| This is the third post in a series that explains entity association mappings with EF Code First. This series includes:
|
In the previous blog post I demonstrated how to map a special kind of one-to-one association—a composition with complex types. We argued that the relationship between User and Address is best represented with a complex type mapping and we saw that this is usually the simplest way to represent one-to-one relationships but comes with some limitations.
In today’s blog post I’m going to discuss how we can address those limitations by changing our mapping strategy. This is particularly useful for scenarios that we want a dedicated table for Address, so that we can map both User and Address as entities. One benefit of this model is the possibility for shared references— another entity class (let’s say Shipment) can also have a reference to a particular Address instance. If a User has a reference to this instance, as her BillingAddress, the Address instance has to support shared references and needs its own identity. In this case, User and Address classes have a true one-to-one association.
Introducing the Revised ModelIn this revised version, each User could have one BillingAddress (Billing Association). Also a Shipment always needs a destination address for delivery (Delivery Association). The following shows the class diagram for this domain model (note the multiplicities on association lines): |
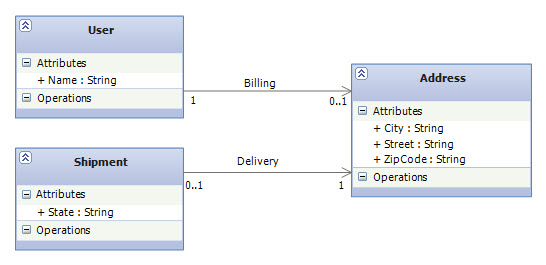 |
In this model we assumed that the billing address of the user is the same as her delivery address. Now let’s create the association mappings for this domain model. There are several choices, the first being a One-to-One Primary Key Association.
Shared Primary Key AssociationsAlso know as One-to-One Primary Key Associations, means two related tables share the same primary key values. The primary key of one table is also a foreign key of the other. Let’s see how we can create a primary key association mapping with Code First.
How to Implement a One-to-One Primary Key Association with Code FirstFirst, we start with the POCO classes. As you can see, we've defined BillingAddress as a navigation property on User class and another one on Shipment class named DeliveryAddress. Both associations are unidirectional since we didn't define related navigation properties on Address class as for User and Shipment. |
public class User
{
public int UserId { get; set; }
public string Name { get; set; }
public virtual Address BillingAddress { get; set; }
}
public class Address
{
public int AddressId { get; set; }
public string Street { get; set; }
public string City { get; set; }
public string ZipCode { get; set; }
}
public class Shipment
{
public int ShipmentId { get; set; }
public string State { get; set; }
public virtual Address DeliveryAddress { get; set; }
}
public class Context : DbContext
{
public DbSet<User> Users { get; set; }
public DbSet<Address> Addresses { get; set; }
public DbSet<Shipment> Shipments { get; set; }
} |
How Code First Sees the Associations in our Object Model: One-to-ManyCode First reads the model and tries to figure out the multiplicity of the associations. Since the associations are unidirectional, Code First takes this as if one Address has many Users and Many Shipments and will create a one-to-many association for each of them. In other words, a unidirectional association is always inferred as One-to-Many by Code First. So, what we were hoping for —a one-to-one association, is not inline with the Code First conventions.
How to Change the Multiplicity of the Associations to One-to-One by Using the ConventionsObviously, one way to turn our associations to one-to-one is by making them bidirectional. That is, adding a new navigation property to Address class of type User and another one of type Shipment. By doing that we simply signal Code First that we are looking to have one-to-one associations since for example User has an Address and also Address has a User. Therefore, Code First will change the multiplicity to one-to-one and this will solve the problem.
Should We Make the Associations Bidirectional? As always, the decision is up to us and depends on whether we need to navigate through our objects in that direction in the application code. In this case, we’d probably conclude that the bidirectional association doesn’t make much sense. If we call anAddress.User, we are saying “give me the user who has this address”, not a very reasonable request. So this is not a good option. Instead we'll keep our object model as it is and will explicitly ask Code First to make our associations one-to-one.
