Faceted search with Solr on Windows
With over 10 million hits a day, funda.nl is probably the largest ASP.NET website which uses Solr on a Windows platform.
While all our data (i.e. real estate properties) is stored in SQL Server, we're using Solr 1.4.1 to return the faceted search results as fast as we can. And yes, Solr is very fast. We did do some heavy stress testing on our Solr server, which allowed us to do over 1,000 req/sec on a single 64-bits Solr instance; and that's including converting search-url's to Solr http-queries and deserializing Solr's result-XML back to .NET objects!
Let me tell you about faceted search and how to integrate
Solr in a .NET/Windows environment. I'll bet it's easier
than you think :-)
What is faceted search?
Faceted search is the clustering of search results into categories, allowing users to drill into search results. By showing the number of hits for each facet category, users can easily see how many results match that category.
If you're still a bit confused, this example from CNET explains it all:
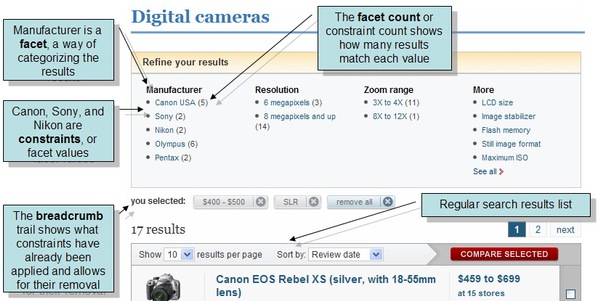
The SQL solution for faceted search
Our ("pre-Solr") solution for faceted search was done by adding a lot of redundant columns to our SQL tables and doing a COUNT(...) for each of those columns:

So if a user was searching for real estate properties in the city 'Amsterdam', our facet-query would be something like:
SELECT COUNT(hasGarden), COUNT(yearBuilt1930_1940),
COUNT(yearBuilt1941_1950), COUNT(etc...)
FROM Houses
WHERE city = 'Amsterdam'
While this solution worked fine for a couple of years, it
wasn't very easy for developers to add new facets. And also,
performing COUNT's on all matched rows only performs well if
you have a limited amount of rows in a table (i.e. less than
a million rows).
Enter Solr
"Solr is an open source enterprise search server based on the Lucene Java search library, with XML/HTTP and JSON APIs, hit highlighting, faceted search, caching, replication, and a web administration interface." (quoted from Wikipedia's page on Solr)
Solr isn't a database, it's more like a big index. Every
time you upload data to Solr, it will analyze the data and
create an inverted index from it (like the index-pages of a
book). This way Solr can lookup data very quickly. To
explain the inner workings of Solr is beyond the scope of
this post, but if you want to learn more, please visit the
Solr Wiki pages.
Getting faceted search results from Solr is very easy; first let me show you how to send a http-query to Solr:
http://localhost:8983/solr/select?q=city:Amsterdam
This will return an XML document containing the search results (in this example only three houses in the city of Amsterdam):
<response>
<result name="response" numFound="3" start="0">
<doc>
<long name="id">3203</long>
<str name="city">Amsterdam</str>
<str name="steet">Keizersgracht</str>
<bool name="hasGarden">false</bool>
<int name="yearBuilt">1932</int>
</doc>
<doc>
<long name="id">3205</long>
<str name="city">Amsterdam</str>
<str name="steet">Vondelstraat</str>
<bool name="hasGarden">true</bool>
<int name="yearBuilt">1938</int>
</doc>
<doc>
<long name="id">4293</long>
<str name="city">Amsterdam</str>
<str name="steet">Trompstraat</str>
<bool name="hasGarden">true</bool>
<int name="yearBuilt">1949</int>
</doc>
</result>
</response>
By adding a facet-querypart for the fields "hasGarden" and
"yearBuilt", Solr will return the facets for those
particular fields.
...&facet.field=hasGarden&facet.query=yearBuilt:[1930 TO 1940]&facet.query=yearBuilt:[1941 TO 1950]
The complete XML response from Solr now looks like this (note the "face_counts" node at the end of the result-XML returned by Solr):
<response>
<result
name="response" numFound="3" start="0">
<doc>
<long
name="id">3203</long>
<str
name="city">Amsterdam</str>
<str name="steet">Keizersgracht</str>
<bool name="hasGarden">false</bool>
<int name="yearBuilt">1932</int>
</doc>
<doc>
<long name="id">3205</long>
<str name="city">Amsterdam</str>
<str name="steet">Vondelstraat</str>
<bool name="hasGarden">true</bool>
<int name="yearBuilt">1938</int>
</doc>
<doc>
<long name="id">4293</long>
<str name="city">Amsterdam</str>
<str name="steet">Trompstraat</str>
<bool name="hasGarden">true</bool>
<int name="yearBuilt">1949</int>
</doc>
</result>
<lst name="facet_counts">
<lst name="facet_queries">
<int
name="yearBuilt:[1930 TO 1940]">2</int>
<int name="yearBuilt:[1941 TO
1950]">1</int>
</lst>
<lst name="facet_fields">
<lst name="hasGarden">
<int name="true">2</int>
<int name="false">1</int>
</lst>
</lst>
</lst>
</response>
Trying Solr yourself
To run Solr on your local machine and experiment with it, you should read the Solr tutorial. This tutorial really takes less than one hour, in which you will install Solr, upload sample data and get some query results. And yes, it works on Windows without a problem (you do need Java installed).
Note that in the Solr tutorial, you will use
-
Use the 64-bits version of Tomcat. In our tests, this doubled the req/sec we were able to handle! -
Use a .NET XmlReader to convert Solr's XML output-stream to .NET objects. Don't use XPath; it won't scale well. -
Use filter queries ("fq" parameter) instead of the normal "q" parameter where possible. Filter queries are cached by Solr and will speed up Solr's response time (see FilterQueryGuidance)