LINQ to SQL (Part 4 - Updating our Database)
Over the last few weeks I've been writing a series of blog posts that cover LINQ to SQL. LINQ to SQL is a built-in O/RM (object relational mapper) that ships in the .NET Framework 3.5 release, and which enables you to easily model relational databases using .NET classes. You can use LINQ expressions to query the database with them, as well as update/insert/delete data.
Below are the first three parts of my LINQ to SQL series:
- Part 1: Introduction to LINQ to SQL
- Part 2: Defining our Data Model Classes
- Part 3: Querying our Database
In today's blog post I'll cover how we we can use the data model we created earlier, and use it to update, insert, and delete data. I'll also show how we can cleanly integrate business rules and custom validation logic with our data model.
Northwind Database Modeled using LINQ to SQL
In Part 2 of this series I walked through how to create a LINQ to SQL class model using the LINQ to SQL designer that is built-into VS 2008. Below is a class model created for the Northwind sample database and which I'll be using in this blog post:
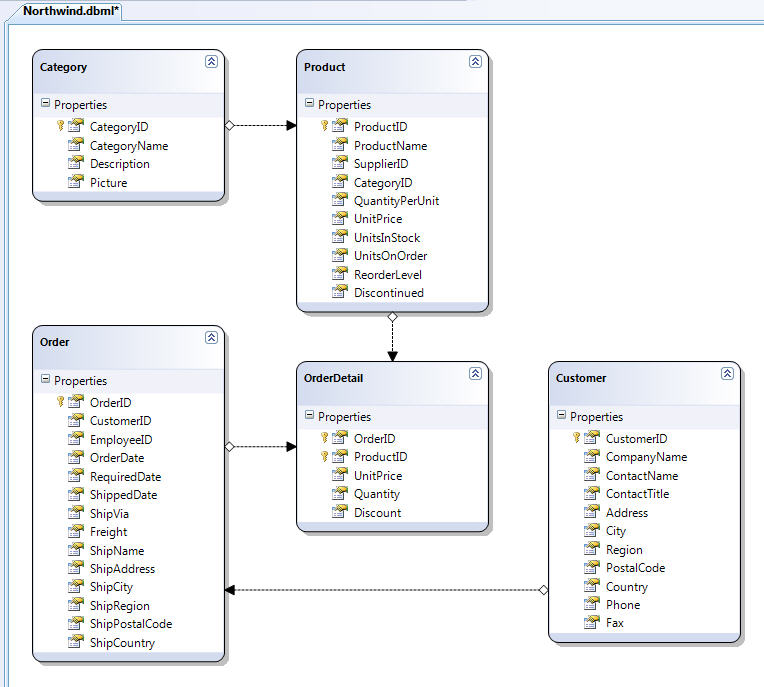
When we designed our data model using the LINQ to SQL data designer above we defined five data model classes: Product, Category, Customer, Order and OrderDetail. The properties of each class map to the columns of a corresponding table in the database. Each instance of a class entity represents a row within the database table.
When we defined our data model, the LINQ to SQL designer also created a custom DataContext class that provides the main conduit by which we'll query our database and apply updates/changes. In the example data model we defined above this class was named "NorthwindDataContext". The NorthwindDataContext class has properties that represent each Table we modeled within the database (specifically: Products, Categories, Customers, Orders, OrderDetails).
As I covered in Part 3 of this blog series, we can easily use LINQ syntax expressions to query and retrieve data from our database using this NorthwindDataContext class. LINQ to SQL will then automatically translate these LINQ query expressions to the appropriate SQL code to execute at runtime.
