Archives
-
Saving partial state of an ASP.NET control
Rick Strahl has a created a great control that's specialized in saving other control's state. This enables you to declare what properties you really care about, which is a great improvement over ViewState and even ControlState.
There could certainly be a few improvements, but check it out:
http://west-wind.com/weblog/posts/3988.aspx
UPDATE: Rick did actually improve his control based on the feedback he got and now it looks perfect:
http://west-wind.com/weblog/posts/4094.aspx -
Atlas December available; Event bubbling in Atlas
You can download the December release of Atlas from this URL:
-
Man literally dives from sky
I have to admit I didn't know that.
In 1960, before Gagarin, Joe Kittinger reached the boundary between Earth and space using a balloon. He reached the incredible altitude of 31300 meters, 3.5 times the height of Mount Everest. It's not technically space (if a ballon can sustain itself, it means that there still is enough atmosphere for it to float) but it's admittedly a fuzzy limit.
That's fascinating in itself, but wait... Once he got there, he did the most amazing thing: he jumped. He... jumped... With a movie camera. Having jumped from a much more modest altitude, I can only begin to imagine the life-altering experience it must have been for him. Amazingly, we have images of his incredible dive.
That day, Joe Kittinger, at the peril of his life, advanced the whole of the human kind on its way into space, and broke four records: highest balloon ascent, highest parachute jump, longest freefall and fastest speed by a man through the atmosphere at a whopping 982 km/h.
Watch the video here: Skydiving from the edge of the world
Seen on Nobel Intent. -
Making callbacks (and Atlas) synchronous, or how to shoot yourself in the foot
I've explained before why XmlHttpRequest should always be used asynchronously. In a nutshell, JavaScript is not multi-threaded, so the only way to keep your application and browser reasonably responsive is to use some kind of asynchronous pattern. This way, the multitasking is left to the hosting browser and the JavaScript developer can enjoy a relatively easier programming environment where he only needs to care about events and not about summoning threads and managing locks.
-
Another Atlas keyboard behavior?
I wrote this keyboard behavior a while ago and I just realized that Wilco published something very similar long before me. Oh well, just use the one you like best...
-
Got me a 360 this morning
Well, it seems like this second XBOX 360 shipment has finally arrived. Thanks to a tipster whose identity I shall not reveal (but absolutely no MS insider info involved), I was this morning a little before 9AM (one hour before the gates open) at the Costco in Bellingham. We were second in line with my friend David. The line was no more than 25 people when the gates opened, and they had dozens of 360s ready to grasp. Rumor has it they had 144 in Bellingham and about as many in Tumwater.
-
Find me on the new Windows Live Local
I think this is pretty neat (click on the bird's eye icon, that's the really awesome one): This is where I work
-
Date is a reference type in JavaScript
If you try this:
-
How to use enumerations in Profile?
If you've tried to put an enum type into the ASP.NET Profile, maybe you've noticed that there's a small caveat with specifying its default value. To specify the default value, you need to use the serialized value, using the same serialization the profile is going to use for this property. For non-string types, the default serializer is XML. So if you add this to your profile section:
-
Google Sitemaps for ASP.NET 2.0
Google has a little-known feature that enables web site authors to tell the search engine about the structure of their site. ASP.NET also has a way of representing the structure of the site in a map. ASP.NET SiteMaps can be exposed on the site using a Menu, TreeView or SiteMapPath control, but there is no built-in feature that exposes this information in the format that Google understands.
-
Why no synchronous call support in Atlas?
_keyDownHandler = Function.createDelegate(this, this.onKeyDown);
Here, I'm setting the private variable _keyDownHandler (a private variable is a variable declared inside the body of a function/class) to point to the onKeyDown class method. When the delegate is called, it will run within the context of the particular instance that created it and will have access to all its instance properties and methods. Hence, there is no need for global variables. createCallback similarly enables you to create a reference to a function that will remember the arbitrary context object you passed it at creation-time when it is finally called.
If you need to know the result of the call before allowing the user to continue, you shouldn't block the whole browser. What you should do is disable the pieces of UI that should remain untouched while the call is going on (which means other parts of your app can continue to run in the meantime) and re-enable them when the call completes. You can see an example of how to do this declaratively in this blog post:
http://weblogs.asp.net/bleroy/archive/2005/09/20/425698.aspx
Asynchronous calls actually become very natural and transparent in a declarative and event-driven environment such as Atlas is providing.
You may think asynchronous calls are more difficult, but unfortunately until the browsers become multitasking scripting environments (which is not something likely to happen in the foreseeable future imho), they are the only way to create a responsive client web application. -
ASP.NET Alerts: how to display message boxes from server-side code?
One of the most common mistakes beginner ASP.NET developers make is to call MsgBox.Show from their ASP.NET server-side code. It is a mistake because this code runs server-side and will just display the message box on the server where it's not going to be very useful. Well, in version 2.0, it will actually throw an exception.
