Testing ASP.NET 2.0 and Visual Web Developer
Several people have asked for additional testing details
after my recent Whidbey Update
post where I talked a little about how we are building
ASP.NET 2.0 and Visual Web Developer.
Some specific
questions I’ve been asked include: How do you build and
track 105,000 test cases and 505,000 test scenarios? How big is the test team in relation to the dev team? What
tools do we use to write and run them?
What is the process
used to manage all of this? Etc, Etc. Hopefully
the below post provide some answers.
Test Team Structure
Our test team is staffed by engineers who own writing test
plans, developing automated tests, and building the test
infrastructure required to run and analyze them. The job title we use to describe this role at Microsoft is
SDE/T (Software Design Engineer in Test).
All members of the test team report through a Test Manager
(TM), and similarly all members of the development team and
program management team report through a Development Manager
(DM) and Group Program Manager (GPM) respectively. The TM, DM and GPM are peers who report to a Product Unit
Manager (PUM) who runs the overall product team (note: I'm
this guy).
This partitioned reporting structure has a couple of
benefits – one of the big ones being that it enables
specialization and focus across the entire team, and enables
deep career growth and skills mentoring for each job
type. It also helps
ensure that design, development and testing each get the
focus they need throughout the product cycle.
In terms of staffing ratios, our test team is actually the
largest of the three disciplines on my team. We currently have approximately 1.4 testers for every 1
developer.
Why is the test team larger than the development
team?
I think there are two main reasons for this on my team:
1) We take quality pretty seriously at Microsoft – hence the reason we invest the time and resources.
2) We also have a lot of very hard requirements that
necessitate a heck of a lot of careful planning and work to
ensure high quality.
For ASP.NET 2.0 and Visual Web Developer, we have to be able
to deliver a super high quality product that is rock solid
from a functional perspective, can run the world’s largest
sites/applications for months without hiccups, is
bullet-proof secure, and is faster than previous versions
despite having infinitely more features (do a file size diff
on System.Web.dll comparing V2 with V1.1 and you’ll see that
it is 4 times larger).
Now doing all of the above is challenging. What makes it even harder is the fact that we need to
deliver it on the same date on three radically different
processor architectures (x86, IA-64, and x64 processor
architectures), on 4 different major OS variations (Windows
2000, Windows XP, Windows 2003 and Longhorn), support
design-time scenarios with 7 different Visual Studio SKUs,
and be localized into 34+ languages (including BiDi
languages which bring unique challenges).
Making things even more challenging is the fact that
Microsoft supports all software for at least 10 years after
the date of its release – which means that customers at any
point during that timeframe can report a problem and request
a QFE fix. We’ll
also then do periodic service packs (SPs) rolling up these
fixes during these 10 years as well.
Each QFE or SP needs to be fully verified to ensure that it
does not cause a functional, stress or performance
regression. Likewise, my team needs to ensure that any widely
distributed change (for example: a security GDR) to Windows,
CLR or Visual Studio (all of whom we sit on top of) doesn’t
cause regressions in our products either. We’ll probably end up having to-do approximately 25 of
these servicing analysis runs on a single product release in
a given year. If you
have multiple products released within a 10 year window,
then you end up multiplying this number times the number of
releases. It quickly
gets large.
What is our process for testing?
Our high-level process for testing involves three essential
steps:
1)
We build detailed test plans that comprehensively cover all
product scenarios
2)
We automate the test scenarios in the test plans to
eliminate the need for manual steps to test or verify
functionality
3)
We build and maintain infrastructure that enables us to
rapidly run, analyze and report the status of these
automated tests
Test Plans
Test plans are the first step, and happen as early as
possible in the product cycle. A separate test plan will be written by a tester for each
feature or feature area of the product. The goal with them is to comprehensively detail all of the
scenarios needed to test a given feature.
The test plan will
group each of these scenarios into a test case (where 1 test
case might have up to 10 or more separately verified
scenarios), and assign a priority (P1, P2, or P3) to each
test case.
The entire feature team (pm, dev, and test) will get
together during a coding milestone to review the test plan
and try to ensure that no scenarios are missing. The team will then use the test plan as the blueprint when
they go to write and automate tests, and they will implement
the test scenarios in the priority order defined by the
plan.
