Storing Relations Instead of Data - Just a cool idea or a revolutionary new data storage paradigm?
Well, this idea of storing relations instead of data sounded very interesting - even though I did not fully understand it. And I guess, I still do not fully understand it - but Peter Krieg got me hooked. I´m always open for unusual cool new ideas, and this seems to be one. Later that day he did a keynote titled "When Powerpoint meets Doom" where he tried to explain the idea to a larger audience. Reactions where mixed, but I immediately ran out to get his book "Die paranoide Maschine - Computer zwischen Wahn und Sinn". (Sorry, this book is only available in German; but nevertheless I can recommend it for his quite refreshing view on what computers are and how they need to change, if we want them to become more "intelligent".)
To substantiate his claim, that storing relations instead of data makes sense, Peter Krieg later showed me a demo app based on a so called Pile Engine. Pile is the theory behind the idea and has been developed by Erez Elul of Pile Systems over the past years. You can read about the whole theory/philosophy of seeing the (data) world as a universe of relations at pileworks. But beware: Unless you have a certain inclination towards studying philosophical texts or reading about formal logic, well, it won´t be easy for you follow Erez´ thoughts. However, even though I too am still somewhat lost in the Pile world, I have the feeling, those guys are on to somewhat very interesting. I´m looking forward to meeting them next weekend in Berlin - and they can be sure, I´ll have a lot of questions for them.
Ok, so Peter showed me this Pile Engine demo program which did a full text search on a large corpus of text. What can I say? It was impressing. Without using any index of words it was blazingly fast. But what was even more fascinating: You could search for any text string without performance loss. Usual full text search engines index all word in a text (except for stop words). That´s why they are fast when searching for those words. But if you´re looking for non-word strings, there index is of no help. If you´d be searching for "ch en" (as in "search engine"), this string would not have been index, so the search engine would need to scan the raw text itself. Very slow! But for the Pile Engine this does not make a difference. It does not need an index, so it does not care if you´re searching for "engine" or "ch en". (If you´re asking where such kind of query on texts might make sense, look at bio informatics: Those guys work with huge texts representing DNA molecule sequences, and they want to search for arbitrary combinations of letters in those texts.)
Now comes the interesting part: How does the Pile Engine accomplish its feat? Or more generally: What does Pile Systems mean, when they talk about storing relations instead of data? Where does the data go? Let me assure you, you´re not alone asking those questions. And it took me some time to get used to "Pile thinking" - and I´m still an apprentice in it.
Let´s start with simple text to get an idea about those relations.
Representing Text as Relations
When we store text as data, then we store the text´s bytes. That´s so straightforward, we don´t even think about it anymore. We never question what we´re doing. The text "Peter Piper picked a peck of pickled peppers..." gets stored like this:
![]()
Well, what´s wrong with it, you might ask? It´s redundand! In the above excerpt from the famous tounge twister there 4 "P", 4 "E", 2 "R" etc. Each occurence of a letter leads to storing the letter. That´s what "storing data" means. Take that to the level of words: Each occurence of "Peter" or any other word in the text needs to be stored. So the longer the text, the larger the amount of data you store.
Now, the Pile guys say: Why store the data, when you can regenerate it any time from relations? To store a text, they´d "relationize" it and end up with a data structure roughly similar the following:
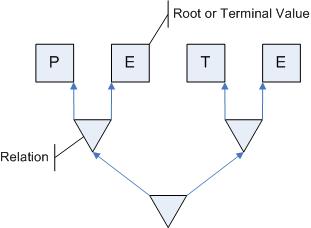
The letters are not stored one after another anymore, but instead are tied together by relations. A relation being a tripel consisting of two pointers to child nodes and a qualifier.
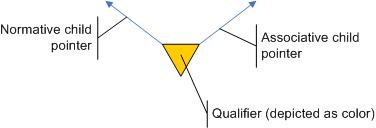
Each relation is uniquely defined by its childs (as far as I understand Pile). There can be no two relations pointing to the same children, i.e. all relations are distinct. (This is like with rows in Codd´s relational model.) (Don´t ask me, why Pile calls the left pointer "normative" and the right one "associative" :-) Also, please don´t mind, that Pile is calling nodes higher up children. You´ll get used to this upside down view of trees.)
When you traverse such a tree from the bottom to the top in depth-first manner, you get "PETE" as the resulting text. So you effectively generate the original text from the relations, because the text itself as a sequence of letters is nowhere present in the system anymore.
