DotNetStories

In this post I am going to provide you with a hands-on example on how to avoid writing your LINQ to Entities queries in a way that will hinder performance of your application. The aim of this post (hopefully a series of posts on performance and Entity Framework) is to highlight bad coding practices when architecting an applications that uses EF as the ORM to fetch and manipulate data from the data store. I am going to point out some practises and patterns that very often developers use and cause EF to create poor-performing T-SQL statements.
Entity Framework will always create T-SQL, the thing to keep in mind is that we have to make sure that this T-SQL code (that we cannot write ourselves since it is abstracted by EF) if it is poor then when passed to the SQL Server engine (through the optimiser and the creation of the execution plan) will cause our applications to perform poorly especially under heavy load.
Let me talk a bit about query optimisation and T-SQL. T-SQL is declarative by nature. When we write T-SQL statements in a query window in SSMS and execute them,we just say to SQL Server “I want these results back”. We do not provide any details on how the results will be returned.If there was nothing else between our T-SQL code and the SQL Server Database engine, we simply would not get any results back.Luckily for us there is a very important component, the Query Optimizer that generates an imperative plan. By saying imperative I mean detailed. This plan that is called execution plan is what is actually executed by the relational engine.The query optimiser will not look for a perfect plan.It is a cost-based optimiser that must find an efficient plan.The optimiser when deciding upon the execution plan will take in to consideration the type of operations,statistics (must always be up to date),indexes,hardware resources (number of CPUs ,available memory),SQL Server edition,number of active concurrent connections and query hints. If the T-SQL that is generated by the EF is pooly written then the optimiser will not create an optimal plan hence the problems in performance.
Entity Framework is an object-relational mapping (ORM) framework for the .NET Framework.EF addresses the problem of Object-relational impedance mismatch. I will not be talking about that mismatch because it is well documented in many sites on the Internet.
Through that framework we can program against a conceptual application model instead of programming directly against a relational schema-model. By doing so we can decrease the amount of code we do write to access a data storage and thus decrease maintenance time. You can find many posts regarding Entity Framework in this blog.
1) Create an empty ASP.Net Application (Web Forms Application) and give it the name EFoptimisation. I am using Visual Studio 2013 Ultimate edition.
2) Add a new web forms page in the application. Leave the default name. The application I am going to build is very simple web forms application. The user will enter a last name and will get back the first name(s) for that last name.
3) I will use the AdventureWorks2014 database (You can download it here) for this application and more specifically the Person.Person table. I have installed SQL Server 2014 Enterprise edition in my machine.
4) I will add an ADO.Net Entity data model using Database First paradigm. Follow the wizzard steps, create the connection string and then import into the conceptual model only the Person.Person table which will become an entity in the domain model. If you want to look at those detailed steps if you are new to EF and Database First have a look at this post.
5) Add a textbox and a button to the page. The user will
enter the last name in the textbox and will hit enter and
then the results will be printed on the page.
This
is the code inside the Page_Load event
handling routine.
protected void Page_Load(object sender, EventArgs
e) {
using( var ctx = new AdventureWorks2014Entities())
{
string LastName = TextBox1.Text;
var query = from person in ctx.People select person;
foreach (var p in query)
{
if (p.LastName==LastName)
{
Response.Write(p.FirstName);
Response.Write("<br/>");
}
} }
}
The code above is pretty straight forward.
6) Now we are ready to run the application. Before we do that I will launch SSMS and connect to my local instance of SQL Server. Then I will also launch the SQL Profiler and create a new trace. The trace will listen only for the SQL:BatchStarting event. I activate te trace so the trace is running.
7) I build and run my web app. The results I get back when typing "Yuan" as last name is 92 first names.
8) Let me see what the trace recorded in my SQL Profiler and
the T-SQL that was generated.