During the product cycle we’ll often find new scenarios not
covered by the original test plan. We call these missing scenarios “test holes”, and when
found they’ll be added to the test plan and be
automated. Every new
bug opened during the product cycle will also be analyzed by
test to ensure that it would be found by the test plan -- if
not, a new test case is added to cover it.
Here is a pointer to a few pages from the test plan of our new GridView data control in ASP.NET 2.0: http://www.scottgu.com/blogposts/testingatmicrosoft/testplan/testplan.htm
The full test plan for this feature is 300+ pages and
involves thousands of total scenarios – but hopefully this
snippet provides a taste for what the overall document looks
like. Note that some
of the test cases have a number associated with them (look
at the first AutoFormat one) – this indicates that this test
case was missed during the original review of the document
(meaning a test hole) and has been added in response to bugs
being opened (110263 is the bug number).
Test Automation
After testers finalize their test plans, they will start
writing and automating the tests defined within them. We use a variety of languages to test the product, and like
to have a mixture of C#, VB and some J# so as to exercise
the different compilers in addition to our own product.
Tests on my team are written using a testing framework that
we’ve built internally. Long term we’ll use vanilla VSTS (Visual Studio Team
System) infrastructure more and more, but given that they
are still under active development we aren’t using it for
our Whidbey release. The teams actually building the VSTS technology, though,
are themselves “dogfooding” their own work and use it for
their source control and testing infrastructure (and it is
definitely being designed to handle internal Microsoft team
scenarios). One of
the really cool things about VSTS is that when it is
released, you’ll be able to take all of the process
described in this blog and apply it to your own
projects/products with full Visual Studio infrastructure
support.
My team’s test framework is optimized to enable a variety of
rich web scenarios to be run, and allows us to automatically
run tests under custom scenario contexts without test case
modification. For
example, we can automatically choose to run a DataGrid test
within a code access security context, or under different
process model accounts/settings, or against a UNC network
share, etc – without having to ever have the DataGrid test
be aware of the environment it is running in.
The test cases themselves are often relatively straight forward and not too code-heavy. Instead, the bulk of the work goes into the shared test libraries that are shared across test scenarios and test cases. Here is a pointer to an example test case written for our new WebPart personalization framework in ASP.NET 2.0: http://www.scottgu.com/blogposts/testingatmicrosoft/testcase/testcase.htm
Note how the test case contains a number of distinct
scenarios within it – each of which is verified along the
way. This test case
and the scenarios contained within it will match the test
plan exactly. Each
scenario is then using a common WebPart automation test
library built by the SDE/T that enables heavy re-use of code
across test cases.
My team will have ~105,000 test cases and ~505,000
functional test scenarios covered when we ship Whidbey. Our hope/expectation is that these will yield us ~80-90%
managed code block coverage of the products when we
ship.
We use this code coverage number as a rough metric to track
how well we are covering test scenarios with our functional
tests. By code
“blocks” we mean a set of statements in source code – and
90% block coverage would mean that after running all these
functional tests 90% of the blocks have been exercised. We also then measure “arc” coverage, which includes
measuring further individual code paths within a block (for
example: a switch statement might count as a block – where
each case statement within it would count as a separate
arc). We measure
both block and arc numbers regularly along the way when we
do full test passes (like we are doing this week) to check
whether we are on target or not. One really cool thing about VS 2005 is that VSTS includes
support to automatically calculate code coverage for you –
and will highlight your code in the source editor red/green
to show which blocks and arcs of your code were exercised by
your test cases.
There is always a percentage of code that cannot be easily
exercised using functional tests (common examples:
catastrophic situations involving a process running out of
memory, difficult to reproduce threading scenarios,
etc). Today we
exercise these conditions using our stress lab – where we’ll
run stress tests for days/weeks on end and put a variety of
weird load and usage scenarios on the servers (for example:
we have some tests that deliberately leak memory, some that
AV every once in awhile, some that continually modify
.config files to cause app-domain restarts under heavy load,
etc). Stress is a
whole additional blog topic that I’ll try and cover at some
point in the future to give it full justice. Going forward, my team is also moving to a model where
we’ll also add more fault-injection specific tests to our
functional test suites to try and get coverage of these
scenarios through functional runs as well.