But this is only a first rough picture to make the whole concept more palatable to you. Because when you look closer, the above representation still contains redundancy. What the Pile Engine really does is the following:
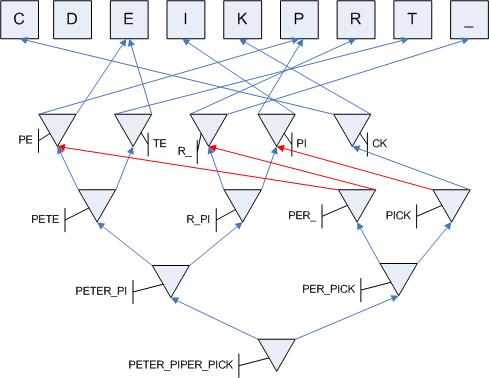
Somewhat confusing on first sight, isn´t it? But if you look at it for a while, it becomes very clear: Each letter is only stored once as a terminal value. Then the text is broken into two letter pairs and each pair encoded as relation with the first letter being pointed to by the normative child and the last letter pointed to by the associative child.
On the next level, two of those relations are combined by a new relation, now representing 2 two letter relations, that means 4 letters - and so on.
The read pointers show, where reuse comes into play: In order to encode (or "relationalize") "PER_", to relations need to be combined. However, those relations ("PE" and "R_") already exist from encoding "PETER_" at the beginning of the text. So we save time and space by not encoding them again.
If you think this further, you´ll realize, the longer a text is and the more combinations of letters of any length occur repeatedly, the more relations are reuse and less new relations have to be build. That means, the size of a Pile database does not increase linearly but asymptotically!
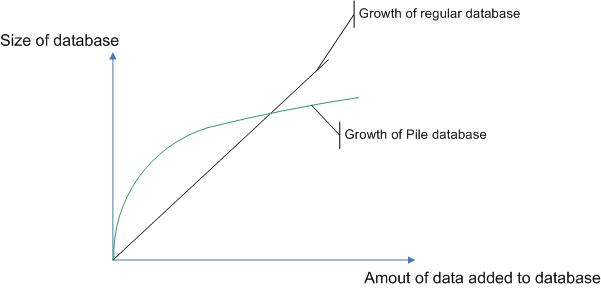
As long as the amount of data is small, Pile sure adds considerable overhead. A tree like the above sure at first requires more bytes in total than the simple text it represents. But as the amount of data increases and patterns start to occur repeatedly, Pile can reuse more and more relations already present.
Warming up: some terminology first
Saving some bytes on hard disks might not give you a real kick. Being able to search through texts very quickly might not be what you´re looking for. But what about very flexible database schemas? Or how would you like to never have to think about normalizing data again?
The real coolness of Pile lies in its fundamental data representation which automatically relates entities, if they share some "characteristics", I´d say.
In order to show you that, let me coin some terms:
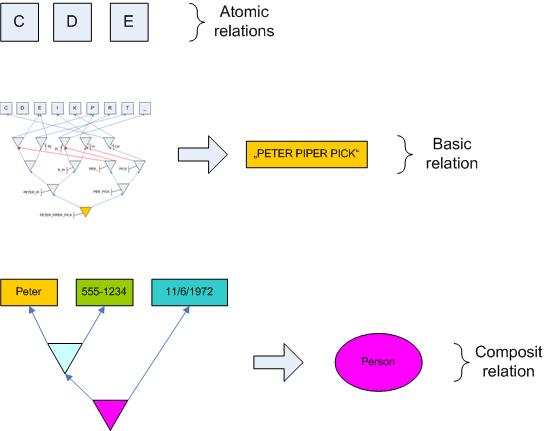
The letters we saw earlier I´d like to call atomic relations because they are the roots, the terminal values of any Pile tree. In the end, all other relations directly or indirectly relate atomic relations to each other. (The reason why I still call these terminal values "relations" is, that you can further relationalize them into relations of bits. Each terminal value in the end is just a relation of relation of the "nucleons" 1 and 0.)
Since most of us are not concerned with just storing texts but with storing mundane data entities like addresses or invoices, I think it´s necessary to introduce (at least) two levels of abstraction over atomic relations:
Basic relations I call a hierarchy of relations rooted in atomic relations and forming a larger whole. This whole or unit of textual data can be a name or a birth date or a two page memo text. Basic relations so to speak are a bag of very simple relations with a label stuck to it. I use the qualifier of the relation triple as such a label. In Pile notation a triple looks like this: (n [Q] a). n beging the normative child, a being the associative child and [Q] being the qualifier. In my pictures I try to use colors for [Q], but sometimes I might assign it an identifier like [name] or [person]. ([Q] of atomic relations and the inner relations making up a basic relation I leave undefined; they are not important for the further discussion. But if you like, you can call the [atom] and [basic].)
When pointing to a basic relation the pointer references the bottom most relation in the upside down tree constituting the basic relation. You can always zoom into a basic relation and see its details.
On the next level above basic relations are Composit relations. Composit relations combine several basic relations (or other composit relations) to form an even larger whole. They too have an explicit color, i.e. qualifier.