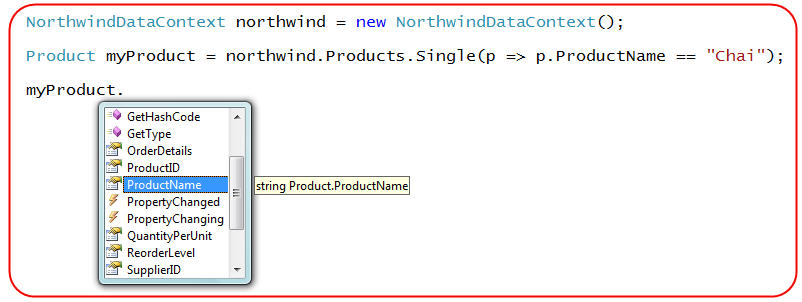
For example, I could write the below LINQ expression to retrieve a single Product object by searching on the Product name:
I could then write the LINQ query expression below to retrieve all products from the database that haven't yet had an order placed for them, and which also cost more than $100:

Note above how I am using the "OrderDetails" association for each product as part of the query to only retrieve those products that have not had any orders placed for them.
Change Tracking and DataContext.SubmitChanges()
When we perform queries and retrieve objects like the product instances above, LINQ to SQL will by default keep track of any changes or updates we later make to these objects. We can make any number of queries and changes we want using a LINQ to SQL DataContext, and these changes will all be tracked together.
Note: LINQ to SQL change tracking happens on the consuming caller side - and not in the database. This means that you are not consuming any database resources when using it, nor do you need to change/install anything in the database to enable it.
After making the changes we want to the objects we've retrieved from LINQ to SQL, we can then optionally call the "SubmitChanges()" method on our DataContext to apply the changes back to the database. This will cause LINQ to SQL to dynamically calculate and execute the appropriate SQL code to update the database.
For example, I could write the below code to update the price and # of units in stock of the "Chai" product in the database:
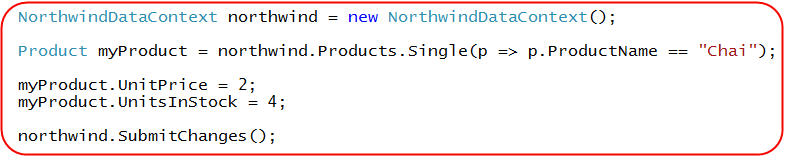
When I call northwind.SubmitChanges() above, LINQ to SQL will dynamically construct and execute a SQL "UPDATE" statement that will update the two product property values we modified above.
I could then write the below code to loop over unpopular, expensive products and set the "ReorderLevel" property of them to zero:
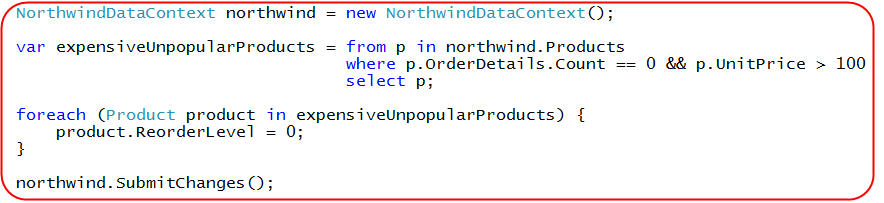
When I call northwind.SubmitChanges() above, LINQ to SQL will calculate and execute an appropriate set of UPDATE statements to modify the products who had their ReorderLevel property changed.
Note that if a Product's property values weren't changed by the property assignments above, then the object would not be considered changed and LINQ to SQL would therefore not execute an update for that product back to the database. For example - if the "Chai" product's unitprice was already $2 and the number of units in stock was 4, then calling SubmitChanges() would not cause any database update statements to execute. Likewise, only those products in the second example whose ReorderLevel was not already 0 would be updated when the SubmitChanges() method was called.
Insert and Delete Examples
In addition to updating existing rows in the database, LINQ to SQL obviously also enables you to insert and delete data. You can accomplish this by adding/removing data objects from the DataContext's table collections, and by then calling the SubmitChanges() method. LINQ to SQL will keep track of these additions/removals, and automatically execute the appropriate SQL INSERT or DELETE statements when SubmitChanges() is invoked.
