User always have two addresses: one billing address and another one for delivery. The following class diagram demonstrates the domain model: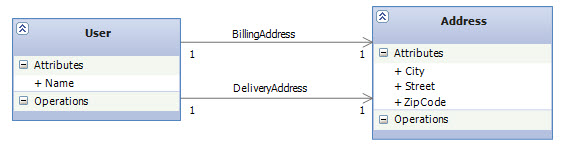
One-to-One Foreign Key Association
Instead of sharing a primary key, two rows can have a foreign key relationship. One table has a foreign key column that references the primary key of the associated table (The source and target of this foreign key constraint can even be the same table: This is called a self-referencing relationship.). An additional constraint enforces this relationship as a real one to one. For example, by making the BillingAddressId column unique, we declare that a particular address can be referenced by at most one user, as a billing address. This isn’t as strong as the guarantee from a shared primary key association, which allows a particular address to be referenced by at most one user, period. With several foreign key columns (which is the case in our domain model since we also have a foreign key for DeliveryAddress), we can reference the same address target row several times. But in any case, two users can’t share the same address for the same purpose.The Object Model
Let's start by creating an object model for our domain:public class User { public int UserId { get; set; } public string Name { get; set; } public int BillingAddressId { get; set; } public int DeliveryAddressId { get; set; } public Address BillingAddress { get; set; } public Address DeliveryAddress { get; set; } } public class Address { public int AddressId { get; set; } public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } } public class Context : DbContext { public DbSet<User> Users { get; set; } public DbSet<Address> Addresses { get; set; } }
As you can see, User class has introduced two new scalar properties as BillingAddressId and DeliveryAddressId as well as their related navigation properties (BillingAddress and DeliveryAddress). Configuring Foreign Keys With Fluent API
BillingAddressId and DeliveryAddressId are foreign key scalar properties representing the actual foreign key values that the relationships are established on. However, Code First will not recognize them as the foreign keys for the associations since their names are not aligned with the conventions that it has to infer foreign keys. Therefore, we need to use fluent API (or Data Annotations) to let Code First know about the foreign key properties. The following fluent API code shows how:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<User>() .HasRequired(a => a.BillingAddress) .WithMany() .HasForeignKey(u => u.BillingAddressId); modelBuilder.Entity<User>() .HasRequired(a => a.DeliveryAddress) .WithMany() .HasForeignKey(u => u.DeliveryAddressId); }
Alternatively, we can use Data Annotations to achieve this. EF 4.1 introduced a new attribute in System.ComponentModel.DataAnnotations namespace called ForeignKeyAttribute. We can place this on a navigation property to specify the property that represents the foreign key of the relationship: public class User { public int UserId { get; set; } public string Name { get; set; } public int BillingAddressId { get; set; } public int DeliveryAddressId { get; set; } [ForeignKey("BillingAddressId")] public Address BillingAddress { get; set; } [ForeignKey("DeliveryAddressId")] public Address DeliveryAddress { get; set; } }
That said, we won't use this data annotation and will go with the fluent API way for a reason that you'll soon see. Creating a SQL Server Schema
The object model seems to be ready to give us the desired SQL schema, however, if we try to create a SQL Server database from it, we will get an InvalidOperationException with this message:The database creation succeeded, but the creation of the database objects did not. See InnerException for details.The inner exception is a SqlException containing this message: Introducing FOREIGN KEY constraint 'User_DeliveryAddress' on table 'Users' may cause cycles or multiple cascade paths. Specify ON DELETE NO ACTION or ON UPDATE NO ACTION, or modify other FOREIGN KEY constraints. Could not create constraint. See previous errors.As you can tell from the type of the inner exception (SqlException), it has nothing to do with EF or Code First; it has been generated purely by SQL Server when Code First was trying to create a database based on our object model. What's a Multiple Cascade Path Anyway?
A Multiple Cascade Path happens when a cascade path goes from column col1 in table A to table B and also from column col2 in table A to table B. For example in our case Code First attempted to turn on cascade delete for both BillingAddressId and DeliveryAddressId columns in the Users table. In fact, Code First was trying to use Declarative Referential Integrity (DRI) to enforce cascade deletes and the problem is that SQL Server is not fully ANSI SQL-92 compliant when it comes to the cascading actions. In SQL Server, DRI forbids cascading updates or deletes in a multiple cascade path scenario.
A KB article also explains why we received this error:
"In SQL Server, a table cannot appear more than one time in a list of all the cascading referential actions that are started by either a DELETE or an UPDATE statement. For example, the tree of cascading referential actions must only have one path to a particular table on the cascading referential actions tree".And it exactly applies to our example: The User table appeared twice in a list of cascading referential actions started by a DELETE from the Addresses table. Basically, SQL Server does simple counting of cascade paths and, rather than trying to work out whether any cycles actually exist, it assumes the worst and refuses to create the referential actions (cascades). Therefore, depend on your database engine, you may or may not get this exception.Overriding The Code First Convention To Resolve the Problem
As you saw, Code First automatically turns on cascade delete on a required one-to-many association based on the conventions. However, in order to resolve the exception that we got from SQL Server, we have no choice other than overriding this cascade delete behavior detected by convention. Basically we need to switch cascade delete off on at least one of the relationships and as of EF 4.1, there is no way to accomplish this other than using fluent API. Let's switch it off on DeliveryAddress association for example:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<User>() .HasRequired(a => a.BillingAddress) .WithMany() .HasForeignKey(u => u.BillingAddressId); modelBuilder.Entity<User>() .HasRequired(a => a.DeliveryAddress) .WithMany() .HasForeignKey(u => u.DeliveryAddressId).WillCascadeOnDelete(false); }
One-to-One Foreign Key Associations in EF Code First
As you may have noticed, both associations in the fluent API code has been configured as a many-to-one—not one-to-one, as you might have expected. The reason is simple: Code First (and EF in general) does not natively support one-to-one foreign key associations. In fact, EF does not support any association scenario that involves unique constraints at all. Fortunately, in this case we don’t care what’s on the target side of the association, so we can treat it like a to-one association without the many part. All we want is to express “This entity (User) has a property that is a reference to an instance of another entity (Address)” and use a foreign key field to represent that relationship. EF (of course) still thinks that the relationship is many-to-one. This is a workaround for the current EF limitation which comes with two consequences: First, EF won't create any additional constraint for us to enforces this relationship as a one to one, we need to manually create it ourselves. The second limitation that this lack of support impose to us is more important: one to one foreign key associations cannot be bidirectional (e.g. we cannot define a property for the User on the Address class).Create a Unique Constraint To Enforce the Relationship as a One to One
We can manually create unique constraints on the foreign keys in the database after Code First creates it for us but if you are like me and prefer to create your database in one shot then there is a way to have Code First create the constraints as part of its database creation process. For that we can take advantage of the new EF 4.1 ExecuteSqlCommand method on Database class which allows raw SQL commands to be executed against the database. The best place to invoke ExecuteSqlCommand method for this purpose is inside a Seed method that has been overridden in a custom initializer class:protected override void Seed(Context context) { context.Database.ExecuteSqlCommand("ALTER TABLE Users ADD CONSTRAINT uc_Billing UNIQUE(BillingAddressId)"); context.Database.ExecuteSqlCommand("ALTER TABLE Users ADD CONSTRAINT uc_Delivery UNIQUE(DeliveryAddressId)"); }
This code adds unique constraints to the BillingAddressId and DeliveryAddressId columns in the DDL generated by Code First. SQL Schema
The object model is ready now and will result in the following database schema: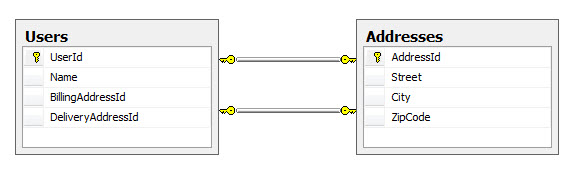
It is also worth mentioning that we can still enforce cascade deletes for the Delivery Address relationship. SQL Server allows enforcing referential integrity in two different ways. DRI that we just saw is the most basic yet least flexible way. The other way is to use Triggers. We can write a Delete Trigger on the primary table that either deletes the rows in the dependent table(s) or sets all corresponding foreign keys to NULL (In our case the foreign keys are Non-Nullable so it has to delete the dependent rows). Source Code
Click here to download the source code for the one-to-one foreign key association sample that we have built in this post.Summary
In this post we learned about one-to-one foreign key associations as a better way to create one to one relationships. We saw some limitations such as the need for manual creation of unique constraints and also the fact that this type of association cannot be bidirectional, all due to the lack of unique constraint support in EF. The good news is that the ADO.NET team is working on enabling unique constraints in EF but support for unique constraints requires changes to the whole EF stack which won't happen until the next major release of EF (EF 4.1 is merely layered on top of the current .NET 4.0 functionality) and until then the workaround that I showed here is going to be the way to implement one-to-one foreign key associations in EF Code First. -
Associations in EF Code First: Part 4 – Table Splitting
This is the fourth post in a series that explains entity association mappings with EF Code First. This series includes: In the second part of this series we saw how to map a special kind of one-to-one association—a composition with complex types. We argued that this is usually the simplest way to represent one-to-one relationships which comes with some limitations. We addressed the first limitation (shared references) by introducing shared primary key associations in the previous blog post. In today’s blog post we are going to address the third limitation of the complex types by learning about Table Splitting as yet another way to map a one-to-one association. The Motivation Behind this Mapping: A Complex Type That Can be Lazy Loaded