If you want to map this to the world of classes you can say: basic relations are like text fields and composit relations are like classes containing fields. For a start you could liken the above picture to a class definition like this:
class Person
{
string name;
string phone;
string birthdate;
}
Then the actual Pile of the depicted composit relation would contain one object:
Person p = new Person();
p.name = "Peter";
p.phone = "555-1234";
p.birthdate = #11/6/1972#;
Networks of data instead of tables
Ok, ok, enough with theory. Here comes the fun part: Imagine how a Pile database of persons and appointments look like. Here are the composit relations with their basic relations:
Person(name, phone, birthdate)
Appointment(name, date)
Think about it for a while...
You see the difference between the world of objects and tables? Remember: Pile doesn´t store data redundandly. If you have two Persons and an Appointment like this
Person("Peter", "555-1234", "11/6/1972")
Person("Paul", "732-3396", "11/6/1972")
Appointment("Peter", "12/8/2005")
the database would look like this:
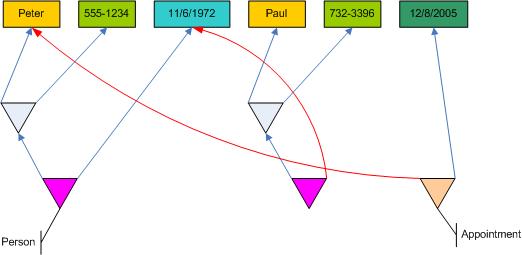
The name "Peter" and the birthdate "11/6/1972" would only get stored once. However, I don´t think this space saving aspect is important, but rather that a Person entity and an Appointment entity share the same data as well as two Person entities share the same data.
Because: sharing data means being linked, being in relation to each other.
Pile thus very, very naturally and implicitly links data. You don´t need to set up a specific relation between entities like Person and Appointment using an explicit object reference or a foreign key. The are automatically associtated with each other by their data.
Ok, to fully see that, you need one more piece of information: relations in Pile are bi-directional. So if some relation R´s normative child is relation C, then not only R "sees" C, but also C "sees" R. C ist R´s child and R is C´s parent. When traversing a Pile tree you can move up the hierarchy from parent to children and there are always only two children to each relation. But you can also traverse the Pilte tree down from the children to the parents. However, each child can have an arbitrary number of parents! The basic relation for "Peter" has two parents: a composit Person relation (indirectly via the internal unquallified relation) and a composit Appointment relation.
So, what a Pile Engine does is weaving a network of data instead of putting data in little bins which have to be manually connected. Pile frees you of the need to think about setting up relations in advance like with relational databases. Maybe instead you could say, relations in Pile databases just happen :-) Whereever Composit relations share the same basic relations (or Composit relations) they are automatically connected. That (!) I find very fascinating.
Information modelling the Pile way
This cool automatic association of data has some implications on how you would model data for a Pile database. Instead of starting top-down with classes or tables or Composit relations, you should start with basic relations. Once you know all the entities you want to store in a Pile database (e.g. addresses, invoices, appointments, products, categories...) you identify the basic relations. View them as value types and blobs of text. (I´m not sure yet, if a Pile database should handle allow for other terminal values than mere characters.)
For the above example we would arrive at these basic relations: name, phone, birthdate, date.
If a name in a Person is the same kind of beast as a name in an Appointment, we just need one basic relation for it. Both, Person and Appointment, store some kind of date information. Should we thus use the same basic relation or distinguish between them? I´d say, a birthdate is sufficiently different from an appointment date to justify two basic relations. But an invoice date and the date on a photograph might be viewed as of the same kind.
Having identified the basic relations we already know, that all composit relations sharing them will automagically be connected! I´ve to say it again: very, very cool!
Next you´d look for composit relations made up of basic relations, e.g. Person and Appointment. Then you could move up the abstraction ladder and look for composit relations combining other composit relations, e.g. Invoice(Person, Shippinginformation, Item).
Keep in mind, Pile´s relations are alwas bi-directional and 1:n! No need to specify cardinality. (I haven´t thought much about constraints on relations yet, sorry.)
And that´s it! You´re finshed with your Pile "schema". Lean back and think about the beauty of it: If you come up with some new composit relation or want to rearrange existing ones, no data has to be moved arround or copied. You want to add a music library to your ERP Pile database? No problem! Just think about which basic/composit relations you can reuse. You sure can reuse the basic name relation for the artist´s name. And you could reuse the basic date relation for the release date of an album. Or you could define an Artist to be Artist(Person, genre).
As soon as you start putting music information in your Pile database it gets automatically associtated with your ERP data. Maybe you find out, your famous artist has already ordered from you, becaus his name connects him to an invoice :-)
Upps, this leads me to the topic of identity.