Inserting a New Product
I can add a new product to my database by creating a new "Product" class instance, setting its properties, and then by adding it to my DataContext's "Products" collection:
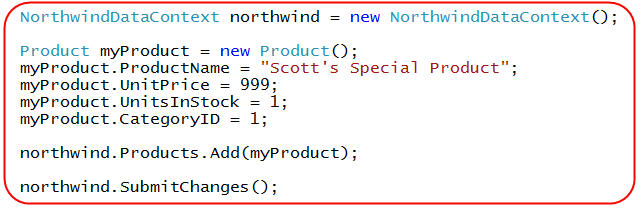
When we call "SubmitChanges()" above a new row will be created in our products table.
Deleting Products
Just as I can express that I want to add a new Product to the database by adding a Product object into the DataContext's Products collection, I can likewise express that I want to delete a product from a database by removing it from the DataContext's Products collection:
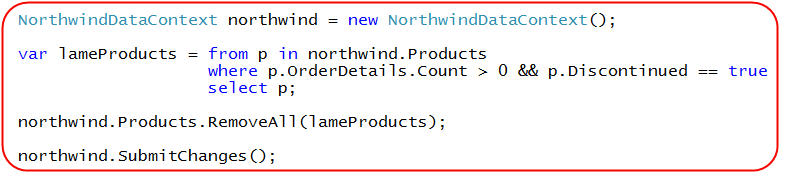
Note above how I'm retrieving a sequence of discontinued products that no one has ever ordered using a LINQ query, and then passing it to the RemoveAll() method on my DataContext's "Products" collection. When we call "SubmitChanges()" above all of these Product rows will be deleted from our products table.
Updates across Relationships
What makes O/R mappers like LINQ to SQL extremely flexible is that they enable us to easily model cross-table relationships across our data model. For example, I can model each Product to be in a Category, each Order to contain OrderDetails for line-items, associate each OrderDetail line-item with a Product, and have each Customer contain an associated set of Orders. I covered how to construct and model these relationships in Part 2 of this blog series.
LINQ to SQL enables me to take advantage of these relationships for both querying and updating my data. For example, I could write the below code to create a new Product and associate it with an existing "Beverages" category in my database like so:
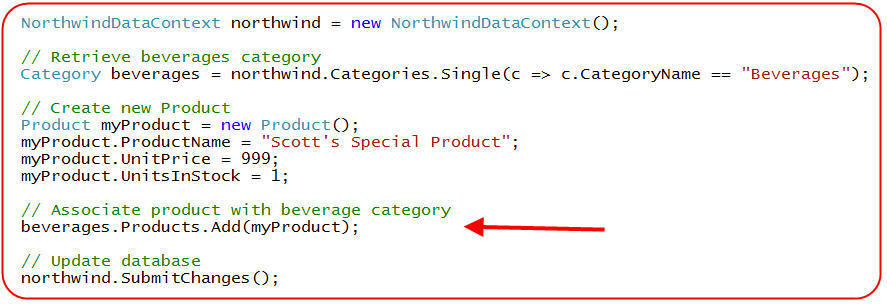
Note above how I'm adding the Product object into the Category's Products collection. This will indicate that there is a relationship between the two objects, and cause LINQ to SQL to automatically maintain the foreign-key/primary key relationship between the two when I call "SubmitChanges()".
For another example of how LINQ to SQL can help manage cross-table relationships for us and help clean up our code, let's look at an example below where I'm creating a new Order for an existing customer. After setting the required ship date and freight costs for the order, I then create two order line-item objects that point to the products the customer is ordering. I then associate the order with the customer, and update the database with all of the changes.