A shared primary key association does not expose us to the third limitation of the complex types regarding Lazy Loading, we can of course lazy/defer load the Address information of a given user but at the same time, it does not give us the same SQL schema as the complex type mapping. After all, it adds a new table for the Address entity to the schema while mapping the Address with a complex type stores the address information in the Users table. So the question still remains there: How can we keep everything (e.g. User and Address) in one single table yet be able to lazy load the complex type part (Address) after reading the principal entity (User)? In other words, how can we have lazy loading with a complex type?Splitting a Single Table into Multiple Entities
Table splitting (a.k.a. horizontal splitting) enables us to map a single table to multiple entities. This is particularly useful for scenarios that we have a table with many columns where some of those columns might not be needed as frequently as others or some of the columns are expensive to load (e.g. a column with a binary data type).An Example From the Northwind Database
Unlike the other parts of this series, where we start with an object model and then derive a SQL schema afterwards, in this post we are going to do the reverse, for a reason that you'll see, we will start with an existing schema and will try to create an object model that matches the schema. For that we are going to use the Employees table from the Northwind database. You can download and install Northwind database from here If you don't have it already installed on your SQL Server. The following shows the Employees table from the Northwind database that we are going to use:
As you can see, this table has a Photo column of image type which makes it a good candidate to be lazy loaded each time we read an Employee from this table. The Object Model
As the following object model shows, I created two entities: Employee and EmployeePhoto. I also created a unidirectional association between these two by defining a navigation property on the Employee class called EmployeePhoto:public class Employee { public int EmployeeID { get; set; } public string LastName { get; set; } public string FirstName { get; set; } public string Title { get; set; } public string TitleOfCourtesy { get; set; } public DateTime? BirthDate { get; set; } public DateTime? HireDate { get; set; } public string Address { get; set; } public string City { get; set; } public string Region { get; set; } public string PostalCode { get; set; } public string Country { get; set; } public string HomePhone { get; set; } public string Extension { get; set; } public string Notes { get; set; } public int? ReportsTo { get; set; } public virtual EmployeePhoto EmployeePhoto { get; set; } } public class EmployeePhoto { [Key] public int EmployeeID { get; set; } public byte[] Photo { get; set; } public string PhotoPath { get; set; } } public class NorthwindContext : DbContext { public DbSet<Employee> Employees { get; set; } public DbSet<EmployeePhoto> EmployeePhoto { get; set; } }
How to Create a Table Splitting with Fluent API?
As also mentioned in the previous post, by convention, Code First always takes a unidirectional association as one-to-many unless we specify otherwise with fluent API. However, the fluent API codes that we have seen so far in this series won't let us create a table splitting. If we mark EmployeePhoto class as a complex type, we wouldn't be able to lazy load it anymore or if we create a shared primary key association then it will look for a separate table for the EmployeePhoto entity which we don't have in the Northwind database. The trick is to create a shared primary key association between Employee and EmployeePhoto entities but then instruct Code First to map them both to the same table. The following code shows how:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<Employee>() .HasRequired(e => e.EmployeePhoto) .WithRequiredPrincipal(); modelBuilder.Entity<Employee>().ToTable("Employees"); modelBuilder.Entity<EmployeePhoto>().ToTable("Employees"); }
Note how we made both ends of the association required by using HasRequired and WithRequiredPrincipal methods, even though both the Photo and PhotoPath columns has been defined to allow NULLs. See the Lazy Loading of the Dependent Entity in Action
Now it's time to write a test to make sure that EF does not select the Photo column each time we query for an employee:using (var context = new NorthwindContext()) { Employee employee = context.Employees.First(); byte[] photo = employee.EmployeePhoto.Photo; }
The following screen shot from the SQL Profiler shows the query that has been submitted to SQL Server as the result of reading the first employee object: 
Accessing the EmployeePhoto navigation property of the employee object on the next line causes EF to submit a second query to the SQL Server to lazy (implicit) load the EmployeePhoto (By default, EF fetches associated objects and collections lazily whenever you access them): 
Where to Use this Mapping?
I recommend using Table Splitting only for mapping of the legacy databases, actually that's the reason we start this post from an existing database like Northwind. For green-field development scenarios consider using shared primary key association instead. There are several reasons why you may want to split the Employee table to two tables when designing a new physical data model for your application. In fact, it is very common for most applications to require a core collection of data attributes of any given entity, and then a specific subset of the noncore data attributes. For example, the core columns of the Employee table would include the columns required to store their name, address, and phone numbers; whereas noncore columns would include the Photo column. Because Employee.Photo is large, and required only by a few applications, you would want to consider splitting it off into its own table. This would help to improve retrieval access times for applications that select all columns from the Employee table yet do not require the photo. This also works pretty well for EF since it doesn't support lazy loading at the scalar property or complex type level.Summary
In this post we learned about mapping a one-to-one association with table splitting. It enabled us to have lazy loading for the EmployeePhoto entity, something that we would have missed, had we mapped it with a complex type. We saw that on the database side it looks like a complex type mapping but on the object model it is not a complex type since we mapped EmployeePhoto as an Entity with an object identifier (EmployeeID). In fact, it's a special kind of a shared primary key association where both the principal and dependent entities are mapped to one single table. This somehow exotic one-to-one association mapping should be reserved only for the mapping of existing legacy databases. -
Associations in EF Code First: Part 3 – Shared Primary Key Associations
This is the third post in a series that explains entity association mappings with EF Code First. This series includes: - Part 1 – Introduction and Basic Concepts
- Part 2 – Complex Types
- Part 3 – Shared Primary Key Associations
- Part 4 – Table Splitting
- Part 5 – One-to-One Foreign Key Associations
- Part 6 – Many-valued Associations
In the previous blog post I demonstrated how to map a special kind of one-to-one association—a composition with complex types. We argued that the relationship between User and Address is best represented with a complex type mapping and we saw that this is usually the simplest way to represent one-to-one relationships but comes with some limitations.
In today’s blog post I’m going to discuss how we can address those limitations by changing our mapping strategy. This is particularly useful for scenarios that we want a dedicated table for Address, so that we can map both User and Address as entities. One benefit of this model is the possibility for shared references— another entity class (let’s say Shipment) can also have a reference to a particular Address instance. If a User has a reference to this instance, as her BillingAddress, the Address instance has to support shared references and needs its own identity. In this case, User and Address classes have a true one-to-one association.Introducing the Revised Model
In this revised version, each User could have one BillingAddress (Billing Association). Also a Shipment always needs a destination address for delivery (Delivery Association). The following shows the class diagram for this domain model (note the multiplicities on association lines):
In this model we assumed that the billing address of the user is the same as her delivery address. Now let’s create the association mappings for this domain model. There are several choices, the first being a One-to-One Primary Key Association. Shared Primary Key Associations
Also know as One-to-One Primary Key Associations, means two related tables share the same primary key values. The primary key of one table is also a foreign key of the other. Let’s see how we can create a primary key association mapping with Code First.How to Implement a One-to-One Primary Key Association with Code First
First, we start with the POCO classes. As you can see, we've defined BillingAddress as a navigation property on User class and another one on Shipment class named DeliveryAddress. Both associations are unidirectional since we didn't define related navigation properties on Address class as for User and Shipment.public class User { public int UserId { get; set; } public string Name { get; set; } public virtual Address BillingAddress { get; set; } } public class Address { public int AddressId { get; set; } public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } } public class Shipment { public int ShipmentId { get; set; } public string State { get; set; } public virtual Address DeliveryAddress { get; set; } } public class Context : DbContext { public DbSet<User> Users { get; set; } public DbSet<Address> Addresses { get; set; } public DbSet<Shipment> Shipments { get; set; } }
How Code First Sees the Associations in our Object Model: One-to-Many
Code First reads the model and tries to figure out the multiplicity of the associations. Since the associations are unidirectional, Code First takes this as if one Address has many Users and Many Shipments and will create a one-to-many association for each of them. In other words, a unidirectional association is always inferred as One-to-Many by Code First. So, what we were hoping for —a one-to-one association, is not inline with the Code First conventions.How to Change the Multiplicity of the Associations to One-to-One by Using the Conventions
Obviously, one way to turn our associations to one-to-one is by making them bidirectional. That is, adding a new navigation property to Address class of type User and another one of type Shipment. By doing that we simply signal Code First that we are looking to have one-to-one associations since for example User has an Address and also Address has a User. Therefore, Code First will change the multiplicity to one-to-one and this will solve the problem.Should We Make the Associations Bidirectional?