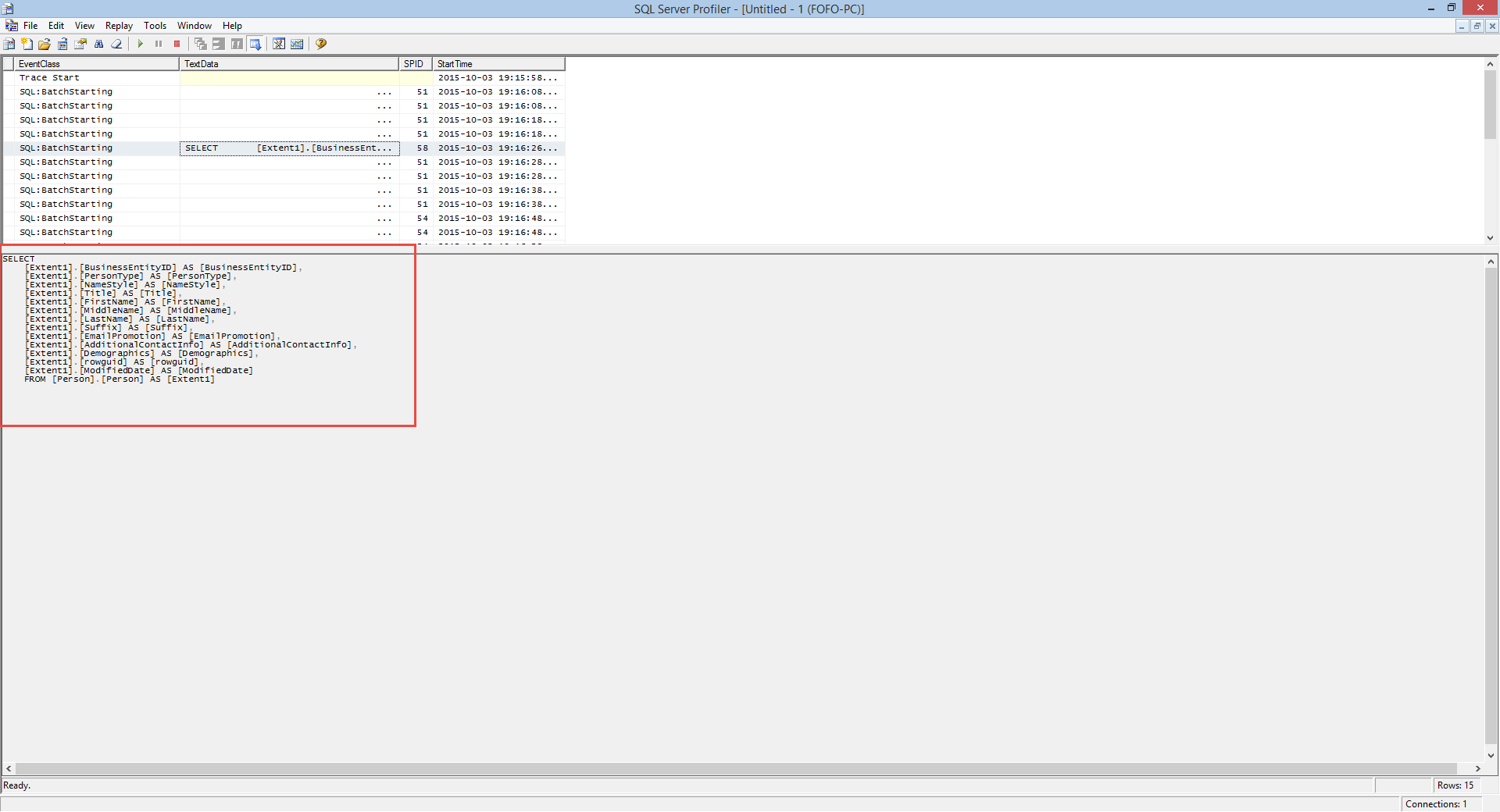
9) If I copy and paste the T-SQL in my SSSM and
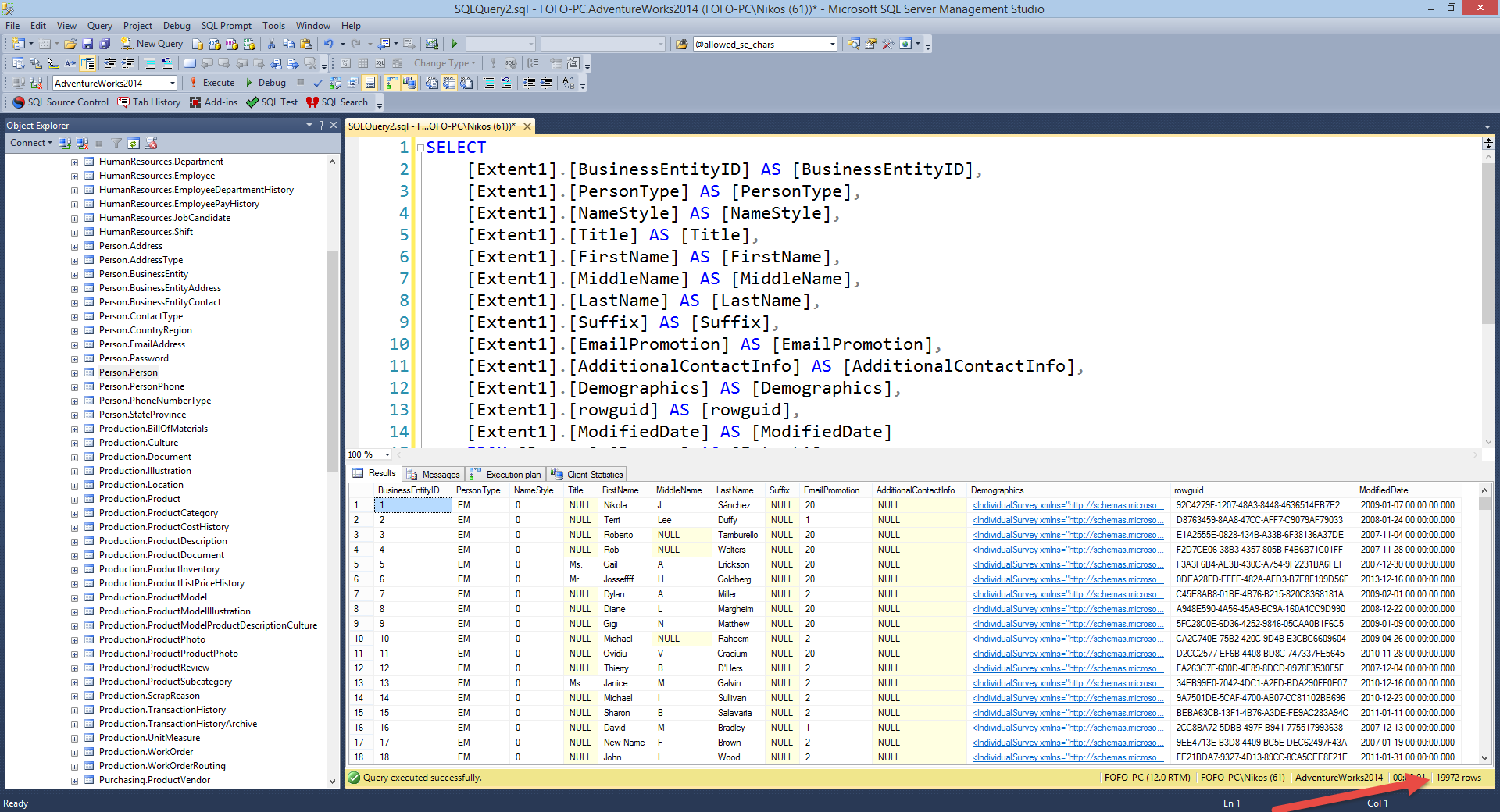
execute the query (Enable Actual Execution Plan and Client
Statistics) I will get the following results - 19972 rows in total.
Ηave a look at the piscture below