How to Change the Multiplicity to One-to-One with Fluent APIThe following code is all that is needed to make the associations to be one-to-one. Note how the multiplicities in the UML class diagram (e.g. 1 on User and 0..1 on address) has been translated to the fluent API code by using HasRequired and HasOptional methods: |
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress)
.WithRequired();
modelBuilder.Entity<Shipment>().HasRequired(u => u.DeliveryAddress)
.WithOptional();
} |
| Also it worth noting that when we are mapping a one-to-one association with fluent API, we don't need to specify the foreign key as we would do when mapping a one-to-many association with HasForeignKey method. Since EF only supports one-to-one associations on primary keys, it will automatically create the relationship in the database on the primary keys. |
Database SchemaThe mapping result for our object model is as follows (note the Identity column on Users table): |
 |
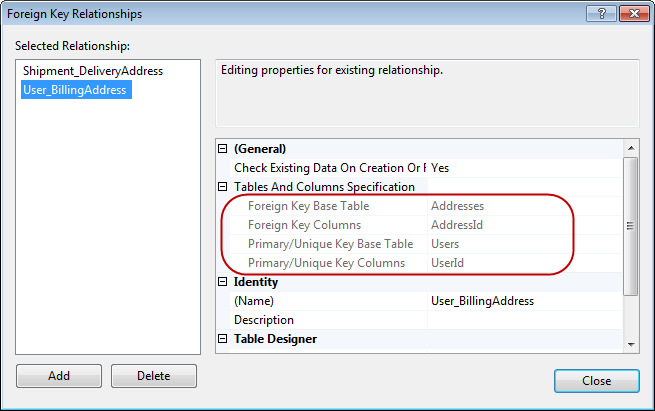
Referential IntegrityIn relational database design the referential integrity rule states that each non-null value of a foreign key must match the value of some primary key. But wait, how does it even applies here? All we have is just three primary keys referencing each other! Who is the primary key and who is the foreign key? The best way to find the answer of this question is to take a look at the properties of the relationships in the database that has been created by Code First: |
 |
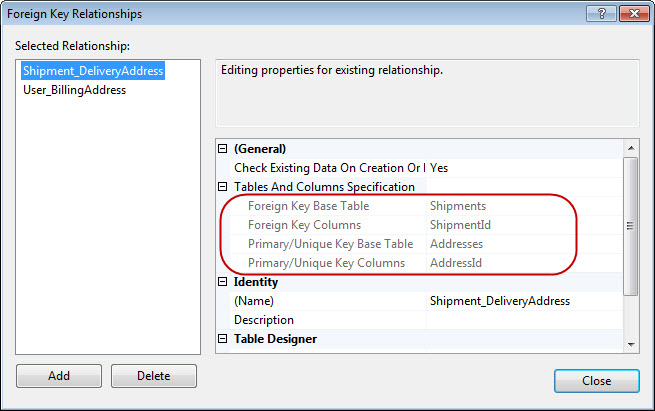 |
As you can see, Code First adds a foreign key constraint which links the primary key of the Addresses table to the primary key of the Users table and adds another foreign key constraint that links the primary key of the Shipments table to the primary key of the Addresses table. The foreign key constraint means that a user has to exist for a particular address but not the other way around. In other words, the database guarantees that an Addresses row’s primary key references a valid Users primary key and a Shipments row’s primary key references a valid Addresses primary key.
How Code First Determines the Principal and Dependent Ends in an Association?Code First has rules to determine the principal and dependent ends of an association. For one-to-many relationships the many end is always the dependent, but it gets a little tricky in one-to-one associations. In one-to-one associations Code First decides based on our object model, and possible data annotations or fluent API code that we may have. For example in this case, we used the following fluent API code to configure the User-Address association: |
modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress).WithRequired(); |
This reads as "User entity has an optional association with one Address object but this association is required for Address entity". For Code First this is good enough to make the decision: It marked User as the principal end and Address as the dependent end in the association. Since we have the same fluent API code for the second association between Address and Shipment, it marks Address as the principal end and Shipment as the dependent end in this association as well.
This decision has some consequences. In fact, the referential integrity that we saw, is the first result of this Code First's principal/dependent decision.