-
How to make a Control that's also a HttpHandler?
In the Photo Album Handler, one of our goals is to have everything in a single file for easy deployment (we still need an additional separate dll in version 2.1 but we're getting there). I also wanted the handler to be able to act like a Control so that it can be integrated in an existing site. Even when used in control mode, the handler part is still necessary to serve the thumbnail and preview versions of the images. We also want to enable the handler just by dropping it into the image directory without having to modify or create a web.config file, which forces us to use a .ashx file.
-
Photo Album handler 2.0
Last night, I uploaded the source code and release package for version 2.0 of the photo handler. I'll post more about the details of this new version in the next few days, but I can tell you that most of it has been rewritten, and it can now be used as a standalone application or as a control. What's more, the control is fully templatable, so if you don't like the default rendering, you can take it over and create your own. I've included a template example that reproduces the default rendering, which should give a good starting point.
Download the handler from here:
http://www.codeplex.com/PhotoHandler -
No Xbox for you! Next!
Well, if you have not pre-ordered six months ago and weren't ready to spend a good part of yesterday and last night freezing in front of Best Buy, your chances of scoring an Xbox 360 were near zero. So if you're like me, you just made fun of the guys waiting during this wet and cold night and just resigned to go home and wait for the next shipments.
-
A master page is not a singleton
Here's a misconception I see a lot on the forums lately. There is this idea that controls on a master page should always keep their state across content pages that use it.
When you navigate away from a page (i.e. when you click a link), you go to another page, with another instance of the controls on it, so of course the new controls on the new page have no way of knowing about the state of the controls on the other page.
Having a master page does *not* mean that all the controls on the master page have a unique instance that would be shared by all pages that use this master page. The master page is nothing more than a template, it's not any kind of singleton.
So the only way you can maintain the state across different pages (whether you use a master or not) is by storing it in Session and using that information when a new page is loaded. This can have severe performance drawbacks as you store state for each user but is more or less what WebParts do with their personalization data...
Another approach is to consider that if you need to maintain state across all those pages, maybe they are the same and you need to move from a many-page model to a single-page model.
Please note that the navigation controls (a.k.a. Menu, TreeView, SiteMapPath) will automatically select the current node in the site map according to the URL you're on, giving a minimum version of this application-level state management some were expecting from master pages. -
Virtual Places: An amazing Atlas application
If you want to check out what a real-world complex Atlas application would look like, Nikhil put together an amazing Atlas app around Virtual Earth and a few other web services such as Flickr and Amazon.
-
.NET 2.0 was launched this morning. Visual Studio Express free for a year!
After years of hard work, version 2.0 of the .NET framework was launched this morning. This is a major event and something I think we're all proud of. We also launched Visual Studio 2005 (including Visual Web Developer Express), Sql Server 2005 (check out the free Express version) and BizTalk 2006.
-
Atlas client-side Class Browser
This is probably one of the most useful resources on Atlas while there's no complete documentation on the client-side Base Class Library:
-
Using a Virtual Earth Map as the details view in Atlas
Wilco has a brilliant example of a master-details scenario where the details are actually a Virtual Earth map. He also has a live demo of that scenario. Enjoy.
-
How to set the size of asp:menu images?
<StaticMenuItemStyle CssClass="menuitem" />
<DynamicMenuItemStyle CssClass="menuitem" />
Then, in your CSS, add the menu item class and another one that will target all images within an element that has this class and set the image size there: -
This time, I'll show you how to dramatically reduce your productivity
At least for a few hours...
Click here
Warning: this needs Shockwave.
I solved all 40 puzzles. Good luck with that. -
Why is bubble-wrap popping so good?
I don't know, but... enjoy:
-
Security guidance documents for ASP.NET 2.0
New documents are available on MSDN to guide you through best security practices in ASP.NET 2.0:
-
How to write a read/write master details page with Atlas?
Atlas has been unveiled, Whidbey is in Release Candidate, so it's time to update the title of this blog and start writing some sample code for Atlas. I'll continue to write articles on ASP.NET 2.0 as ideas come, but there'll definitely be a lot of Atlas stuff on the blog from now on.
The first sample is going to be a read/write master-details scenario. I'm going to use only client controls in this sample, so that you can get a good understanding of what's really going on. Maybe later I'll post a version that uses server controls which may be a little shorter but will otherwise be very similar.
I'll assume here you have a web-site that's already set-up with the Atlas binaries and script libraries. If that's not the case, please download the bits from http://atlas.asp.net.