Running Tests
So once you have 105,000 tests – what do you do with
them? Well, the
answer is run them regularly on the product – carefully
organizing the runs to make sure that they cover all of the
different scenarios we need to hit when we ship (example:
different processor architectures, different OS versions,
different languages, etc).
My team uses an internally built system we affectionately
call “Maddog” to handle managing and running our tests. Post Whidbey my team will be looking to transition to a
VSTS one, but for right now Maddog is the one we use.
Maddog does a couple of things for my team, including:
managing test plans, managing test cases, providing a build
system to build and deploy all test suites we want to
execute during a given test run, providing infrastructure to
image servers to run and execute our tests, and ultimately
providing a reporting system so that we can analyze failures
and track the results.
My team currently has 4 labs where we keep approximately
1,200 machines that Maddog helps coordinate and keep
busy. The machines
vary in size and quality – with some being custom-built
towers and others being rack-mounts. Here is a picture of what one row (there are many, many,
many of them) in one of labs in building 42 looks like:

The magic happens when we use Maddog to help coordinate and
use all these machines. A tester can use Maddog within their office to build a
query of tests to run (selecting either a sub-node of
feature areas – or doing a search for tests based on some
other criteria), then pick what hardware and OS version the
tests should run on, pick what language they should be run
under (Arabic, German, Japanese, etc), what ASP.NET and
Visual Studio build should be installed on the machine, and
then how many machines it should be distributed over.
Maddog will then identify free machines in the lab,
automatically format and re-image them with the appropriate
operating system, install the right build on them, build and
deploy the tests selected onto them, and then run the
tests. When the run
is over the tester can examine the results within Maddog,
investigate all failures, publish the results (all through
the Maddog system), and then release the machines for other
Maddog runs. Published test results stay in the system forever (or until
we delete them) – allowing test leads and my test manager to
review them and make sure everything is getting covered. All
this gets done without the tester ever having to leave their
office.
Below are some MadDog screenshots walking-through this process. Click on any of the pictures to see a full-size version of them.
Picture 1: This shows browsing the tests in our test case system. This can be done both hierarchically by feature area and via a feature query.
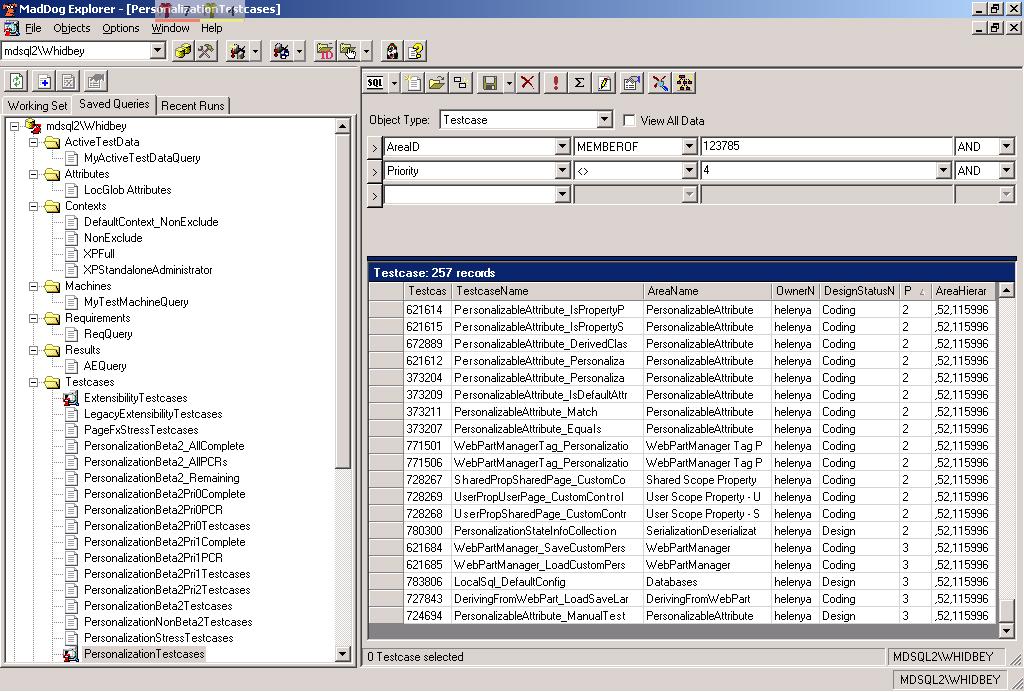
(click the picture above to see a full-size version of it)
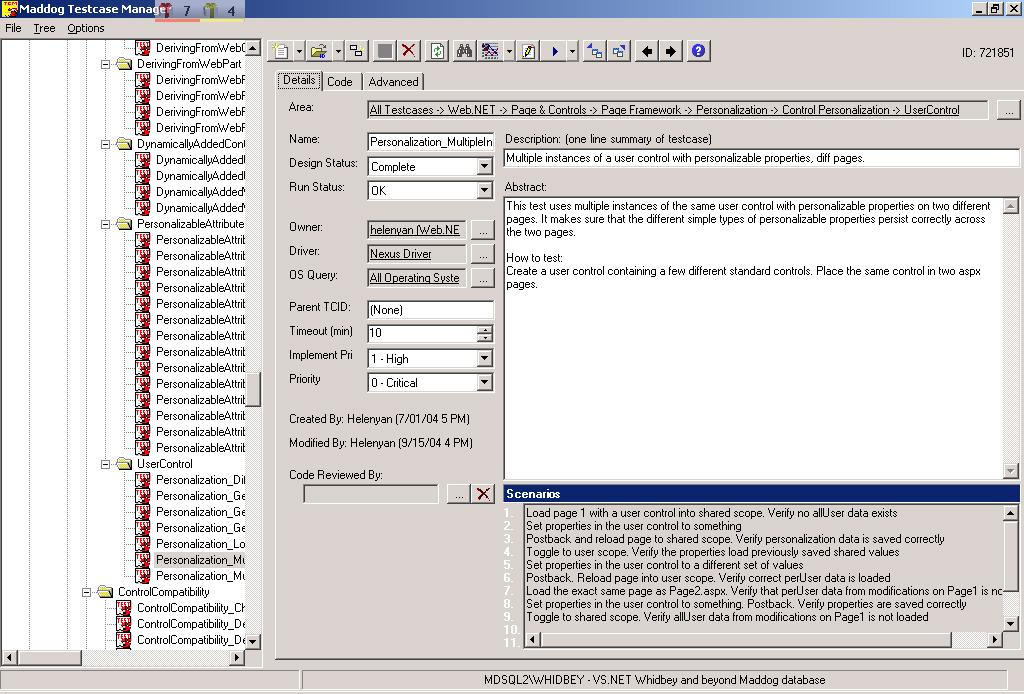
Picture 2: This shows looking at one of the 105,000 test
cases in more detail. Note that the test case plan and scenarios are stored in
MadDog.
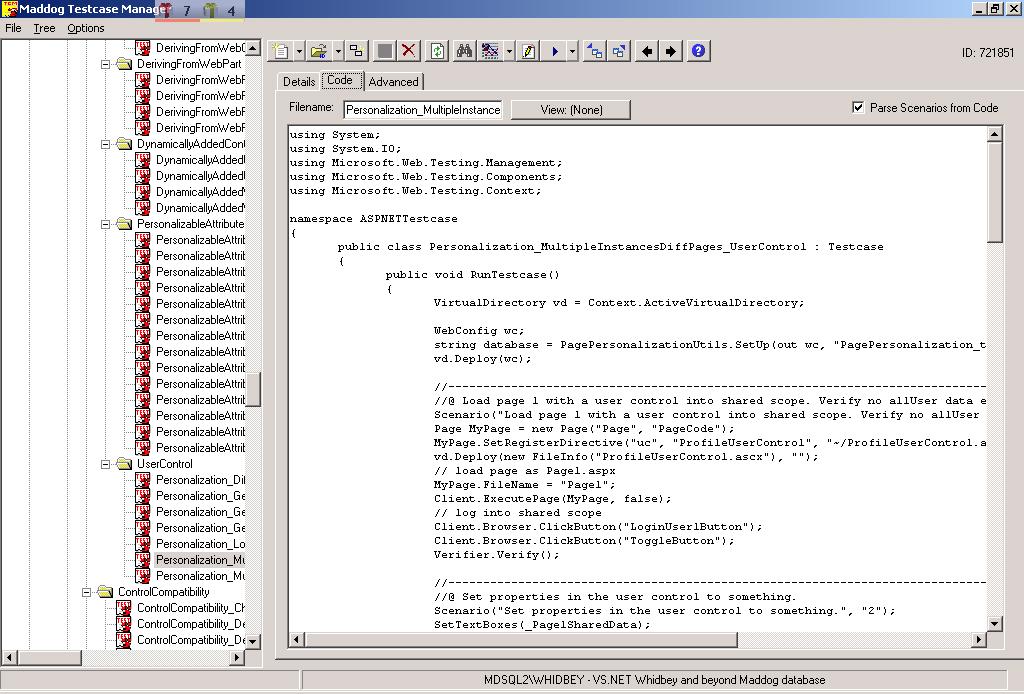
Picture 3: This shows how code for the test case is also
stored in MadDog – allowing us to automatically compile and
build the test harness based on what query of tests is
specified.