Now let's have a look at the execution plan created. Have a look at the picture below.
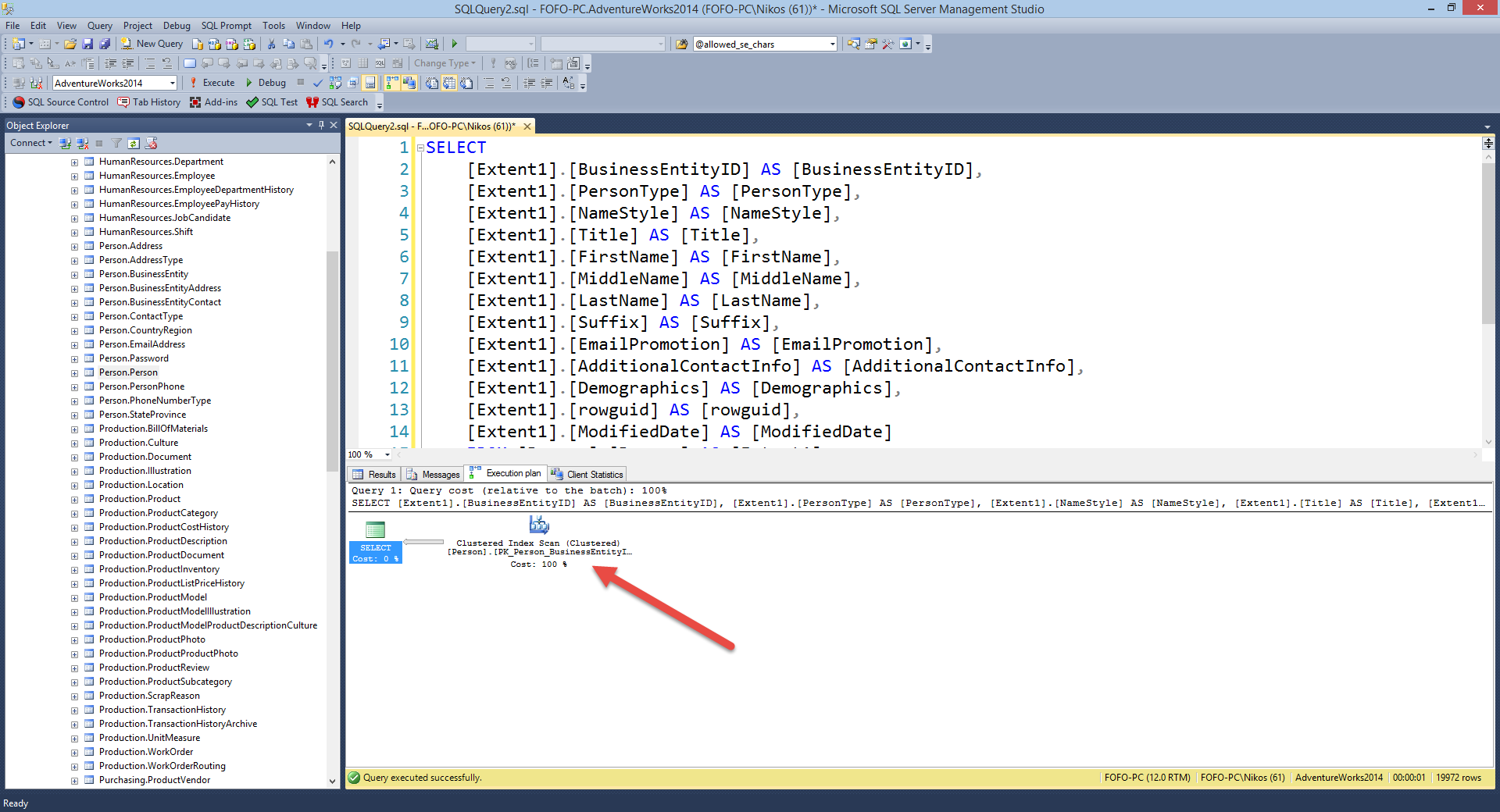
We have a Clustered Index Scan.The Clustered Index Scan means that SQL Server started at the very top of the table and scanned every row until it reached the bottom of the table. Not a very good scenario to have in terms