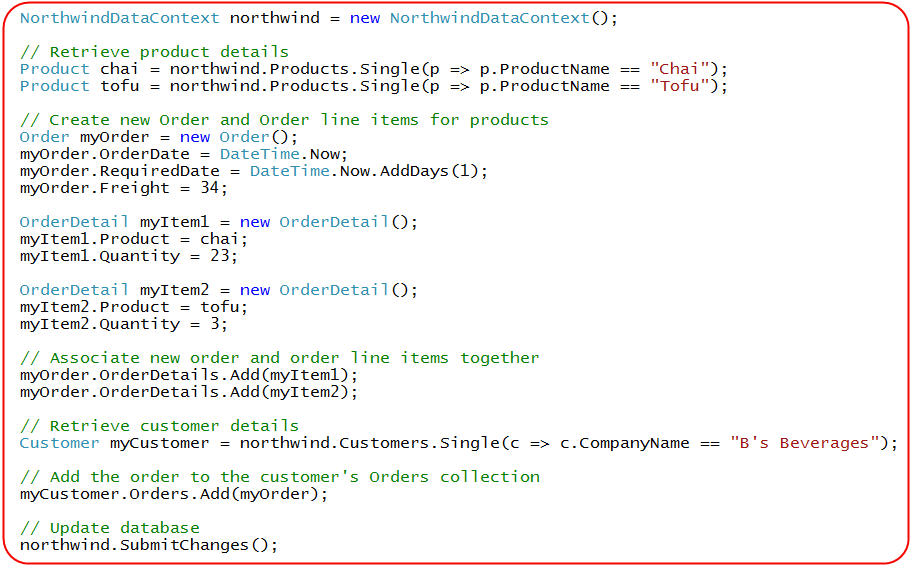
As you can see, the programming model for performing all of this work is extremely clean and object oriented.
Transactions
A transaction is a service provided by a database (or other resource manager) to guarantee that a series of individual actions occur atomically - meaning either they all succeed or they all don't, and if they don't then they are all automatically undone before anything else is allowed to happen.
When you call SubmitChanges() on your DataContext, the updates will always be wrapped in a Transaction. This means that your database will never be in an inconsistent state if you perform multiple changes - either all of the changes you've made on your DataContext are saved, or none of them are.
If no transaction is already in scope, the LINQ to SQL DataContext object will automatically start a database transaction to guard updates when you call SubmitChanges(). Alternatively, LINQ to SQL also enables you to explicitly define and use your own TransactionScope object (a feature introduced in .NET 2.0). This makes it easier to integrate LINQ to SQL code with existing data access code you already have. It also means that you can enlist non-database resources into the transaction - for example: you could send off a MSMQ message, update the file-system (using the new transactional file-system support), etc - and scope all of these work items in the same transaction that you use to update your database with LINQ to SQL.
Validation and Business Logic
One of the important things developers need to think about when working with data is how to incorporate validation and business rule logic. Thankfully LINQ to SQL supports a variety of ways for developers to cleanly integrate this with their data models.
LINQ to SQL enables you to add this validation logic once - and then have it be honored regardless of where/how the data model you've created is used. This avoids you having to repeat logic in multiple places, and leads to a much more maintainable and clean data model.
Schema Validation Support
When you define your data model classes using the LINQ to SQL designer in VS 2008, they will by default be annotated with some validation rules inferred from the schema of the tables in the database.
The datatypes of the properties in the data model classes will match the datatypes of the database schema. This means you will get compile errors if you attempt to assign a boolean to a decimal value, or if you attempt to implicitly convert numeric types incorrectly.
If a column in the database is marked as being nullable, then the corresponding property in the data model class created by the LINQ to SQL designer will be a nullable type. Columns not marked as nullable will automatically raise exceptions if you attempt to persist an instance with a null value. LINQ to SQL will likewise ensure that identity/unique column values in the database are correctly honored.
You can obviously use the LINQ to SQL designer to override these default schema driven validation settings if you want - but by default you get them automatically and don't have to take any additional steps to enable them. LINQ to SQL also automatically handles escaping SQL values for you - so you don't need to worry about SQL injection attacks when using it.
Custom Property Validation Support
Schema driven datatype validation is useful as a first step, but usually isn't enough for real-world scenarios.