As always, the decision is up to us and depends on whether we need to navigate through our objects in that direction in the application code. In this case, we’d probably conclude that the bidirectional association doesn’t make much sense. If we call anAddress.User, we are saying “give me the user who has this address”, not a very reasonable request. So this is not a good option. Instead we'll keep our object model as it is and will explicitly ask Code First to make our associations one-to-one.How to Change the Multiplicity to One-to-One with Fluent API
The following code is all that is needed to make the associations to be one-to-one. Note how the multiplicities in the UML class diagram (e.g. 1 on User and 0..1 on address) has been translated to the fluent API code by using HasRequired and HasOptional methods:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress) .WithRequired(); modelBuilder.Entity<Shipment>().HasRequired(u => u.DeliveryAddress) .WithOptional(); }
Also it worth noting that when we are mapping a one-to-one association with fluent API, we don't need to specify the foreign key as we would do when mapping a one-to-many association with HasForeignKey method. Since EF only supports one-to-one associations on primary keys, it will automatically create the relationship in the database on the primary keys. Database Schema
The mapping result for our object model is as follows (note the Identity column on Users table):
Referential Integrity
In relational database design the referential integrity rule states that each non-null value of a foreign key must match the value of some primary key. But wait, how does it even applies here? All we have is just three primary keys referencing each other! Who is the primary key and who is the foreign key? The best way to find the answer of this question is to take a look at the properties of the relationships in the database that has been created by Code First:

As you can see, Code First adds a foreign key constraint which links the primary key of the Addresses table to the primary key of the Users table and adds another foreign key constraint that links the primary key of the Shipments table to the primary key of the Addresses table. The foreign key constraint means that a user has to exist for a particular address but not the other way around. In other words, the database guarantees that an Addresses row’s primary key references a valid Users primary key and a Shipments row’s primary key references a valid Addresses primary key. How Code First Determines the Principal and Dependent Ends in an Association?
Code First has rules to determine the principal and dependent ends of an association. For one-to-many relationships the many end is always the dependent, but it gets a little tricky in one-to-one associations. In one-to-one associations Code First decides based on our object model, and possible data annotations or fluent API code that we may have. For example in this case, we used the following fluent API code to configure the User-Address association:modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress).WithRequired();This reads as "User entity has an optional association with one Address object but this association is required for Address entity". For Code First this is good enough to make the decision: It marked User as the principal end and Address as the dependent end in the association. Since we have the same fluent API code for the second association between Address and Shipment, it marks Address as the principal end and Shipment as the dependent end in this association as well.
This decision has some consequences. In fact, the referential integrity that we saw, is the first result of this Code First's principal/dependent decision.Second Result of Code First's Principal/Dependent Decision: Database Identity
If you take a closer look at the above DB schema, you'll notice that only UserId has a regular identifier generator (aka Identity or Sequence) and AddressId and ShipmentId does not. This is a very important consequence of the principal/dependent decision for one-to-one associations: the dependent primary key will become non-Identity by default. This make sense because they share their primary key values and only one of them can be auto generated and we need to take care of providing valid keys for the rest.What about Cascade Deletes?
As we saw, each Address always belongs to one User and each Shipment always delivered to one single Address. We want to make sure that when we delete a User the possible dependent rows on Address and Shipment also get deleted in the database. In fact, this is one of the Referential Integrity Refactorings which called Introduce Cascading Delete. The primary reason we would apply "Introduce Cascading Delete" is to preserve the referential integrity of our data by ensuring that related rows are appropriately deleted when a parent row is deleted. By default, Code First does not enable cascade delete when it creates a one-to-one relationship in the database. As always we can override this convention by fluent API:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress) .WithRequired() .WillCascadeOnDelete(); modelBuilder.Entity<Shipment>().HasRequired(u => u.DeliveryAddress) .WithOptional() .WillCascadeOnDelete(); }
What the Additional Methods Like WithRequiredDependent are for?
The HasRequired method returns an object of type RequiredNavigationPropertyConfiguration which defines two special methods called WithRequiredDependent and WithRequiredPrincipal in addition to the typical WithMany and WithOptional methods that we usually use. We saw that the only reason Code First could figure out principal and dependent in our associations was because our fluent API code clearly specified one end as Required and the other as Optional. But what if both endpoints are required or both are optional in the association? For example consider a scenario that a User always has one Address and Address always has one User (required on both end). Now Code First cannot pick up the principal and dependent ends on its own and that's exactly where methods like WithRequiredDependent come into play. In other words, this scenario ultimately need to be configured by fluent API and fluent API is designed in a way that will force you to explicitly specify who is dependent and who is principal in a required-required or optional-optional association scenario.
For example, this fluent API code shows how we can configure the User-Address association where both ends are required:modelBuilder.Entity<User>().HasRequired(u => u.BillingAddress).WithRequiredDependent();Taking a closer look at the RequiredNavigationPropertyConfiguration type also shows the idea: public class RequiredNavigationPropertyConfiguration<TEntityType, TTargetEntityType> { public DependentNavigationPropertyConfiguration<TEntityType, TTargetEntityType> WithMany(); public CascadableNavigationPropertyConfiguration WithOptional(); public CascadableNavigationPropertyConfiguration WithRequiredDependent(); public CascadableNavigationPropertyConfiguration WithRequiredPrincipal(); }
As you can see, if you want to go another Required after HasRequired method, you have to either call WithRequiredDependent or WithRequiredPrincipal since there is no WithRequired method defined on RequiredNavigationPropertyConfiguration class. Working with the Model
Here is an example for adding a new user along with its billing address. EF is smart enough to use the newly generated UserId for the AddressId as well:using (var context = new Context()) { Address billingAddress = new Address() { Street = "Main St.", City = "Seattle" }; User user = new User() { Name = "Morteza", BillingAddress = billingAddress }; context.Users.Add(user); context.SaveChanges(); }
The following code is an example of adding a new Address and Shipment for an existing User (assuming that we have a User with UserId = 1 in the database): using (var context = new Context()) { Address deliveryAddress = new Address() { AddressId = 1, Street = "Main St.", }; Shipment shipment = new Shipment() { ShipmentId = 1, State = "Shipped", DeliveryAddress = deliveryAddress }; context.Shipments.Add(shipment); context.SaveChanges(); }
Limitations of This Mapping
There are two important limitations to associations mapped as shared primary key:- Difficulty in Saving Related Objects The main difficulty with this approach is ensuring that associated instances are assigned the same primary key value when the objects are saved. For example, when adding a new Address object, it's our responsibility to provide a unique AddressId that is also valid (a User can be found with such a value as UserId.)
- Multiple Addresses for User is Not Possible With this mapping we cannot have more than one Address for User. At the beginning of this post, when we introduce our model, we assumed that the user has the same address for billing and delivery. But what if that's not the case? What if we also want to add a Home address to User for the deliveries? In the current setup, each row in the User table has at most one corresponding row in the Address table. Two addresses would require an additional address table, and this mapping style therefore wouldn’t be adequate.