of performance. Now lets have at the Client Statistics tab. Have a look at the picture below.
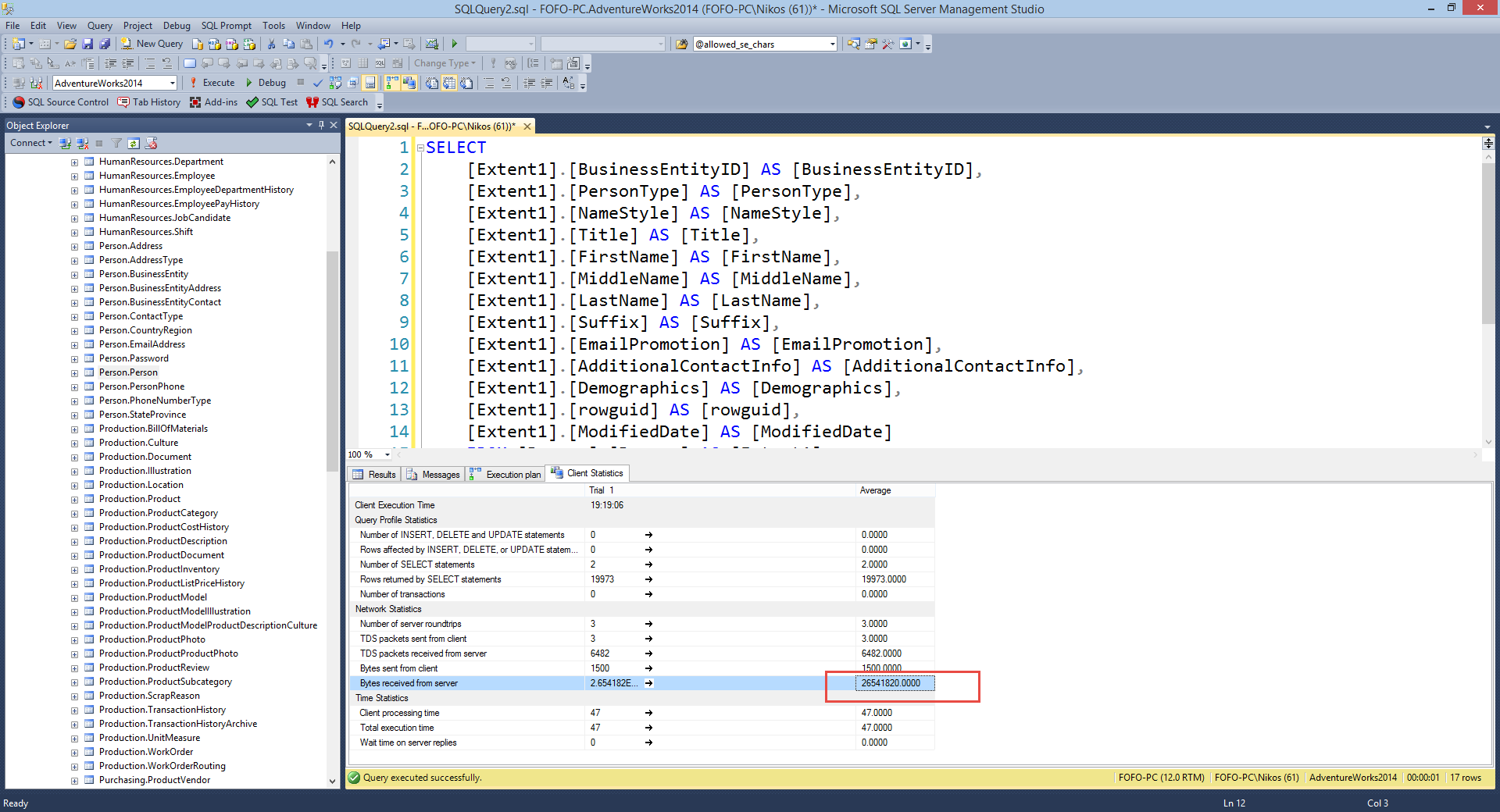
As you can see the bytes transfered from
SQL Server is almost 26 mbytes.That is a huge amount of data
to be transfered through the network back to the client to
satisfy a single query.