Consider for example a scenario with our Northwind database where we have a "Phone" property on the "Customer" class which is defined in the database as an nvarchar. Developers using LINQ to SQL could write code like below to update it using a valid telephone number:

The challenge that we will run into with our application, however, is that the below code is also legal from a pure SQL schema perspective (because it is still a string even though it is not a valid phone number):

To prevent bogus phone numbers from being added into our database, we can add a custom property validation rule to our Customer data model class. Adding a rule to validate phone numbers using this feature is really easy. All we need to-do is to add a new partial class to our project that defines the method below:
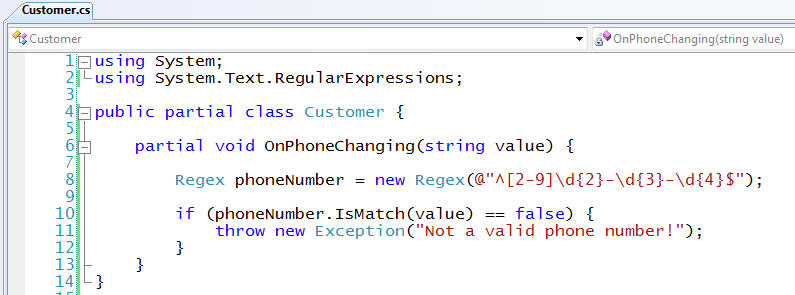
The code above takes advantage of two characteristics of LINQ to SQL:
1) All classes created by the LINQ to SQL designer are declared as "partial" classes - which means that developers can easily add additional methods, properties, and events to them (and have them live in separate files). This makes it very easy to augment the data model classes and DataContext classes created by the LINQ to SQL designer with validation rules and additional custom helper methods that you define. No configuration or code wire-up is required.
2) LINQ to SQL exposes a number of custom extensibility points in its data model and DataContext classes that you can use to add validation logic before and after things take place. Many of these extensibility points utilize a new language feature called "partial methods" that is being introduced with VB and C# in VS 2008 Beta2. Wes Dyer from the C# team has a good explanation of how partial methods works in this blog post here.
In my validation example above, I'm using the OnPhoneChanging partial method that is executed anytime someone programmatically sets the "Phone" property on a Customer object. I can use this method to validate the input however I want (in this case I'm using a regular expression). If everything passes successfully, I just return from the method and LINQ to SQL will assume that the value is valid. If there are any issues with the value, I can raise an exception within the validation method - which will prevent the assignment from taking place.
Custom Entity Object Validation Support
Property level validation as used in the scenario above is very useful for validating individual properties on a data model class. Sometimes, though, you want/need to validate multiple property values on an object against each other.
Consider for example a scenario with an Order object where you set both the "OrderDate" and the "RequiredDate" properties:
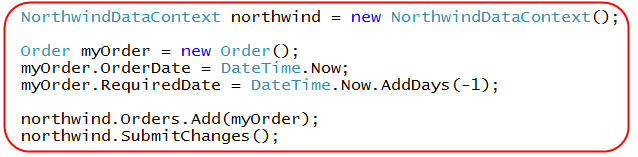
The above code is legal from a pure SQL database perspective - even though it makes absolutely no sense for the required delivery date of the new order to be entered as yesterday.
The good news is that LINQ to SQL in Beta2 makes it easy for us to add custom entity level validation rules to guard against mistakes like this from happening. We can add a partial class for our "Order" entity and implement the OnValidate() partial method that will be invoked prior to the entity's values being persisted into the database. Within this validation method we can then access and validate all of the data model class properties:
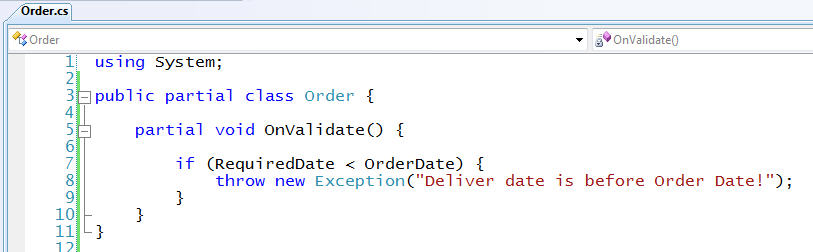
Within this validation method I can check any of the entity's property values (and even obtain read-only access to its associated objects), and raise an exception as needed if the values are incorrect. Any exceptions raised from the OnValidate() method will abort any changes from being persisted in the database, and rollback all other changes in the transaction.