Summary
In this post we learned about one-to-one associations which shared primary key is just one way to implement it. Shared primary key associations aren’t uncommon but are relatively rare. In many schemas, a one-to-one association is represented with a foreign key field and a unique constraint. In the next posts we will revisit the same domain model and will learn about other ways to map one-to-one associations that does not have the limitations of the shared primary key association mapping.References
-
Associations in EF Code First: Part 2 – Complex Types
This is the second post in a series that explains entity association mappings with EF Code First. This series includes: - Part 1 – Introduction and Basic Concepts
- Part 2 – Complex Types
- Part 3 – Shared Primary Key Associations
- Part 4 – Table Splitting
- Part 5 – One-to-One Foreign Key Associations
- Part 6 – Many-valued Associations
Introducing the Model
First, let's review the model that we are going to use in order to create a Complex Type with EF Code First. It's a simple object model which consists of two classes: User and Address. Each user could have one billing address (or nothing at all–note the multiplicities on the class diagram). The Address information of a User is modeled as a separate class as you can see in the class diagram below:
In object-modeling terms, this association is a kind of aggregation—a part-of relationship. Aggregation is a strong form of association; it has some additional semantics with regard to the lifecycle of objects. In this case, we have an even stronger form, composition, where the lifecycle of the part is fully dependent upon the lifecycle of the whole. Fine-grained Domain Models
The motivation behind this design was to achieve Fine-grained domain models. In crude terms, fine-grained means more classes than tables. For example, a user may have both a billing address and a home address. In the database, you may have a single Users table with the columns BillingStreet, BillingCity, and BillingZipCode along with HomeStreet, HomeCity, and HomeZipCode. There are good reasons to use this somewhat denormalized relational model (performance, for one). In our object model, we can use the same approach, representing the two addresses as six string-valued properties of the User class. But it’s much better to model this using an Address class, where User has the BillingAddress and HomeAddress properties. This object model achieves improved cohesion and greater code reuse and is more understandable.Complex Types are Objects with No Identity
When it comes to the actual C# implementation, there is no difference between this composition and other weaker styles of association but in the context of ORM, there is a big difference: A composed class is often a candidate Complex Type (aka Value Object). But C# has no concept of composition—a class or property can’t be marked as a composition. The only difference is the object identifier: a complex type has no individual identity (e.g. there is no AddressId defined on Address class) which make sense because when it comes to the database everything is going to be saved into one single table.
Complex Type Discovery
Code First has a concept of Complex Type Discovery that works based on a set of Conventions. The convention is that if Code First discovers a class where a primary key cannot be inferred, and no primary key is registered through Data Annotations or the fluent API, then the type will be automatically registered as a complex type. Complex type detection also requires that the type does not have properties that reference entity types (i.e. all the properties must be scalar types) and is not referenced from a collection property on another type.How to Implement a Complex Type with EF Code First
The following shows the implementation of the introduced model in Code First:public class User { public int UserId { get; set; } public string Name { get; set; } public Address Address { get; set; } } public class Address { public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } } public class Context : DbContext { public DbSet<User> Users { get; set; } }
With code first, this is all of the code we need to write to create a complex type, we do not need to configure any additional database schema mapping information through Data Annotations or the fluent API. Complex Types: Splitting a Table Across Multiple Types
The mapping result for this object model is as follows (Note how Code First prefixes the complex type's column names with the name of the complex type):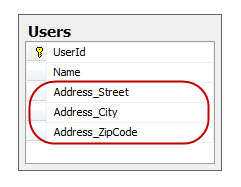
Complex Types are Required
As a limitation of EF in general, complex types are always considered required. To see this limitation in action, let's try to add a record to the Users table:using (var context = new Context()) { User user = new User() { Name = "Morteza" }; context.Users.Add(user); context.SaveChanges(); }
Surprisingly, this code throws a System.Data.UpdateException at runtime with this message: Null value for non-nullable member. Member: 'Address'.If we initialize the address object, the exception would go away and the user will be successfully saved into the database: 
Now if we read back the inserted record from the database, EF will return an Address object with Null values on all of its properties (Street, City and ZipCode). This means that even when you store a complex type object with all null property values, EF still returns an initialized complex type when the owning entity (e.g. User) is retrieved from the database. Explicitly Register a Type as Complex
You saw that in our model, we did not use any data annotation or fluent API code to designate the Address as a complex type, yet Code First detects it as a complex type based on Complex Type Discovery. But what if our domain model requires a new property like "Id" on Address class? This new Id property is just another scalar non-primary key property that represents let's say another piece of information about Address. Now Code First can (and will) infer a key and therefore marks Address as an entity that has its own mapping table unless we specify otherwise. This is where explicit complex type registration comes into play. There are two ways to register a type as complex:- Using Data Annotations
EF 4.1 introduces a new attribute in System.ComponentModel.DataAnnotations namespace called ComplexTypeAttribute. All we need to do is to place this attribute on our Address class:[ComplexType] public class Address { public string Id { get; set; } public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } }
This will keep Address as a complex type in our model despite its Id property. - Using Fluent API
Alternatively, we can use ComplexType generic method defined on DbModelBuilder class to register our Address type as complex:protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.ComplexType<Address>(); }
Best Practices When Working with Complex Types
- Always Initialize the Complex Type: Because of the problem we saw, I recommended always initialize the complex type inside its owning entity's constructor.
- Add a Read Only Property to the Complex Type for Null Value Checking: Defining a non-persistent read only property like HasValue will help to test for null values.
- Consider Always Explicitly Registering a ComplexType: Even if your class is automatically detected as a complex type by Code First, I still recommend to mark it with ComplexTypeAttribute. Not only that helps your object model to be more readable but also ensures that your complex types will stay as complex as your model evolves in your project. Of course if you have a domain layer then you should use the fluent API's ComplexType method instead since coupling your POCO domain model to the EntityFramework assembly (where ComplexTypeAttribute lives) is the last thing you want to do in your layered architecture!
public class User { public User() { Address = new Address(); } public int UserId { get; set; } public string Name { get; set; } public Address Address { get; set; } } [ComplexType] public class Address { public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } public bool HasValue { get { return (Street != null || ZipCode != null || City != null); } } }
The interesting point is that we did not have to explicitly exclude the HasValue property from the mapping above. Since HasValue has been defined as a read only property (i.e. there is no setter), EF Code First will be ignoring it based on conventions, which makes sense since a read only property is most probably representing a computed value and does not need to be persisted in the database. Customize Complex Type's Property Mappings at Entity Level
We can customize the individual property mappings of the complex type. For example, The Users table now contains, among others, the columns Address_Street, Address_PostalCode, and Address_City. We can rename these with ColumnAttribute:public class Address { [Column("Street")] public string Street { get; set; } public string City { get; set; } public string PostalCode { get; set; } }
Fluent API can give us the same result as well: protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.ComplexType<Address>() .Property(a => a.Street) .HasColumnName("Street"); }
Any other entity table that contains complex type fields (say, a Customer class that also has an Address) uses the same column options. Sometimes we’ll want to override the settings we made inside the complex type from outside for a particular entity. This is often the case when we try to derive an object model from a legacy database. For example, here is how we can rename the Address columns for Customer class: public class User { public int UserId { get; set; } public string Name { get; set; } public Address Address { get; set; } } public class Customer { public int CustomerId { get; set; } public string PhoneNumber { get; set; } public Address Address { get; set; } } [ComplexType] public class Address { [Column("Street")] public string Street { get; set; } public string City { get; set; } public string ZipCode { get; set; } } public class Context : DbContext { public DbSet<User> Users { get; set; } public DbSet<Customer> Customers { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<Customer>() .Property(c => c.Address.Street) .HasColumnName("Customer_Street"); } }
Complex Types and the New Change Tracking API
As part of the new DbContext API, EF 4.1 came with a new set of change tracking API that enables us to access Original and Current values of our entities. The Original Values are the values the entity had when it was queried from the database. The Current Values are the values the entity has now. This feature also fully supports complex types.