10) We need to refactor
our code in order to create more efficient T-SQL code.
protected void Page_Load(object sender, EventArgs
e) {
using( var ctx = new AdventureWorks2014Entities())
{
string LastName = TextBox1.Text;
var query = from person in ctx.People
where person.LastName.Equals(LastName) select person;
foreach (var p in query)
{
Response.Write(p.FirstName);
Response.Write("<br/>");
} }
}
As you can see from the code above I am doing now the filtering on the server.
Have a look below to see what the Profiler's trace output was.
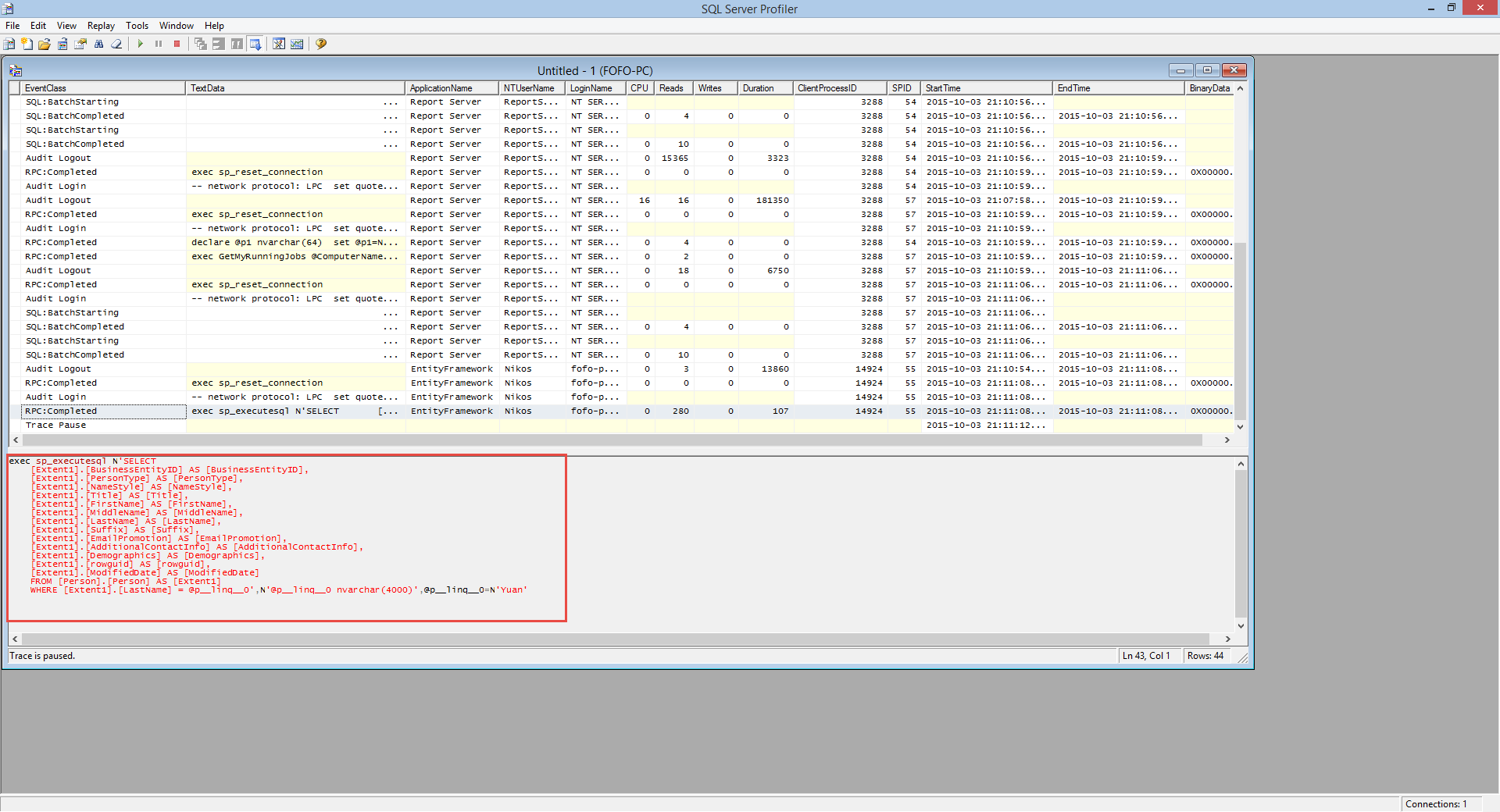
The T-SQL now has a Where clause.It is a parametirised query.If I place this query in my SSMS and execute it I will get back 92 rows only and my execution plain will look like this
This is a by far more optimal executon plan(Index Seek & Lookup) that the Clustered Index Seek.
