Mathew Nolton Blog
Software dementia unleashed...
-
sp_lock2 and sp_lockcount
Here are two helpful procedures to help with sqlserver database work.
-
SqlScript for dropping a set of procedures, user-defined functions or views
I have been wanting to write some posts lately of some productivity tools and tricks. My last post was for a VS-Addin for updating the reference paths for all "selected" projects in your visual solution set.
-
Add-In for updating all reference paths in a solution
Update Project References Add-In
Visual Studio doesn't natively support the ability to update all selected project's within a Solution with the same reference paths. This is important (at least to me) if you have to download from your source control system a different version of your source code. Since you typically do not check in your project preferences into source control, you will be stuck with the mundane task of selecting your project, setting the reference path, select the next project, etc.
This add-in enables you to select a given set of projects within your solution, set your reference paths and make updates across all selected projects. For example: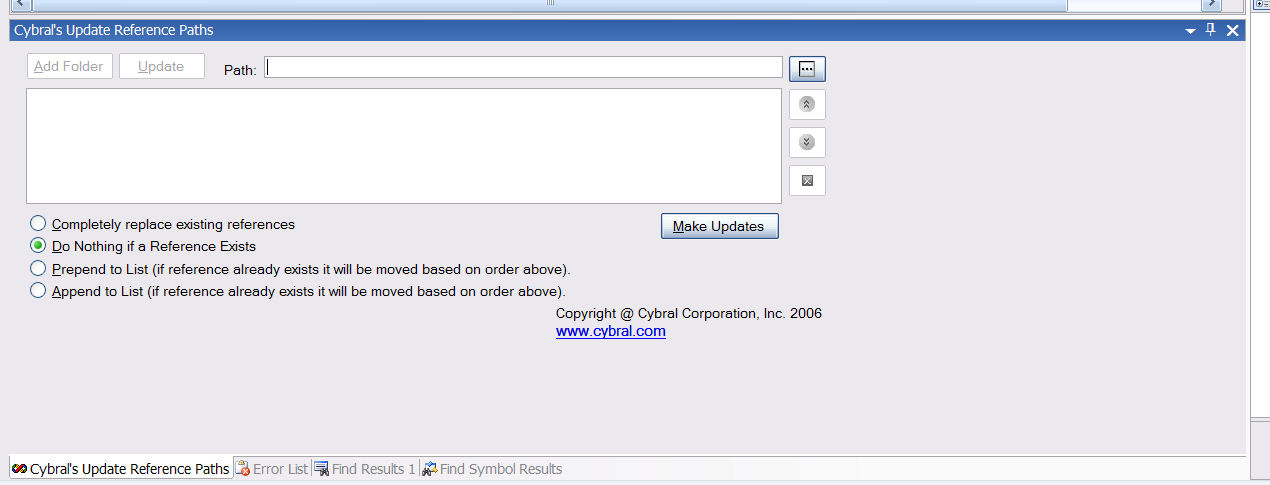
-
Using skmRss.RssFeed
I have been evaluating the use of Scott Mitchell's RSSFeed control for a new version of my website (it's not done yet) for my consulting company that focuses on the Cable Sector of the Telecommunications Industry and I wanted to display relevant information for both Web Services and the Cable Sector. The control is very nice (and free). During my investigation I wanted to perform a couple of actions that were not quickly apparent but still quite doable once I dug a bit deeper. Specifically, I wanted to be able to:
-
Creating your own XmlSerializer
Very recently I came across an issue that required the creation of a new class derived from XmlSerializer. For reasons I don't want to get into here, we serialize an object instance into XML and store it into a database column so that we can reconstitute it later. This is a great approach except for the issue of changing class definitions.
-
New Version of XmlPreCompiler
Well, I finally got around to making the XmlPreCompiler even easier to use. As some of you may or may not know, the XmlPreCompiler is a tool based on a tool Chris Sell's originally created to help developer's handle the xml serialization error:
-
Part 2: Consulting in the Cable and Wireless Sectors....The Power of the Bundle....
The Cable sector as well as the entire Telecommunications industry has been expending a large amount of resources to sell bundled products and services. This means that instead of just offering Analog and Digital Cable Services, Cable and Telecommunication Companies are offering Cable, High Speed Internet, Digital Telephone, Digital Video Recorders, High Definition TV, etc. in a "Bundled" product.
-
Part 1: Consulting in the Cable and Wireless Sectors
Part 1...Commerce Solutions:
-
Fail Fast
I found this paper about "Failing Fast" while reading Paul Lockwood's blog. It refers to Martin Fowler's wiki about writing code to Fail Fast. This technique has been around for a while; however, I honestly have always been more of a proponent of writing defensive code.
-
Too Funny. One of the best pranks ever.
A friend of mine who always seems to find pranks and funny minutia on the web came across this and sent it to me. It takes a few minutes to read it but well worth the time.