Second Result of Code First's Principal/Dependent Decision: Database Identity If you take a closer look at the above DB schema, you'll notice that only UserId has a regular identifier generator (aka Identity or Sequence) and AddressId and ShipmentId does not. This is a very important consequence of the principal/dependent decision for one-to-one associations: the dependent primary key will become non-Identity by default. This make sense because they share their primary key values and only one of them can be auto generated and we need to take care of providing valid keys for the rest. |
What about Cascade Deletes?As we saw, each Address always belongs to one User and each Shipment always delivered to one single Address. We want to make sure that when we delete a User the possible dependent rows on Address and Shipment also get deleted in the database. In fact, this is one of the Referential Integrity Refactorings which called Introduce Cascading Delete. The primary reason we would apply "Introduce Cascading Delete" is to preserve the referential integrity of our data by ensuring that related rows are appropriately deleted when a parent row is deleted. By default, Code First does not enable cascade delete when it creates a one-to-one relationship in the database. As always we can override this convention by fluent API: |
protected override void OnModelCreating(DbModelBuilder modelBuilder)
{
modelBuilder.Entity<User>().HasOptional(u => u.BillingAddress)
.WithRequired()
.WillCascadeOnDelete();
modelBuilder.Entity<Shipment>().HasRequired(u => u.DeliveryAddress)
.WithOptional()
.WillCascadeOnDelete();
} |
What the Additional Methods Like WithRequiredDependent are for?The HasRequired method returns an object of type RequiredNavigationPropertyConfiguration which defines two special methods called WithRequiredDependent and WithRequiredPrincipal in addition to the typical WithMany and WithOptional methods that we usually use. We saw that the only reason Code First could figure out principal and dependent in our associations was because our fluent API code clearly specified one end as Required and the other as Optional. But what if both endpoints are required or both are optional in the association? For example consider a scenario that a User always has one Address and Address always has one User (required on both end). Now Code First cannot pick up the principal and dependent ends on its own and that's exactly where methods like WithRequiredDependent come into play. In other words, this scenario ultimately need to be configured by fluent API and fluent API is designed in a way that will force you to explicitly specify who is dependent and who is principal in a required-required or optional-optional association scenario.
For example, this fluent API code shows how we can configure the User-Address association where both ends are required: |
modelBuilder.Entity<User>().HasRequired(u => u.BillingAddress).WithRequiredDependent();
|
| Taking a closer look at the RequiredNavigationPropertyConfiguration type also shows the idea: |
public class RequiredNavigationPropertyConfiguration<TEntityType, TTargetEntityType>
{
public DependentNavigationPropertyConfiguration<TEntityType, TTargetEntityType> WithMany();
public CascadableNavigationPropertyConfiguration WithOptional();
public CascadableNavigationPropertyConfiguration WithRequiredDependent();
public CascadableNavigationPropertyConfiguration WithRequiredPrincipal();
} |
| As you can see, if you want to go another Required after HasRequired method, you have to either call WithRequiredDependent or WithRequiredPrincipal since there is no WithRequired method defined on RequiredNavigationPropertyConfiguration class. |
Working with the ModelHere is an example for adding a new user along with its billing address. EF is smart enough to use the newly generated UserId for the AddressId as well: |
using (var context = new Context())
{
Address billingAddress = new Address()
{
Street = "Main St.",
City = "Seattle"
};
User user = new User()
{
Name = "Morteza",
BillingAddress = billingAddress
};
context.Users.Add(user);
context.SaveChanges();
} |
| The following code is an example of adding a new Address and Shipment for an existing User (assuming that we have a User with UserId = 1 in the database): |
using (var context = new Context())
{
Address deliveryAddress = new Address()
{
AddressId = 1,
Street = "Main St.",
};
Shipment shipment = new Shipment()
{
ShipmentId = 1,
State = "Shipped",
DeliveryAddress = deliveryAddress
};
context.Shipments.Add(shipment);
context.SaveChanges();
} |
Limitations of This MappingThere are two important limitations to associations mapped as shared primary key:
- Difficulty in Saving Related Objects
The main difficulty with this approach is ensuring that associated instances are assigned the same primary key value when the objects are saved. For example, when adding a new Address object, it's our responsibility to provide a unique AddressId that is also valid (a User can be found with such a value as UserId.)
- Multiple Addresses for User is Not Possible
With this mapping we cannot have more than one Address for User. At the beginning of this post, when we introduce our model, we assumed that the user has the same address for billing and delivery. But what if that's not the case? What if we also want to add a Home address to User for the deliveries? In the current setup, each row in the User table has at most one corresponding row in the Address table. Two addresses would require an additional address table, and this mapping style therefore wouldn’t be adequate.
SummaryIn this post we learned about one-to-one associations which shared primary key is just one way to implement it. Shared primary key associations aren’t uncommon but are relatively rare. In many schemas, a one-to-one association is represented with a foreign key field and a unique constraint. In the next posts we will revisit the same domain model and will learn about other ways to map one-to-one associations that does not have the limitations of the shared primary key association mapping.
|
References
|