
The Data Loader Object design pattern: Lightweight Containers, Inversion of Control, Abstract Factory
Sami Jaber published
a
new article on DotNetGuru
(in French,
but to be translated soon on the
English DotNetGuru
- Update: now
available in English) about lightweight containers such as Pico,
Spring, Avalon or HiveMind. As a complete gringo to J2EE,
this notion of containers and
Inversion of Control
was completely new to me.
Well, maybe it's not so new to me because it reminds me of
something I did recently.
I have this Document object
that contains some data structures. Let's call those,
Struct1 and Struct2. These structures need to be loaded from
some database somewhere. For the sake of simplicity, let's
forget how the datasources are identified. What is important
is that the data structures be completely independent from
these data sources, mainly because we could want the data in
an SQL database, in XML files, or whatever. This is why I
use Data Loader Objects.
Here is how it works when the Document object needs to be
loaded:
The data structures are contained in an
InstanceCollection object. This instance collection
is put into a new instance collection, under the ID
Targets. The loaders then get created in this new
instance collection, based on a configuration file. The
loaders are created using a
Provider pattern
(I just call it the
AbstractFactory pattern).
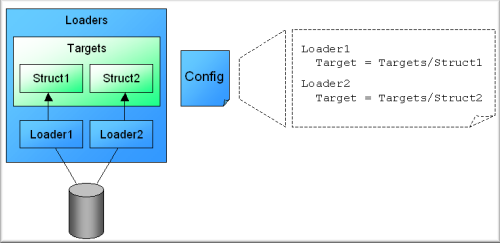
The loaders are automagically connected to their respective data structure with property setters. As the following configuration file states, the Loader1.Target property points to Struct1 in Targets ("Targets/Struct1").

Once this is set up, the loaders get executed and fill their respective data structure with data.
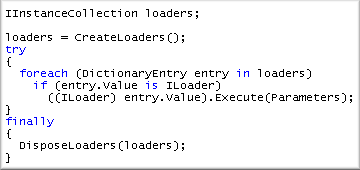
With this solution, the data structures are isolated from the data sources, all is configured, extensible and customizable.