Custom Entity Insert/Update/Delete Method Validation
There are times when you want to add validation logic that is specific to insert, update or delete scenarios. LINQ to SQL in Beta2 enables this by allowing you to add a partial class to extend your DataContext class and then implement partial methods to customize the Insert, Update and Delete logic for your data model entities. These methods will be called automatically when you invoke SubmitChanges() on your DataContext.
You can add appropriate validation logic within these methods - and if it passes then tell LINQ to SQL to continue with persisting the relevant changes to the database (by calling the DataContext's "ExecuteDynamicXYZ" method):
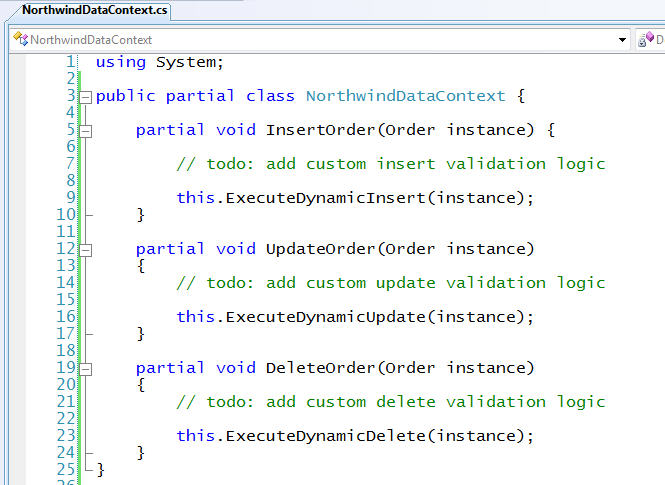
What is nice about adding the above methods is that the appropriate ones are automatically invoked regardless of the scenario logic that caused the data objects to be created/updated/deleted. For example, consider a simple scenario where we create a new Order and associate it with an existing Customer:
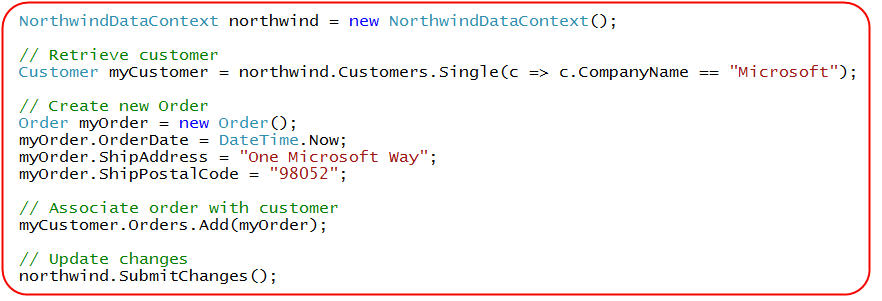
When we call northwind.SubmitChanges() above, LINQ to SQL will determine that it needs to persist a new Order object, and our "InsertOrder" partial method will automatically be invoked.
Advanced: Looking at the Entire Change List for the Transaction
There are times when adding validation logic can't be done purely by looking at individual insert/update/delete operations - and instead you want to be able to look at the entire change list of operations that are occurring for a transaction.
Starting with Beta2 of .NET 3.5, LINQ to SQL now enables you to get access to this change list by calling the public DataContext.GetChangeList() method. This will return back a ChangeList object that exposes collections of each addition, removal and modification that has been made.