Picture 4: This shows what a test looks like when run. Note the interface is very similar to what VSTS does when
running a web scenario.
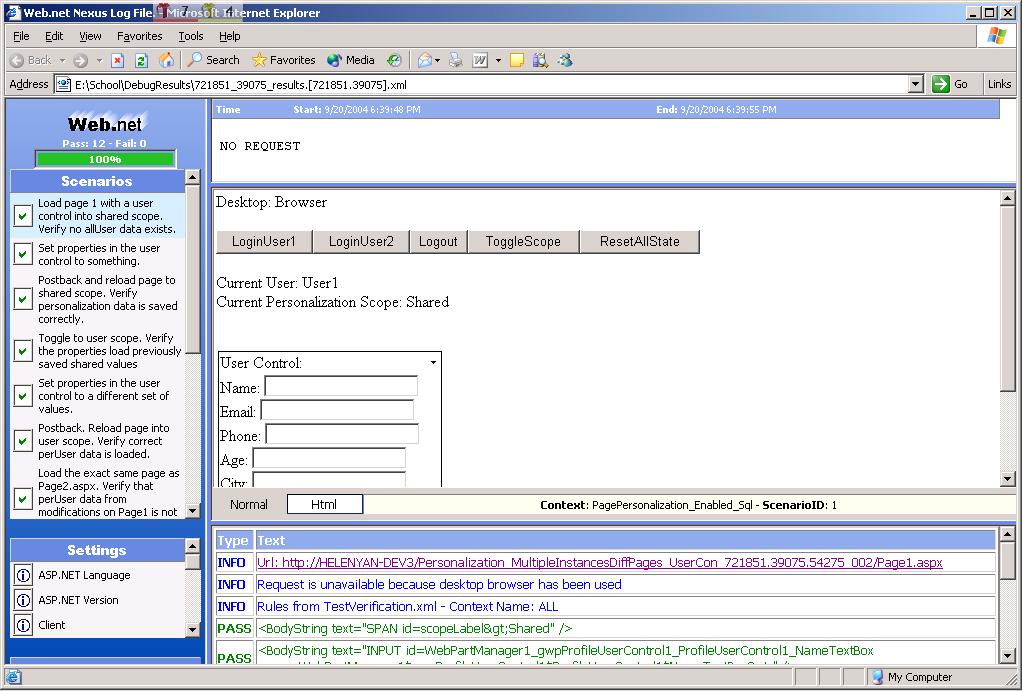
(click the picture above to see a full-size version of it)
Picture 5: This shows how to pick a test query as part of a
new test run (basically choosing what test cases to include
as part of the run)
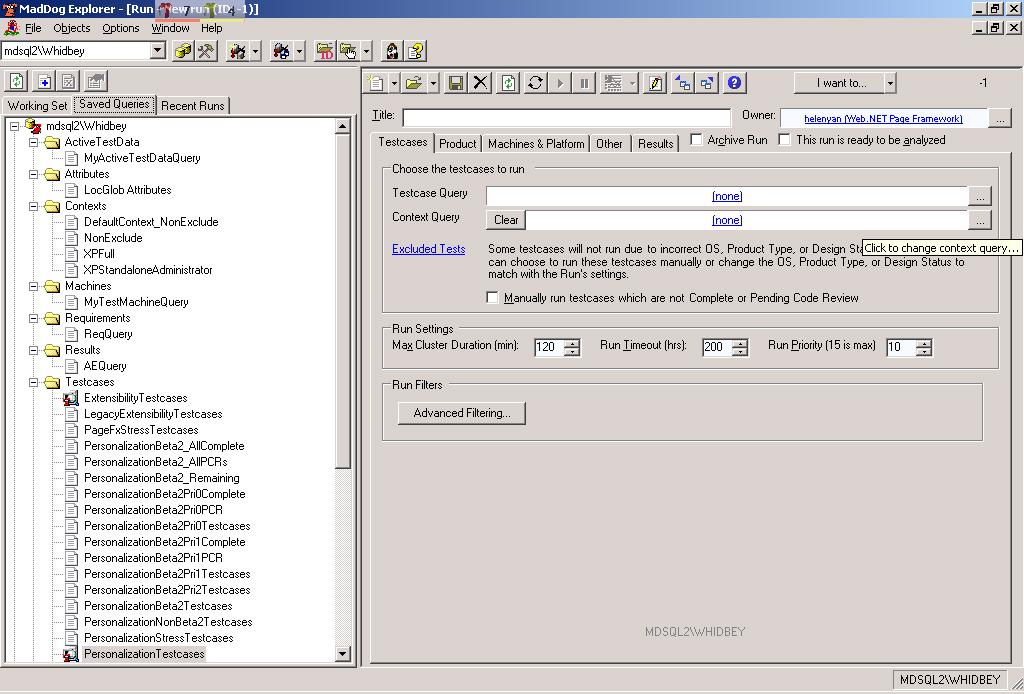