The entry point for accessing the new change tracking API is DbContext's Entry method which returns an object of type DbEntityEntry. DbEntityEntry contains a ComplexProperty method that returns a DbComplexPropertyEntry object where we can access the original and current values:using (var context = new Context()) { var user = context.Users.Find(1); Address originalValues = context.Entry(user) .ComplexProperty(u => u.Address) .OriginalValue; Address currentValues = context.Entry(user) .ComplexProperty(u => u.Address) .CurrentValue; }
Also we can drill down into the complex object and read or set properties of it using chained calls: string city = context.Entry(user) .ComplexProperty(u => u.Address) .Property(a => a.City) .CurrentValue;We can even get the nested properties using a single lambda expression: string city = context.Entry(user) .Property(u => u.Address.City) .CurrentValue;Limitations of This Mapping
There are three important limitations to classes mapped as Complex Types:- Shared References is Not Possible:
The Address Complex Type doesn’t have its own database identity (primary key) and so can’t be referred to by any object other than the containing instance of User (e.g. a Shipping class that also needs to reference the same User Address, cannot do so).- No Elegant Way to Represent a Null Reference:
As we saw there is no elegant way to represent a null reference to an Address. When reading from database, EF Code First always initialize Address object even if values in all mapped columns of the complex type are null.- Lazy Loading of Complex Types is Not Possible:
Note that EF always initializes the property values of a complex type right away, when the entity instance that holds the complex object is loaded. EF does not support lazy loading for complex types (same limitation also exists if you want to have lazy loading for scalar properties of an entity). This is inconvenient when we have to deal with potentially large values (for example, a property of type byte[] on the Address complex type which has been mapped to a VARBINARY column on Users table and holds an image of the location described by the Address.).Summary
In this post we learned about fine-grained domain models which complex type is just one example of it. Fine-grained is fully supported by EF Code First and is known as the most important requirement for a rich domain model. Complex type is usually the simplest way to represent one-to-one relationships and because the lifecycle is almost always dependent in such a case, it’s either an aggregation or a composition in UML. In the next posts we will revisit the same domain model and will learn about other ways to map a one-to-one association that does not have the limitations of the complex types.References
-
Associations in EF Code First: Part 1 – Introduction and Basic Concepts
Earlier this month the data team shipped the Release Candidate of EF 4.1. The most exciting feature of EF 4.1 is Code First, a new development pattern for EF which provides a really elegant and powerful code-centric way to work with data as well as an alternative to the existing Database First and Model First patterns. Code First is designed based on Convention over Configuration paradigm and focused around defining your model using C#/VB.NET classes, these classes can then be mapped to an existing database or be used to generate a database schema. Additional configuration can be supplied using Data Annotations or via a fluent API.
I’m a big fan of the EF Code First approach, and wrote several blog posts about it based on its CTP5 build:- Associations in EF Code First CTP5: Part 1 – Complex Types
- Associations in EF Code First CTP5: Part 2 – Shared Primary Key Associations
- Associations in EF Code First CTP5: Part 3 – One-to-One Foreign Key Associations
- Inheritance with EF Code First CTP5: Part 1 – Table per Hierarchy (TPH)
- Inheritance with EF Code First CTP5: Part 2 – Table per Type (TPT)
- Inheritance with EF Code First CTP5: Part 3 – Table per Concrete Type (TPC)
A Note For Those Who are New to EF and Code-First
If you choose to learn EF you've chosen well. If you choose to learn EF with Code First you've done even better. To get started, you can find an EF 4.1 Code First walkthrough by ADO.NET team here. In this series, I assume you already setup your machine to do Code First development and also that you are familiar with Code First fundamentals and basic concepts.Code First And Associations
I will start my EF 4.1 Code First articles by a series on entity association mappings. You will see that when it comes to associations, Code First brings ultimate power and flexibility. This series will come in several parts including:- Part 1 – Introduction and Basic Concepts
- Part 2 – Complex Types
- Part 3 – Shared Primary Key Associations
- Part 4 – Table Splitting
- Part 5 – One-to-One Foreign Key Associations
- Part 6 – Many-valued Associations
Why Starting with Association Mappings?
From my experience with the EF user community, I know that the first thing many developers try to do when they begin using EF (specially when having a Code First approach) is a mapping of a parent/children relationship. This is usually the first time you encounter collections. It’s also the first time you have to think about the differences between entities and value types, or the type of relationships between your entities. Managing the associations between classes and the relationships between tables is at the heart of ORM. Most of the difficult problems involved in implementing an ORM solution relate to association management.
In order to build a solid foundation for our discussion, we will start by learning about some of the core concepts around the relationship mapping and will leave the discussion for each type of entity associations to the next posts in this series.What is Mapping?
Mapping is the act of determining how objects and their relationships are persisted in permanent data storage, in our case, relational databases.What is Relationship Mapping?
A mapping that describes how to persist a relationship (association, aggregation, or composition) between two or more objects.Types of Relationships
There are two categories of object relationships that we need to be concerned with when mapping associations. The first category is based on multiplicity and it includes three types:- One-to-one relationships: This is a relationship where the maximums of each of its multiplicities is one.
- One-to-many relationships: Also known as a many-to-one relationship, this occurs when the maximum of one multiplicity is one and the other is greater than one.
- Many-to-many relationships: This is a relationship where the maximum of both multiplicities is greater than one.
- Uni-directional relationships: when an object knows about the object(s) it is related to but the other object(s) do not know of the original object. To put this in EF terminology, when a navigation property exists only on one of the association ends and not on the both.
- Bi-directional relationships: When the objects on both end of the relationship know of each other (i.e. a navigation property defined on both ends).
How Object Relationships are Implemented in POCO Object Models?
When the multiplicity is one (e.g. 0..1 or 1) the relationship is implemented by defining a navigation property that reference the other object (e.g. an Address property on User class). When the multiplicity is many (e.g. 0..*, 1..*) the relationship is implemented via an ICollection of the type of other object.How Relational Database Relationships are Implemented?
Relationships in relational databases are maintained through the use of Foreign Keys. A foreign key is a data attribute(s) that appears in one table and must be the primary key or other candidate key in another table. With a one-to-one relationship the foreign key needs to be implemented by one of the tables. To implement a one-to-many relationship we implement a foreign key from the “one table” to the “many table”. We could also choose to implement a one-to-many relationship via an associative table (aka Join table), effectively making it a many-to-many relationship.References
-
Associations in EF Code First CTP5: Part 3 – One-to-One Foreign Key Associations
This is the third post in a series that explains entity association mappings with EF Code First. I've described these association types so far: In the previous blog post we saw the limitations of shared primary key association and argued that this type of association is relatively rare and in many schemas, a one-to-one association is represented with a foreign key field and a unique constraint. Today we are going to discuss how this is done by learning about one-to-one foreign key associations. Introducing the Revised Model
In this revised version, each User always have two addresses: one billing address and another one for delivery. The following figure shows the class diagram for this domain model:
One-to-One Foreign Key Association
Instead of sharing a primary key, two rows can have a foreign key relationship. One table has a foreign key column that references the primary key of the associated table (The source and target of this foreign key constraint can even be the same table: This is called a self-referencing relationship.). An additional constraint enforces this relationship as a real one to one. For example, by making the BillingAddressId column unique, we declare that a particular address can be referenced by at most one user, as a billing address. This isn’t as strong as the guarantee from a shared primary key association, which allows a particular address to be referenced by at most one user, period. With several foreign key columns (which is the case in our domain model since we also have a foreign key for DeliveryAddress), we can reference the same address target row several times. But in any case, two users can’t share the same address for the same purpose.The Object Model
Let's start by creating an object model for our domain:public class User { public int UserId { get; set; } public string FirstName { get; set; } public string LastName { get; set; } public int BillingAddressId { get; set; } public int DeliveryAddressId { get; set; } public Address BillingAddress { get; set; } public Address DeliveryAddress { get; set; } } public class Address { public int AddressId { get; set; } public string Street { get; set; } public string City { get; set; } public string PostalCode { get; set; } } public class EntityMappingContext : DbContext { public DbSet<User> Users { get; set; } public DbSet<Address> Addresses { get; set; } }
As you can see, User class has introduced two new scalar properties as BillingAddressId and DeliveryAddressId as well as their related navigation properties (BillingAddress and DeliveryAddress). Configuring Foreign Keys With Fluent API
BillingAddressId and DeliveryAddressId are foreign key scalar properties and representing the actual foreign key values that the relationships are established on. However, Code First will not recognize them as the foreign keys for the associations since their names are not aligned with the conventions that it has to infer foreign keys. Therefore, we need to use fluent API (or Data Annotations) to tell Code First about the foreign keys. Here is the fluent API code to identify the foreign key properties:protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.Entity<User>() .HasRequired(a => a.BillingAddress) .WithMany() .HasForeignKey(u => u.BillingAddressId); modelBuilder.Entity<User>() .HasRequired(a => a.DeliveryAddress) .WithMany() .HasForeignKey(u => u.DeliveryAddressId); }
Alternatively, we can use Data Annotations to achieve this. CTP5 introduced a new attribute in System.ComponentModel.DataAnnotations namespace which is called ForeignKeyAttribute and we can place it on a navigation property to specify the property that represents the foreign key of the relationship: public class User { public int UserId { get; set; } public string FirstName { get; set; } public string LastName { get; set; } public int BillingAddressId { get; set; } public int DeliveryAddressId { get; set; } [ForeignKey("BillingAddressId")] public Address BillingAddress { get; set; } [ForeignKey("DeliveryAddressId")] public Address DeliveryAddress { get; set; } }
However, we will not use this Data Annotation and will stick with our fluent API code for a reason that you'll see soon. Creating a SQL Server Schema
The object model seems to be ready to give us the desired SQL schema, however, if we try to create a SQL Server database from it, we will get an InvalidOperationException with this message:"The database creation succeeded, but the creation of the database objects did not. See InnerException for details."The inner exception is a System.Data.SqlClient.SqlException containing this message: "Introducing FOREIGN KEY constraint 'User_DeliveryAddress' on table 'Users' may cause cycles or multiple cascade paths. Specify ON DELETE NO ACTION or ON UPDATE NO ACTION, or modify other FOREIGN KEY constraints. Could not create constraint. See previous errors."As you can tell from the type of the inner exception (SqlException), it has nothing to do with EF or Code First; it has been generated purely by SQL Server when Code First was trying to create a database based on our object model. SQL Server and Multiple Cascade Paths
A Multiple cascade path happens when a cascade path goes from column col1 in table A to table B and also from column col2 in table A to table B. So it seems that Code First tried to turn on Cascade Delete for both BillingAddressId and DeliveryAddressId columns in Users table. In fact, Code First was trying to use Declarative Referential Integrity (DRI) to enforce cascade deletes and the problem is that SQL Server is not fully ANSI SQL-92 compliant when it comes to the cascading actions. In SQL Server, DRI forbids cascading updates or deletes in a multiple cascade path scenario.