If I look at the Client Statistics tab (Bytes received from the server), I have only 145Kbytes of data compared with the 26Mbytes I had previously.
11) Now we can use projection to retrieve only the columns that we are interested in (FirstName) and get rid of the other ones.
I go back to the Page_Load routine and
instead of
var query = from person in ctx.Peoplewhere person.LastName.Equals(LastName)select person;
I rewrite my code to utilize projection
var query = from person in ctx.People
where person.LastName.Equals(LastName) select new { person.FirstName };
Then I build and run the application with the Profiler
running
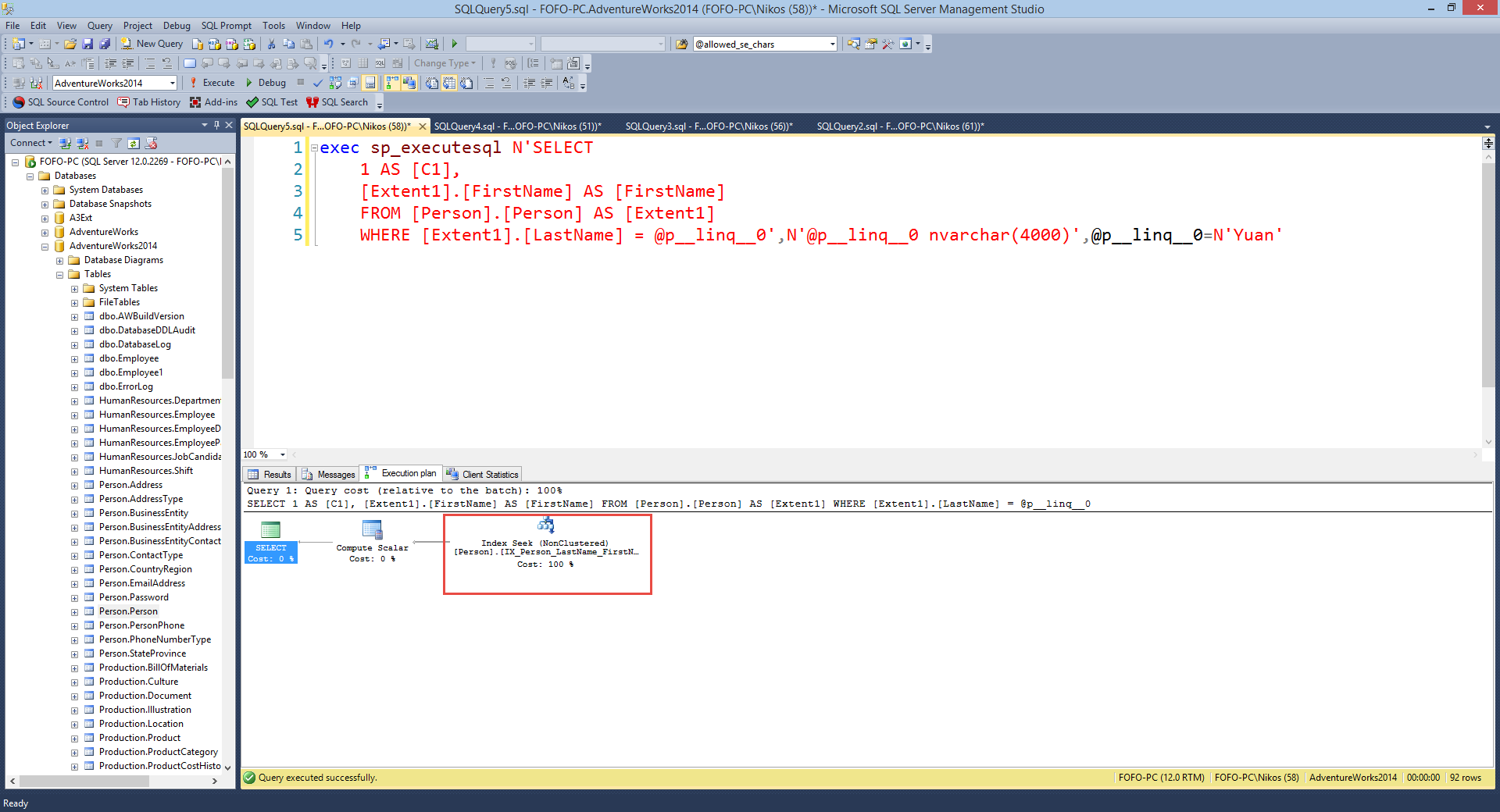