(click the picture above to see a full-size version of it)
Picture 6: This shows picking what build of ASP.NET and
Visual Studio to install on one of the test run
machines.
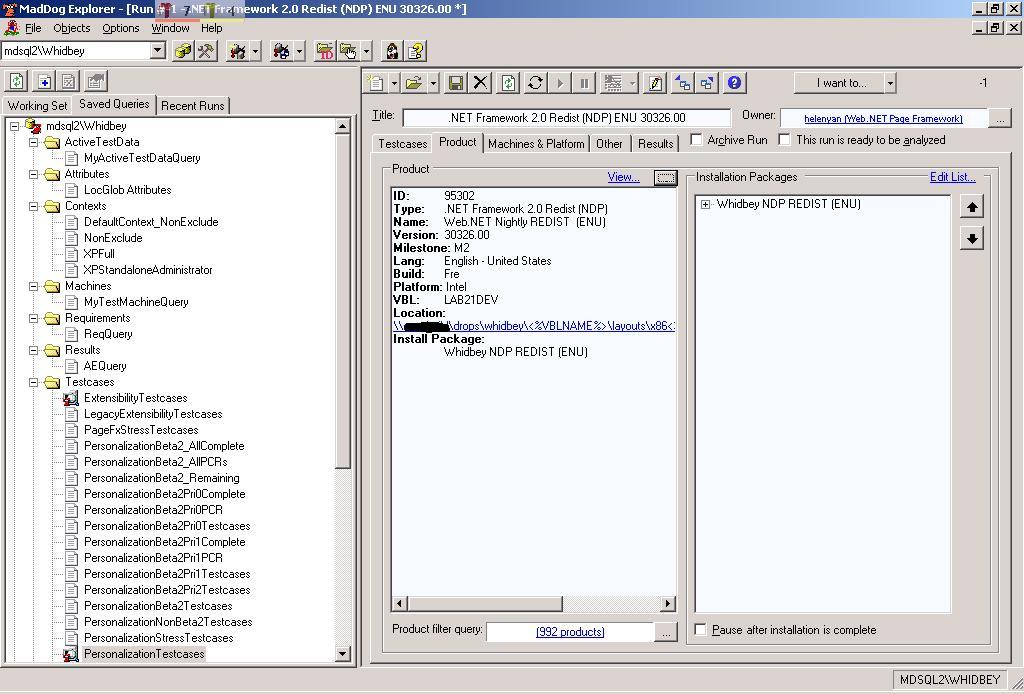
(click the picture above to see a full-size version of it)
Picture 7: This shows picking what OS image to install on
the machines (in this case Japanese Windows Server 2003 on
x86), and how many machines to distribute the tests
across.