A KB article also explains why we received this error: "In SQL Server, a table cannot appear more than one time in a list of all the cascading referential actions that are started by either a DELETE or an UPDATE statement. For example, the tree of cascading referential actions must only have one path to a particular table on the cascading referential actions tree". (i.e. the User table appeared twice in a list of cascading referential actions started by a DELETE). Basically, SQL Server does simple counting of cascade paths and, rather than trying to work out whether any cycles actually exist, it assumes the worst and refuses to create the referential actions (Cascades).
Therefore, depend on our database engine, we may or may not get this exception (For example, both Oracle and MySQL let us create Cascades in this scenario.).Overriding Code First Convention To Resolve the Problem
As you saw, Code First automatically turns on Cascade Deletes on required one-to-many associations based on the conventions. However, in order to resolve the exception that we got from SQL Server, we have no choice other than overriding this convention and switching cascade deletes off on at least one of the associations and as of CTP5, the only way to accomplish this is by using fluent API. Let's switch it off on DeliveryAddress Association:protected override void OnModelCreating(ModelBuilder modelBuilder) { modelBuilder.Entity<User>() .HasRequired(a => a.BillingAddress) .WithMany() .HasForeignKey(u => u.BillingAddressId); modelBuilder.Entity<User>() .HasRequired(a => a.DeliveryAddress) .WithMany() .HasForeignKey(u => u.DeliveryAddressId).WillCascadeOnDelete(false); }
One-to-One Foreign Key Associations in EF Code First
As you may have noticed, both associations in the fluent API code has been configured as a many-to-one—not one-to-one, as you might have expected. The reason is simple: Code First (and EF in general) does not natively support one-to-one foreign key associations. In fact, EF does not support any association scenario that involves unique constraints at all. Fortunately, in this case we don’t care what’s on the target side of the association, so we can treat it like a to-one association without the many part. All we want is to express “This entity (User) has a property that is a reference to an instance of another entity (Address)” and use a foreign key field to represent that relationship. Basically EF still thinks that the relationship is many-to-one. This is a workaround for the current EF limitation which comes with two consequences: First, EF won't create any additional constraint for us to enforces this relationship as a one to one, we need to manually create it ourselves. The second limitation that this lack of support impose to us is more important: one to one foreign key associations cannot be bidirectional (i.e. we cannot define a User property on the Address class).Create a Unique Constraint To Enforce the Relationship as a Real One to One
We can manually create unique constraints on the foreign keys in the database after Code First creates it for us but if you are like me and prefer to create your database in one shot then there is a way in CTP5 to have Code First create the constraints as part of its database creation process. For that we can take advantage of the new CTP5’s SqlCommand method on DbDatabase class which allows raw SQL commands to be executed against the database. The best place to invoke SqlCommand method for this purpose is inside a Seed method that has been overridden in a custom Initializer class:protected override void Seed(EntityMappingContext context) { context.Database.SqlCommand("ALTER TABLE Users ADD CONSTRAINT uc_Billing UNIQUE(BillingAddressId)"); context.Database.SqlCommand("ALTER TABLE Users ADD CONSTRAINT uc_Delivery UNIQUE(DeliveryAddressId)"); }
This code adds unique constraints to the BillingAddressId and DeliveryAddressId columns in the DDL generated by Code First. SQL Schema
The object model is ready now and Code First will create the following database schema for us:
It is worth mentioning that we can still enforce cascade deletes for DeliveryAddress relationship. SQL Server allows enforcing Referential Integrity in two different ways. DRI that we just saw is the most basic yet least flexible way. The other way is to use Triggers. We can write a Delete Triggers on the primary table that either deletes the rows in the dependent table(s) or sets all corresponding foreign keys to NULL (In our case the foreign keys are Non-Nullable so it has to delete the dependent rows). Download
Click here to download and run the one-to-one foreign key association sample that we have built in this blog post.Summary
In this blog post we learned about one-to-one foreign key associations as a better way to represent one to one relationships. However, we saw some limitations such as the need for manual creation of unique constraints and also the fact that these type of associations cannot be bidirectional, all due to the lack of unique constraint support in EF. Support for unique constraints is going to require changes to the whole EF stack and it won't happen in the RTM targeted for this year as that RTM will be layered on top of the current .NET 4.0 functionality. That said, EF team has this feature on their list for the future, so hopefully it will be supported in a later release of EF and until then the workaround that I showed here is going to be the way to implement one-to-one foreign key associations in EF Code First.References
-
Inheritance with EF Code First: Part 3 – Table per Concrete Type (TPC)
This is the third (and last) post in a series that explains different approaches to map an inheritance hierarchy with EF Code First. I've described these strategies in previous posts: In today’s blog post I am going to discuss Table per Concrete Type (TPC) which completes the inheritance mapping strategies supported by EF Code First. At the end of this post I will provide some guidelines to choose an inheritance strategy mainly based on what we've learned in this series. TPC and Entity Framework in the Past
Table per Concrete type is somehow the simplest approach suggested, yet using TPC with EF is one of those concepts that has not been covered very well so far and I've seen in some resources that it was even discouraged. The reason for that is just because Entity Data Model Designer in VS2010 doesn't support TPC (even though the EF runtime does). That basically means if you are following EF's Database-First or Model-First approaches then configuring TPC requires manually writing XML in the EDMX file which is not considered to be a fun practice. Well, no more. You'll see that with Code First, creating TPC is perfectly possible with fluent API just like other strategies and you don't need to avoid TPC due to the lack of designer support as you would probably do in other EF approaches.Table per Concrete Type (TPC)
In Table per Concrete type (aka Table per Concrete class) we use exactly one table for each (nonabstract) class. All properties of a class, including inherited properties, can be mapped to columns of this table, as shown in the following figure: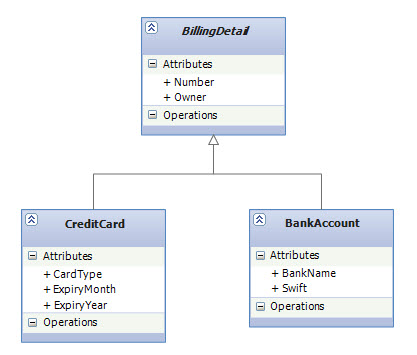
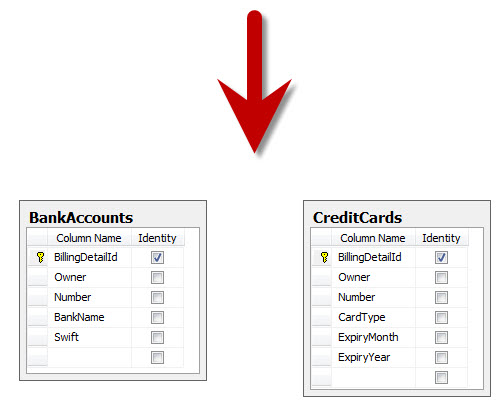
As you can see, the SQL schema is not aware of the inheritance; effectively, we’ve mapped two unrelated tables to a more expressive class structure. If the base class was concrete, then an additional table would be needed to hold instances of that class. I have to emphasize that there is no relationship between the database tables, except for the fact that they share some similar columns. TPC Implementation in Code First
Just like the TPT implementation, we need to specify a separate table for each of the subclasses. We also need to tell Code First that we want all of the inherited properties to be mapped as part of this table. In CTP5, there is a new helper method on EntityMappingConfiguration class called MapInheritedProperties that exactly does this for us. Here is the complete object model as well as the fluent API to create a TPC mapping:public abstract class BillingDetail { public int BillingDetailId { get; set; } public string Owner { get; set; } public string Number { get; set; } } public class BankAccount : BillingDetail { public string BankName { get; set; } public string Swift { get; set; } } public class CreditCard : BillingDetail { public int CardType { get; set; } public string ExpiryMonth { get; set; } public string ExpiryYear { get; set; } } public class InheritanceMappingContext : DbContext { public DbSet<BillingDetail> BillingDetails { get; set; } protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<BankAccount>().Map(m => { m.MapInheritedProperties(); m.ToTable("BankAccounts"); }); modelBuilder.Entity<CreditCard>().Map(m => { m.MapInheritedProperties(); m.ToTable("CreditCards"); }); } }
The Importance of EntityMappingConfiguration ClassAs a side note, it worth mentioning that EntityMappingConfiguration class turns out to be a key type for inheritance mapping in Code First. Here is an snapshot of this class:namespace System.Data.Entity.ModelConfiguration.Configuration.Mapping { public class EntityMappingConfiguration<TEntityType> where TEntityType : class { public ValueConditionConfiguration Requires(string discriminator); public void ToTable(string tableName); public void MapInheritedProperties(); } }
As you have seen so far, we used its Requires method to customize TPH. We also used its ToTable method to create a TPT and now we are using its MapInheritedProperties along with ToTable method to create our TPC mapping. TPC Configuration is Not Done Yet!