Handling identity
Each relation is identified by its children. All relations are distinct. Well, that´s cool for automatically weaving a network of data - but sure can lead to some misunderstandings when not explicitly taken into account.
There are certainly many persons with the name of Peter. How would you know from looking at the above simple Pile database with Persons and Appointments, if an Appointment belongs to this Peter or that Peter? There is no way to tell.
So as with relational databases you need to assign explicit identities to units of data that actually describe some individual entity like a person. I suggest to introduce a basic ID relation for that purpose.
Basic relations: ID, name, phone, birthdate, date
Composit relations: Person(ID, name, phone, birthdate), Appointment(ID, Person, date)
The new Pile schema defines Persons and Appointments to have an identity and Appointments to be associtated with Persons instead of names.
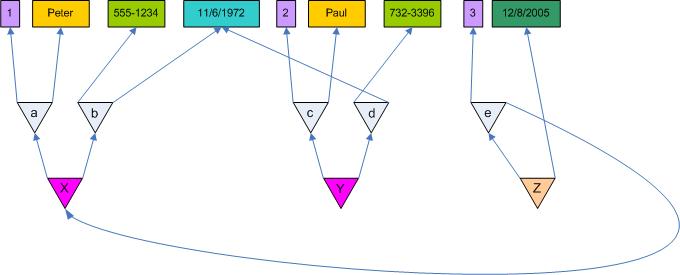
Do you "feel" this to be still different and much simpler than modelling a regular relational database schema? Good! :-) Including a Person in the definition of Appointment is so much more natural than setting up a PK-FK-relation.
Please also note: Even though now Appointment is related to Person instead of name, it is still possible to start with just a name and find all Appointments for it (i.e. Appointments referring to Persons containing this name). Only some levels of indirection have been introduced, but no fundamental switch like from "column in table" to "column in different table and PK-FK-relation" was necessary. Pile just knows relations whereas the traditional relational model know rows/tables and keys.
Querying a Pile database
Sticking data into a Pile database is one thing. But how to get it out again? How to query for a Person or all Appointments of a Person on a certain day?
As far as I understand, querying a Pile database basically is pattern matching. You hand a relation to the Pile engine, e.g. name("Peter") and, for example, it returns the list of parents of that relation, e.g. a("1", "Peter") (see above picture). The query birthdate("11/6/1972") would return b("555-1234", "11/6/1972") and d("732-3396","11/6/1972"). Asking for c("2", "Paul") would return Y(c,d).
Please remember: relations are defined by their children. So in reality a simple query would just consist of the child relations, e.g. instead of a("1", "Peter") you´d say ("1", "Peter") becaue "1" and "Peter" taken together are equal to a. That means, a Pile engine should return a full relation including all parents when queried with the "contents" of a relation. Sending query ("1", "Peter") thus would result in a, sending ("2", "Paul") would return c.
(Here we stumble across something that´s still a mystery to me: How should a function look like that maps relations (or addresses) n and a to a new relation r(n,a)? How can r = f(n,a) look like? I find this a difficult question. The sample Pile engine seems to have solved this problem, but I don´t yet understand the solution. As soon as I do, though, I´ll let you know ;-)
With a relation (or a list of relations) in hand as the result of a query, you then can traverse them up and down to your liking, e.g. with relation a in hand, you move up to its parent X and then up to its parent e and from there to Z. Small easy steps to get from a name with an identity to an Appointment.
To form more complex queries, trees of relations need to be assembled, e.g. (("1",*)(*,*)). This query would return X, because it has a normative child whose normative child is "1" (The * I use as wildcard for a relation.) Query ((*,*)(*,"11/6/1972")) would X and Y.
Of course even more complex queries can be expressed using trees. What I don´t know yet is, how to best express logical operations like OR/NOT (because a single tree essentially is a query where the operands are ANDed). But there sure is a way... ;-)
Conclusion
That´s how far I understand Pile. The existing Pile demo engine does not implement all this, as far as I know. It just works on plain text. But once I have the f(n,a) function, I´m pretty sure, I can set up a little Pile engine for non-text entities pretty quickly. That will be a fun programming experience... :-)
But of course, there´s still much to be learned. I´ve to dig into the Pile literature at www.pileworks.org and talk to the guys making up all the theory behind it. Interestingly I just received an email from one of them which made some things already more clear. For example I learned to see not only trees growing from the bottom up - but the many trees hanging down from the roots. The root "11/6/1972" for example is the root of two trees.
Also I want to think more about how far Pile is related to Prolog and Object Role Modelling and Lisp. When sketching Pile trees/networks or writing them down, sometimes feel reminded of these concepts/technologies. But I have an inkling Pile goes much further...
Whether Pile is a revolution or just a nice idea or a solution to just some particular data storage/retrieval problems, I don´t know yet. But I think it´s cool :-)