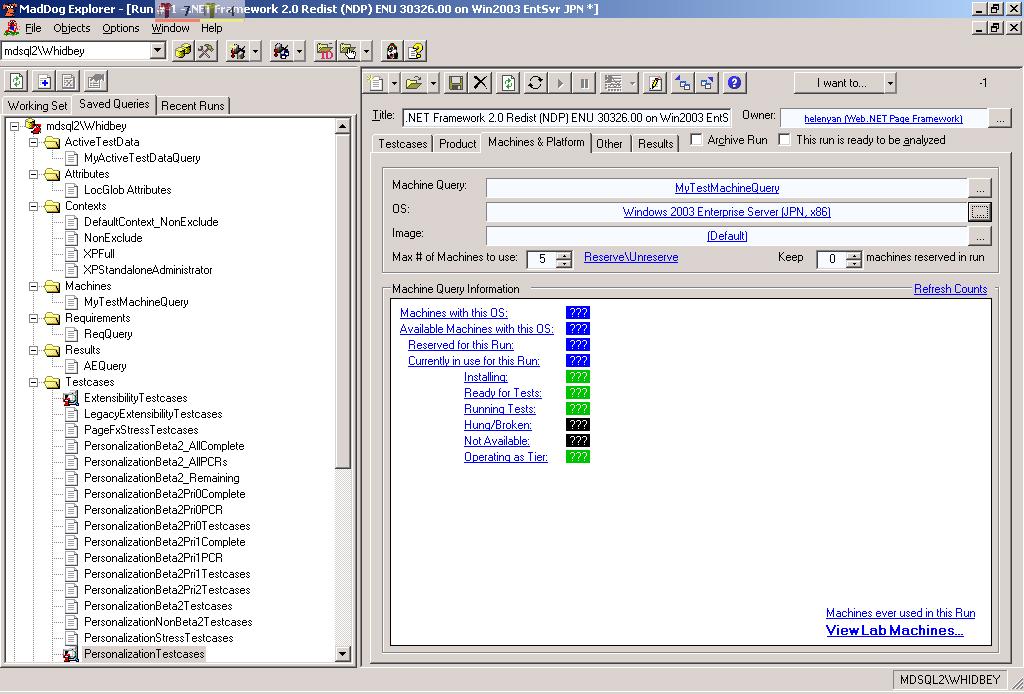
(click the picture above to see a full-size version of it)
After everything is selected above, the tester can hit “go”
and launch the test run. Anywhere from 30 minutes to 14 hours later it will be done
and ready to be analyzed.
What tests are run when?
We run functional tests on an almost daily basis. As I mentioned earlier, we do a functional run on our
shipping products every time we release a patch or QFE. We also do a functional run anytime a big software
component in Microsoft releases a GDR (for example: a
security patch to Windows).
With ASP.NET 2.0 and Visual Web Developer we’ll usually try
and run a subset of our tests 2-3 times a week. This subset contains all of our P0 test cases and provides
broad breadth coverage of the product (about 12% of our
total test cases). We’ll then try and complete a full automation run every 2-3
weeks that includes all
As we get closer to big milestone or product events (like a
ZBB, Beta or RTM), we’ll do a full test pass where we’ll run
everything – including manually running those tests that
aren’t automated yet (as I mentioned in my earlier blog post
– my team is doing this right now for our Beta2 ZBB
milestone date).
Assuming we’ve kept test holes to a minimum, have deep code
coverage throughout all features of the product, and the dev
team fixes all the bugs that are found – then we’ll end up
with a really, really solid product.
Summary
There is an old saying with software that three years from
now, no one will remember if you shipped an awesome software
release a few months late. What customers
will still
remember three years from now is if you shipped a software
release that wasn’t ready a few months too soon. It takes multiple product releases to change people’s
quality perception about one bad release.
Unfortunately there are no easy silver bullets to building super high quality software -- it takes good engineering discipline, unwillingness to compromise, and a lot of really hard work to get there. We are going to make very sure we deliver on all of this with ASP.NET 2.0 and Visual Web Developer.
November 3rd Update: For more details on how we track and manage bugs please read this new post: http://weblogs.asp.net/scottgu/archive/2004/11/03/251930.aspx