We are not quite done with our TPC configuration and there is more into this story even though the fluent API we saw perfectly created a TPC mapping for us in the database. To see why, let's start working with our object model. For example, the following code creates two new objects of BankAccount and CreditCard types and tries to add them to the database:using (var context = new InheritanceMappingContext()) { BankAccount bankAccount = new BankAccount(); CreditCard creditCard = new CreditCard() { CardType = 1 }; context.BillingDetails.Add(bankAccount); context.BillingDetails.Add(creditCard); context.SaveChanges(); }
Running this code throws an InvalidOperationException with this message: The changes to the database were committed successfully, but an error occurred while updating the object context. The ObjectContext might be in an inconsistent state. Inner exception message: AcceptChanges cannot continue because the object's key values conflict with another object in the ObjectStateManager. Make sure that the key values are unique before calling AcceptChanges.The reason we got this exception is because DbContext.SaveChanges() internally invokes SaveChanges method of its internal ObjectContext. ObjectContext's SaveChanges method on its turn by default calls AcceptAllChanges after it has performed the database modifications. AcceptAllChanges method merely iterates over all entries in ObjectStateManager and invokes AcceptChanges on each of them. Since the entities are in Added state, AcceptChanges method replaces their temporary EntityKey with a regular EntityKey based on the primary key values (i.e. BillingDetailId) that come back from the database and that's where the problem occurs since both the entities have been assigned the same value for their primary key by the database (i.e. on both BillingDetailId = 1) and the problem is that ObjectStateManager cannot track objects of the same type (i.e. BillingDetail) with the same EntityKey value hence it throws. If you take a closer look at the TPC's SQL schema above, you'll see why the database generated the same values for the primary keys: the BillingDetailId column in both BankAccounts and CreditCards table has been marked as identity. How to Solve The Identity Problem in TPC
As you saw, using SQL Server’s int identity columns doesn't work very well together with TPC since there will be duplicate entity keys when inserting in subclasses tables with all having the same identity seed. Therefore, to solve this, either a spread seed (where each table has its own initial seed value) will be needed, or a mechanism other than SQL Server’s int identity should be used. Some other RDBMSes have other mechanisms allowing a sequence (identity) to be shared by multiple tables, and something similar can be achieved with GUID keys in SQL Server. While using GUID keys, or int identity keys with different starting seeds will solve the problem but yet another solution would be to completely switch off identity on the primary key property. As a result, we need to take the responsibility of providing unique keys when inserting records to the database. We will go with this solution since it works regardless of which database engine is used.Switching Off Identity in Code First
We can switch off identity simply by placing DatabaseGenerated attribute on the primary key property and pass DatabaseGenerationOption.None to its constructor. DatabaseGenerated attribute is a new data annotation which has been added to System.ComponentModel.DataAnnotations namespace in CTP5:public abstract class BillingDetail { [DatabaseGenerated(DatabaseGenerationOption.None)] public int BillingDetailId { get; set; } public string Owner { get; set; } public string Number { get; set; } }
As always, we can achieve the same result by using fluent API, if you prefer that: modelBuilder.Entity<BillingDetail>() .Property(p => p.BillingDetailId) .HasDatabaseGenerationOption(DatabaseGenerationOption.None);
Working With The Object Model
Our TPC mapping is ready and we can try adding new records to the database. But, like I said, now we need to take care of providing unique keys when creating new objects:using (var context = new InheritanceMappingContext()) { BankAccount bankAccount = new BankAccount() { BillingDetailId = 1 }; CreditCard creditCard = new CreditCard() { BillingDetailId = 2, CardType = 1 }; context.BillingDetails.Add(bankAccount); context.BillingDetails.Add(creditCard); context.SaveChanges(); }
Polymorphic Associations with TPC is Problematic
The main problem with this approach is that it doesn’t support Polymorphic Associations very well. After all, in the database, associations are represented as foreign key relationships and in TPC, the subclasses are all mapped to different tables so a polymorphic association to their base class (abstract BillingDetail in our example) cannot be represented as a simple foreign key relationship. For example, consider the domain model we introduced here where User has a polymorphic association with BillingDetail. This would be problematic in our TPC Schema, because if User has a many-to-one relationship with BillingDetail, the Users table would need a single foreign key column, which would have to refer both concrete subclass tables. This isn’t possible with regular foreign key constraints.Schema Evolution with TPC is Complex
A further conceptual problem with this mapping strategy is that several different columns, of different tables, share exactly the same semantics. This makes schema evolution more complex. For example, a change to a base class property results in changes to multiple columns. It also makes it much more difficult to implement database integrity constraints that apply to all subclasses.Generated SQL
Let's examine SQL output for polymorphic queries in TPC mapping. For example, consider this polymorphic query for all BillingDetails and the resulting SQL statements that being executed in the database:var query = from b in context.BillingDetails select b;

Just like the SQL query generated by TPT mapping, the CASE statements that you see in the beginning of the query is merely to ensure columns that are irrelevant for a particular row have NULL values in the returning flattened table. (e.g. BankName for a row that represents a CreditCard type). TPC's SQL Queries are Union Based
As you can see in the above screenshot, the first SELECT uses a FROM-clause subquery (which is selected with a red rectangle) to retrieve all instances of BillingDetails from all concrete class tables. The tables are combined with a UNION operator, and a literal (in this case, 0 and 1) is inserted into the intermediate result; (look at the lines highlighted in yellow.) EF reads this to instantiate the correct class given the data from a particular row. A union requires that the queries that are combined, project over the same columns; hence, EF has to pad and fill up nonexistent columns with NULL. This query will really perform well since here we can let the database optimizer find the best execution plan to combine rows from several tables. There is also no Joins involved so it has a better performance than the SQL queries generated by TPT where a Join is required between the base and subclasses tables.Choosing Strategy Guidelines
Before we get into this discussion, I want to emphasize that there is no one single "best strategy fits all scenarios" exists. As you saw, each of the approaches have their own advantages and drawbacks. Here are some rules of thumb to identify the best strategy in a particular scenario:- If you don’t require polymorphic associations or queries, lean toward TPC—in other words, if you never or rarely query for BillingDetails and you have no class that has an association to BillingDetail base class. I recommend TPC (only) for the top level of your class hierarchy, where polymorphism isn’t usually required, and when modification of the base class in the future is unlikely.
- If you do require polymorphic associations or queries, and subclasses declare relatively few properties (particularly if the main difference between subclasses is in their behavior), lean toward TPH. Your goal is to minimize the number of nullable columns and to convince yourself (and your DBA) that a denormalized schema won’t create problems in the long run.