This is the T-SQL from the Profiler when
I type "Yuan" in the textbox.exec sp_executesql N'SELECT 1 AS [C1],
[Extent1].[FirstName] AS [FirstName]
FROM [Person].[Person] AS [Extent1]
WHERE [Extent1].[LastName] = @p__linq__0',N'@p__linq__0
nvarchar(4000)',@p__linq__0=N'Yuan'
As you can see from the T-SQL above I get only
the FirstName column. If I place the T-SQL code in an SSMS
query window (Enable Client Statistics & Actual
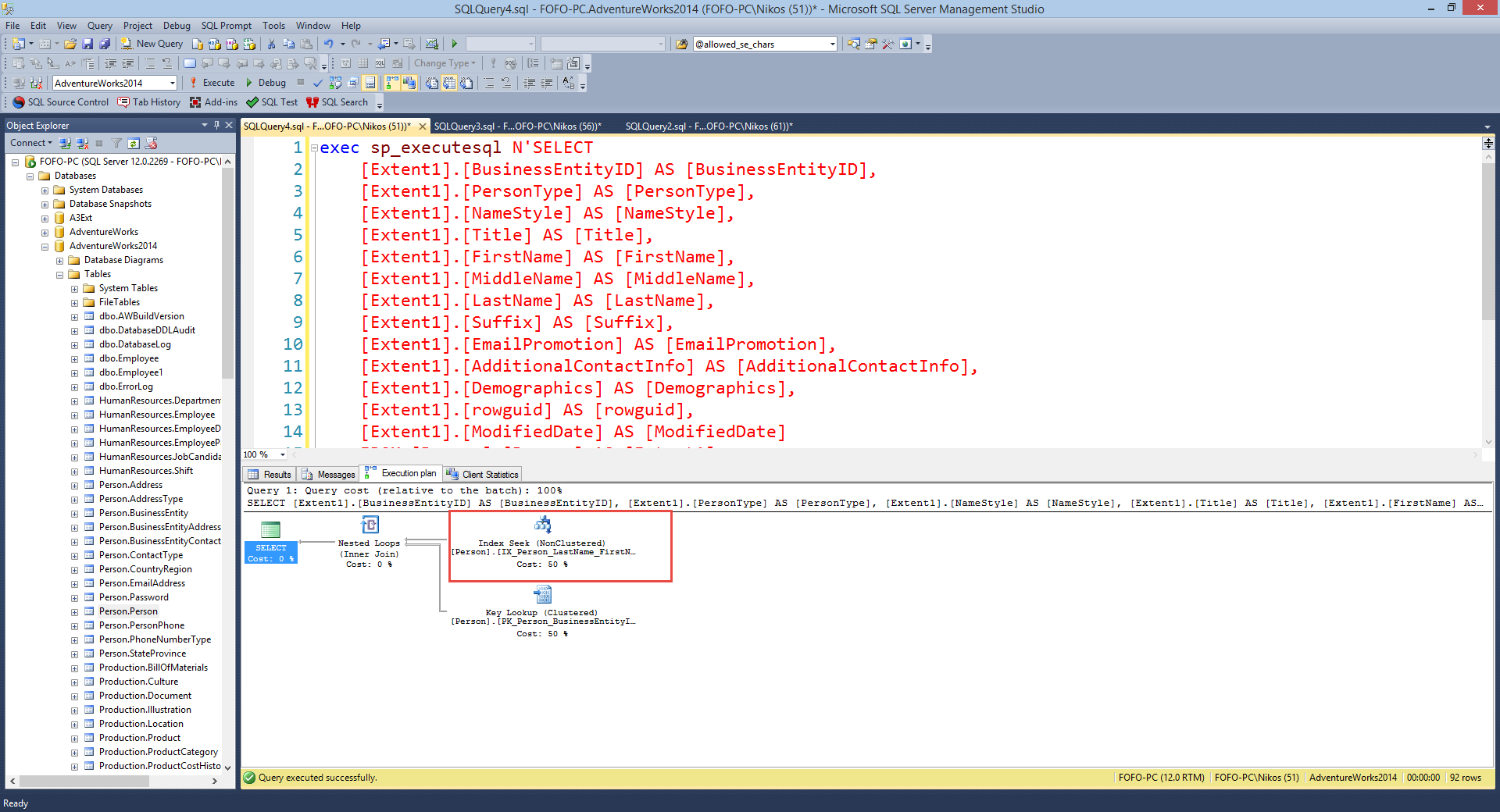
Execution plan) I get back 92 rows of data and the following
picture shows the actual exection plan. Now we see a
Non Clustered Index Seek. We are seeking
and not scanning which is a great thing.
