Recoverability with Azure Functions
When working with Azure Service Bus triggers and Functions, the recoverability story is not the best with the out-of-box implementation. To understand the challenges with the built-in recoverability and how to overcome those, this post will dive into the built-in recoverability with Azure Functions for Service Bus queues and subscriptions, offering an alternative. But first, what is recoverability?
Recoverability in messaging refers to a messaging system's ability to ensure that messages are reliably delivered even in the presence of failures or disruptions. It involves message persistence, acknowledgments, message queues, redundancy, failover mechanisms, and retry strategies to guarantee message delivery and prevent data loss. This is vital for applications where message loss can have serious consequences.
With Azure Service Bus, recoverability is provided with
MaxDeliveryCount and a dead-letter queue. To be
more specific, a message is delivered at least
MaxDeliveryCount time and, upon further
failure, when re-delivered, will be moved to a special
dead-letter sub-queue. Azure Functions leverage that feature
to retry messages. However, there are a few issues with this
approach.
- Retries are immediate
- Upon final failure, the dead-lettered message has no information to assist in troubleshooting.
Let's dive into those issues to see what can be done.
As part of processing a message, we must contact a 3rd part
API. But, for some reason, despite the promised up-time of
99.9%, we hit an error. As a result of that error, the
message processing will throw an exception, and the message
will be re-delivered. It will be attempted as many times as
the value of MaxDeliveryCount defined on the
entity used to trigger the function. If it's set to 10, that
would be 10 retries one after another. Or 10
immediate retries. That's not a small number of
attempts. But if the problem persists, the message will be
dead-lettered to allow the Function processing of other
messages. Which is good. But when we need to understand what
happened with the message at the time of the failure, we'll
have a hard time. When a message is dead-lettered, the
reason for dead-lettering will only contain the benign
reason: the maximum delivery count has been exceeded. Not
very helpful. Gladly, there are Application Insights and
logged errors that could be correlated to the errors that
have occurred and hopefully link between the dead-lettered
message(s) and the logged exception(s). But wouldn't it be
simpler to look at the message and know exactly the
reason why it failed?
Thanks to the Isolated Worker SDK, we can do that. Similar to frameworks such as NServiceBus and MassTransit, we can enable recoverability with Azure Functions and make our prod-ops life easier. So, let's build that recoverability!
Centralized error queue
Unlike
centralized dead-letter queue, a centralized error queue is an arbitrary queue that
we'll add to the topology to store any messages that would
typically go to the dead-letter sub-queue per entity. I.e.
we won't allow MaxDeliveryCount executions for
the message to be dead-lettered. Instead, we'll ensure we
attempt a message no more than N times,
moving it to the error queue afterwards.
For the sake of the exercise, I'll use a queue called
error.
Middleware
To implement recoverability, a Funcitons Isolated Worker SDK is required as it supports the concept of middleware (think pipeline). Below is a high-level implementation to elaborate on the approach. You'll need some package references, but the idea is what's important. We're getting closer!
public class Program
{
public static void Main()
{
var host = new HostBuilder()
.ConfigureFunctionsWorkerDefaults(builder =>
{
builder.UseWhen<ServiceBusMiddleware>(Is.ServiceBusTrigger); // Up-vote https://github.com/Azure/azure-functions-dotnet-worker/issues/1999 😉
})
.ConfigureServices((builder, services) =>
{
var serviceBusConnectionString = Environment.GetEnvironmentVariable("AzureServiceBus");
if (string.IsNullOrEmpty(serviceBusConnectionString))
{
throw new InvalidOperationException("Specify a valid AzureServiceBus connection string in the Azure Functions Settings or your local.settings.json file.");
}
// This can also be done with the AddAzureClients() API
services.AddSingleton(new ServiceBusClient(serviceBusConnectionString));
})
.Build();
host.Run();
}
The main focus is the
ServiceBusMiddleware class, where the
recoverability logic will be found. In a few words, we'll
try to execute the functions,
await next(context) call. If it throws,
function invocation has failed and will be retried. Except
we'll intercept that, and based on how many retries we
allow, we'll decide wherever to rethrow or move the message
to the centralized error queue. Note that we don't actually
move the message. Instead, we clone it, complete the
original message by swallowing the exception and sending the
clone to the error queue. On top of that, we'll add the
exception details to the cloned message to allow easier
troubleshooting by inspecting the message headers. This will
help the prod-ops to understand better why a message has
failed by looking at the exception stack trace and exception
details. Message payload, along with the error, can also be
very helpful in solving the issue.