One approach you can optionally employ for advanced scenarios is to sub-class the DataContext class and override its SubmitChange() method. You can then retrieve the ChangeList() for the update operation and perform any custom validation you want prior to executing it:
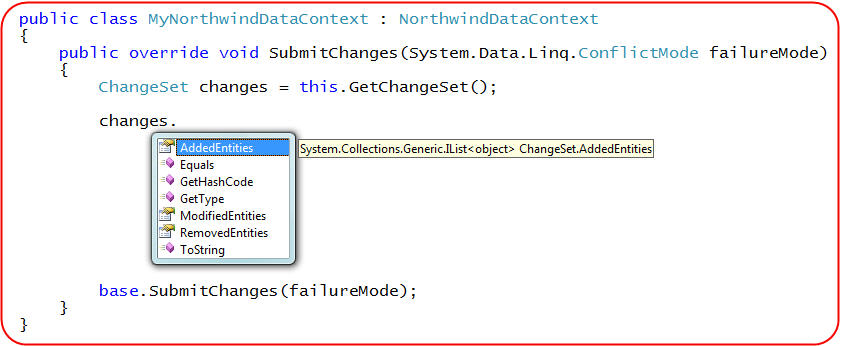
The above scenario is a somewhat advanced one - but it is nice to know that you always have the ability to drop-down and take advantage of it if needed.
Handling Simultaneous Changes with Optimistic Concurrency
One of the things that developers need to think about in multi-user database systems is how to handle simultaneous updates of the same data in the database. For example, assume two users retrieve a product object within an application, and one of the users changes the ReorderLevel to 0 while the other changes it to 1. If both users then attempt to save the product back to the database, the developer needs to decide how to handle the change conflicts.
One approach is to just "let the last writer win" - which means that the first user's submitted value will be lost without the end-users realizing it. This is usually considered a poor (and incorrect) application experience.
Another approach which LINQ to SQL supports is to use an optimistic concurrency model - where LINQ to SQL will automatically detect if the original values in the database have been updated by someone else prior to the new values being persisted. LINQ to SQL can then provide a conflict list of changed values to the developer and enable them to either reconcile the differences or provide the end-user of the application with UI to indicate what they want to-do.
I'll cover how to use optimistic concurrency with LINQ to SQL in a future blog post.
Using SPROCs or Custom SQL Logic for Insert/Update/Delete Scenarios
One of the questions that developers (and especially DBAs) who are used to writing SPROCs with custom SQL usually ask when seeing LINQ to SQL for the first time is - "but how can I have complete control of the underlying SQL that is executed?"
The good news is that LINQ to SQL has a pretty flexible model that enables developers to override the dynamic SQL that is automatically executed by LINQ to SQL, and instead call custom insert, update, delete SPROCs that they (or a DBA) define themselves.
What is really nice is that you can start off by defining your data model and have LINQ to SQL automatically handle the insert, update, delete SQL logic for you. You can then at a later point customize the data model to use your own custom SPROCs or SQL for updates - without having to change any of the application logic that is using your data model, nor would you have to change any of the validation or business rules logic supporting it (all of this stays the same). This provides a lot of flexibility in how you build your application.
I'll cover how to customize your data models to use SPROCs or custom SQL in a future blog post.
Summary
Hopefully the above post provides a good summary of how you can easily use LINQ to SQL to update your database, and cleanly integrate validation and business logic with your data models. I think you'll find that LINQ to SQL can dramatically improve your productivity when working with data, and enable you to write extremely clean object-oriented data access code.
In upcoming blog posts in this series I'll cover the new <asp:linqdatasource> control coming in .NET 3.5, and talk about how you can easily build data UI in ASP.NET that takes advantage of LINQ to SQL data models. I'll also cover some more specific LINQ to SQL programming concepts including optimistic concurrency, lazy and eager loading, table mapping inheritance, custom SQL/SPROC usage, and more.
Hope this helps,
Scott