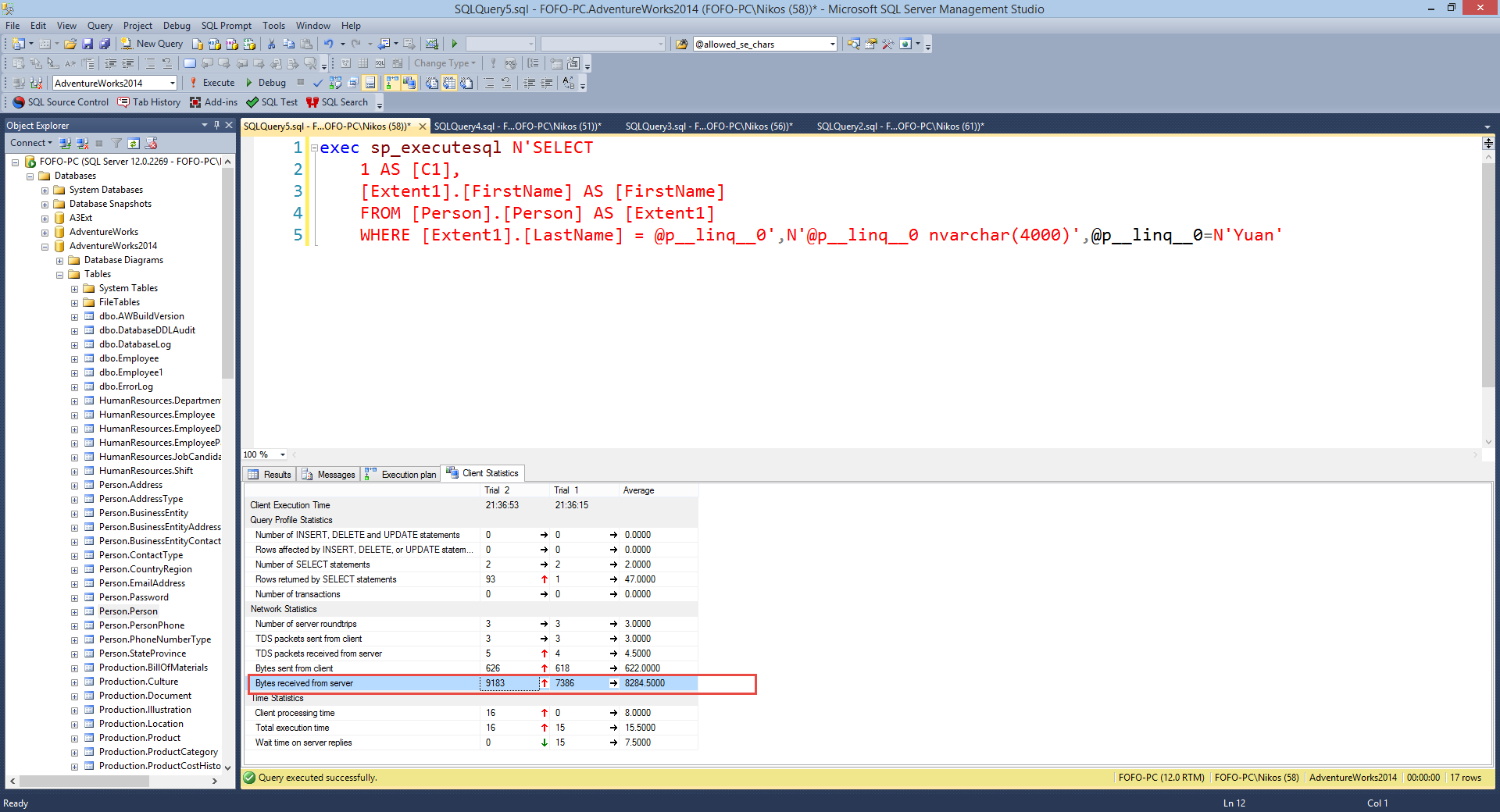
Let's have a look at the client statistics.As you can see
from the picture below the bytes received from the server is
just 9183 bytes , 9 Kbytes. This is huge reduction compared
to the 145 Kbytes and 26 Mbytes.
To recap, make sure that you do all the
filtering on SQL Server and use projection when you do not
want all the table columns in your application, when writing
apps that use EF as the data access layer.It is always wrong
to filter on the client when SQL Server has all the power to
do that for us.
Hope it helps!!!