- If you do require polymorphic associations or queries, and subclasses declare many properties (subclasses differ mainly by the data they hold), lean toward TPT. Or, depending on the width and depth of your inheritance hierarchy and the possible cost of joins versus unions, use TPC.
Summary
In this series, we focused on one of the main structural aspect of the object/relational paradigm mismatch which is inheritance and discussed how EF solve this problem as an ORM solution. We learned about the three well-known inheritance mapping strategies and their implementations in EF Code First. Hopefully it gives you a better insight about the mapping of inheritance hierarchies as well as choosing the best strategy for your particular scenario.
Happy New Year and Happy Code-Firsting!
References
-
Inheritance with EF Code First: Part 2 – Table per Type (TPT)
In the previous blog post you saw that there are three different approaches to representing an inheritance hierarchy and I explained Table per Hierarchy (TPH) as the default mapping strategy in EF Code First. We argued that the disadvantages of TPH may be too serious for our design since it results in denormalized schemas that can become a major burden in the long run. In today’s blog post we are going to learn about Table per Type (TPT) as another inheritance mapping strategy and we'll see that TPT doesn’t expose us to this problem. Table per Type (TPT)
Table per Type is about representing inheritance relationships as relational foreign key associations. Every class/subclass that declares persistent properties—including abstract classes—has its own table. The table for subclasses contains columns only for each noninherited property (each property declared by the subclass itself) along with a primary key that is also a foreign key of the base class table. This approach is shown in the following figure: 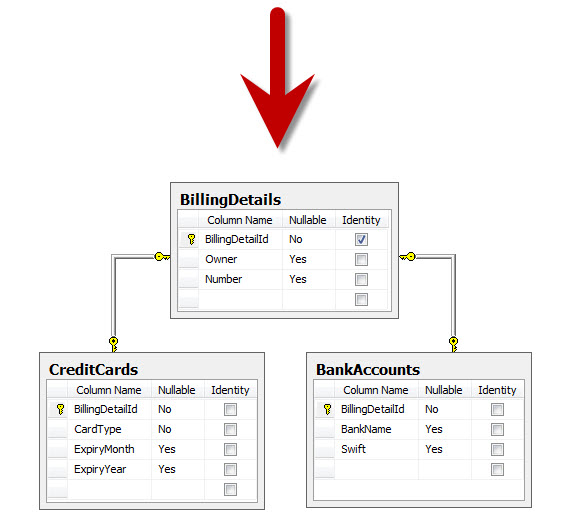
For example, if an instance of the CreditCard subclass is made persistent, the values of properties declared by the BillingDetail base class are persisted to a new row of the BillingDetails table. Only the values of properties declared by the subclass (i.e. CreditCard) are persisted to a new row of the CreditCards table. The two rows are linked together by their shared primary key value. Later, the subclass instance may be retrieved from the database by joining the subclass table with the base class table. TPT Advantages
The primary advantage of this strategy is that the SQL schema is normalized. In addition, schema evolution is straightforward (modifying the base class or adding a new subclass is just a matter of modify/add one table). Integrity constraint definition are also straightforward (note how CardType in CreditCards table is now a non-nullable column).Implement TPT in EF Code First
We can create a TPT mapping simply by placing Table attribute on the subclasses to specify the mapped table name (Table attribute is a new data annotation and has been added to System.ComponentModel.DataAnnotations namespace in CTP5):public abstract class BillingDetail { public int BillingDetailId { get; set; } public string Owner { get; set; } public string Number { get; set; } } [Table("BankAccounts")] public class BankAccount : BillingDetail { public string BankName { get; set; } public string Swift { get; set; } } [Table("CreditCards")] public class CreditCard : BillingDetail { public int CardType { get; set; } public string ExpiryMonth { get; set; } public string ExpiryYear { get; set; } } public class InheritanceMappingContext : DbContext { public DbSet<BillingDetail> BillingDetails { get; set; } }
If you prefer fluent API, then you can create a TPT mapping by using ToTable() method: protected override void OnModelCreating(DbModelBuilder modelBuilder) { modelBuilder.Entity<BankAccount>().ToTable("BankAccounts"); modelBuilder.Entity<CreditCard>().ToTable("CreditCards"); }
Polymorphic Associations
A polymorphic association is an association to a base class, hence to all classes in the hierarchy with dynamic resolution of the concrete class at runtime. For example, consider the BillingInfo property of User in the following domain model. It references one particular BillingDetail object, which at runtime can be any concrete instance of that class.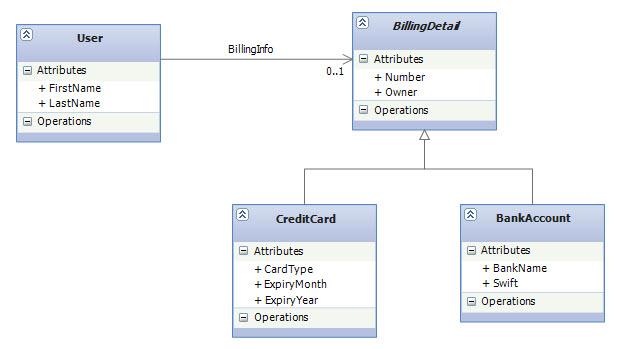
In fact, because BillingDetail is abstract, the association must refer to an instance of one of its subclasses only—CreditCard or BankAccount—at runtime. Implement Polymorphic Associations with EF Code First
We don’t have to do anything special to enable polymorphic associations in EF Code First; The user needs a unidirectional association to some BillingDetails, which can be CreditCard or BankAccount so we just create this association and it would be naturally polymorphic:public class User { public int UserId { get; set; } public string FirstName { get; set; } public string LastName { get; set; } public int BillingDetailId { get; set; } public virtual BillingDetail BillingInfo { get; set; } }
In other words, as you can see above, a polymorphic association is an association that may refer instances of a subclass of the class that was explicitly specified as the type of the navigation property (e.g. User.BillingInfo).
The following code demonstrates the creation of an association to an instance of the CreditCard subclass:using (var context = new InheritanceMappingContext()) { CreditCard creditCard = new CreditCard() { Number = "987654321", CardType = 1 }; User user = new User() { UserId = 1, BillingInfo = creditCard }; context.Users.Add(user); context.SaveChanges(); }
Now, if we navigate the association in a second context, EF Code First automatically retrieves the CreditCard instance: using (var context = new InheritanceMappingContext()) { User user = context.Users.Find(1); Debug.Assert(user.BillingInfo is CreditCard); }
Polymorphic Associations with TPT
Another important advantage of TPT is the ability to handle polymorphic associations. In the database a polymorphic association to a particular base class will be represented as a foreign key referencing the table of that particular base class. (e.g. Users table has a foreign key that references BillingDetails table.)Generated SQL For Queries
Let’s take an example of a simple non-polymorphic query that returns a list of all the BankAccounts:var query = from b in context.BillingDetails.OfType<BankAccount>() select b;
Executing this query (by invoking ToList() method) results in the following SQL statements being sent to the database (on the bottom, you can also see the result of executing the generated query in SQL Server Management Studio): 
Now, let’s take an example of a very simple polymorphic query that requests all the BillingDetails which includes both BankAccount and CreditCard types: var query = from b in context.BillingDetails select b;
This LINQ query seems even more simple than the previous one but the resulting SQL query is not as simple as you might expect: 
As you can see, EF Code First relies on an INNER JOIN to detect the existence (or absence) of rows in the subclass tables CreditCards and BankAccounts so it can determine the concrete subclass for a particular row of the BillingDetails table. Also the SQL CASE statements that you see in the beginning of the query is just to ensure columns that are irrelevant for a particular row have NULL values in the returning flattened table. (e.g. BankName for a row that represents a CreditCard type) TPT Considerations
Even though this mapping strategy is deceptively simple, the experience shows that performance can be unacceptable for complex class hierarchies because queries always require a join across many tables. In addition, this mapping strategy is more difficult to implement by hand— even ad-hoc reporting is more complex. This is an important consideration if you plan to use handwritten SQL in your application (For ad hoc reporting, database views provide a way to offset the complexity of the TPT strategy. A view may be used to transform the table-per-type model into the much simpler table-per-hierarchy model.)Summary
In this post we learned about Table per Type as the second inheritance mapping in our series. So far, the strategies we’ve discussed require extra consideration with regard to the SQL schema (e.g. in TPT, foreign keys are needed). This situation changes with the Table per Concrete Type (TPC) that we will discuss in the next post.
References