internal class ServiceBusMiddleware : IFunctionsWorkerMiddleware
{
private readonly ILogger<ServiceBusMessage> logger;
private readonly ServiceBusClient serviceBusClient;
public ServiceBusMiddleware(ServiceBusClient serviceBusClient, ILogger<ServiceBusMessage> logger)
{
this.serviceBusClient = serviceBusClient;
this.logger = logger;
}
public async Task Invoke(FunctionContext context, FunctionExecutionDelegate next)
{
try
{
await next(context);
}
catch (AggregateException exception)
{
BindingMetadata meta = context.FunctionDefinition.InputBindings.FirstOrDefault(b => b.Value.Type == "serviceBusTrigger").Value;
var input = await context.BindInputAsync<ServiceBusReceivedMessage>(meta);
var message = input.Value ?? throw new Exception($"Failed to send message to error queue, message was null. Original exception: {exception.Message}", exception);
if (message.DeliveryCount <= 5)
{
logger.LogDebug("Failed processing message {MessageId} after {Attempt} time, will retry", message.MessageId, message.DeliveryCount);
throw;
}
// TODO: remove when fixed https://github.com/Azure/azure-functions-dotnet-worker/issues/993
var specificException = GetSpecificException(exception);
var failedMessage = message.CloneForError(context.FunctionDefinition.Name, specificException);
var sender = serviceBusClient.CreateSenderFor(Endpoint.Error);
await sender.SendMessageAsync(failedMessage);
logger.LogError("Message ID {MessageId} failed processing and was moved to the error queue", message.MessageId);
}
}
static Exception GetSpecificException(AggregateException exception) => exception.Flatten().InnerExceptions.FirstOrDefault()?.InnerException ?? exception;
}
What about Functions? That's the great part. Every Function triggered by Azure Service Bus messages will be covered. No more need to catch exceptions and handle those.
Result
What does it look like in action? Sending a message that will continuously fail all 5 retries will cause the message to be "moved" into the error queue.
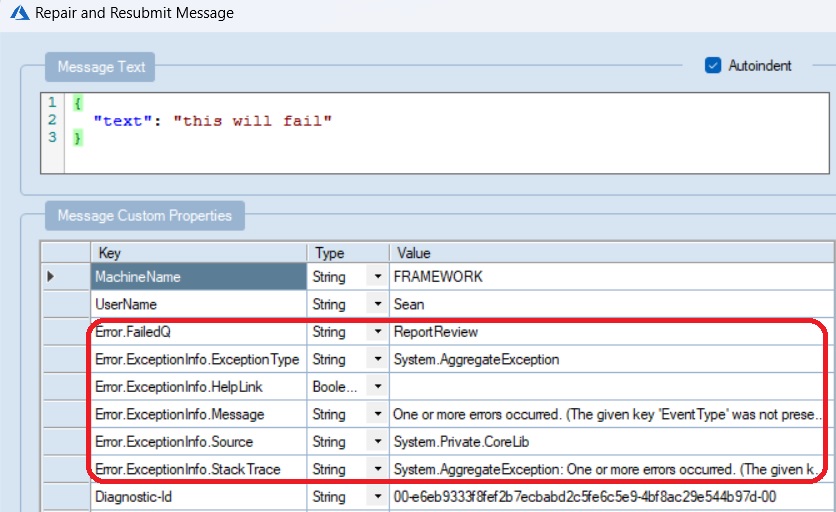
I've decided to provide the failed function name as
Error.FailedQ to identify what queue/Function
has failed. Stack trace and error message to have the
details. Straightforward and very helpful when handling
failed messages.
Back-off retries (delayed retries)
In the next post, we'll cover delayed retries to make recoverability even more robust.