The first thing we need to do is write some HTML. This is usually done by a web designer. The code we're going to write in this step is XHTML and CSS, so your designer does not need to know about Atlas or ASP.NET to write it. It means that it can be prepared in any web-design tool, be it DreamWeaver, FrontPage, Visual Studio or Notepad. It also means that you have complete freedom over the rendering of your page, the controls won't decide their layout for you, you decide.
We need a div where the master and details views are going to be rendered, we need a few buttons, and we need a template for each view. Here's the HTML a web designer may hand you over:
<div id="detailsView"></div>
<input type="button" id="previousButton" value="<" title="Go to previous row" />
<span id="rowIndexLabel"></span>
<input id="nextButton" type="button" value=">" title="Go to next row" />
|
<input type="button" id="addButton" value="*" title="Create a new row" />
<input type="button" id="delButton" value="X" title="Delete the current row" />
|
<input type="button" id="saveButton" value="Save" title="Save all pending changes" />
<input type="button" id="refreshButton" value="Refresh" title="Discard pending changes and get the latest data from the server" />
<br /><br />
<div id="masterView"></div>
<div id="masterTemplate">
<fieldset id="masterItemTemplate"><legend>Row <span id="masterIndex"></span>:</legend>
<b><span id="masterName"></span></b><br />
<span id="masterDescription"></span><br />
</fieldset><br/>
</div>
<div id="detailsTemplate">
Name: <input id="nameField" size="30" /><br />
Description:<br />
<textarea id="descriptionField" rows="4" cols="40"></textarea><br />
</div>
I'm not setting any styles here, but just know that there's nothing special about it, just use CSS classes as if you were writing plain old XHTML. Here's the same code as it renders in the browser unmodified (I just copied and pasted the code into the page to get live rendering):
| |
Name:
Description:
We're going to do only one change to this code, which is to enclose the templates in a hidden div so that they don't appear on the page when we first load it. That's just a <div style="visibility:hidden;display:none"> around the two templates.
Now that's done, we're going to write the Atlas code that will bring this HTML to life by giving it behavior. For the Atlas code to work, you'll need the following script references on top of your page (inside the head is a good place):
<atlas:Script runat="server" Path="~/ScriptLibrary/AtlasCompat.js" Browser="Mozilla" />
<atlas:Script runat="server" Path="~/ScriptLibrary/AtlasCompat.js" Browser="Firefox" />
<atlas:Script runat="server" Path="~/ScriptLibrary/AtlasCompat.js" Browser="AppleMAC-Safari" />
<atlas:Script runat="server" Path="~/ScriptLibrary/AtlasCore.js" />
<atlas:Script runat="server" Path="~/ScriptLibrary/AtlasCompat2.js" Browser="AppleMAC-Safari" />
This will eventually become lighter when the ScriptManager server control will be able to output that for you.
The Atlas markup itself will live in a block such as this one, which you can place anywhere on the page (some people will like it at the bottom of the page, some will put it in the head, and there is even a server-side build provider that will enable you to put it into a completely separated .script file):
<script type="text/xml-script">
<page xmlns:script="http://schemas.microsoft.com/xml-script/2005">
<references>
<add src="../ScriptLibrary/AtlasUI.js" />
<add src="../ScriptLibrary/AtlasControls.js" />
</references>
<components>
</components>
</page>
</script>
First thing to do is to bring some data from the server. We're going to use a client-side data source that will take its data from a data service. A data service is a special kind of web service that's specialized in CRUD (Create Retrieve Update Delete) data access. It's very easy to write, you just need the four CRUD methods in a pretty free form. The parameters can be one complex type or several parameters for each of the complex type's properties, it doesn't matter as the base class should be able to figure it out using reflection. You just need to mark the methods with data object attributes:
public class SampleDataService : DataService {
static List<SampleRow> _data;
static int _nextId;
static object _dataLock = new object();
private static List<SampleRow> Data {
get {
if (_data == null) {
lock (_dataLock) {
if (_data == null) {
_data = new List<SampleRow>();
_data.Add(new SampleRow(0, "ListView", "A control to display data using templates."));
_data.Add(new SampleRow(1, "Window", "A control to display dialogs."));
_data.Add(new SampleRow(2, "Weather", "A control to display local weather."));
_nextId = 3;
}
}
}
return _data;
}
}
[DataObjectMethod(DataObjectMethodType.Delete)]
public void DeleteRow(int id) {
foreach (SampleRow row in _data) {
if (row.Id == id) {
lock (_dataLock) {
_data.Remove(row);
}
break;
}
}
}
[DataObjectMethod(DataObjectMethodType.Select)]
public SampleRow[] SelectRows() {
return SampleDataService.Data.ToArray();
}
[DataObjectMethod(DataObjectMethodType.Insert)]
public SampleRow InsertRow(string name, string description) {
SampleRow newRow;
lock (_dataLock) {
newRow = new SampleRow(_nextId++, name, description);
_data.Add(newRow);
}
return newRow;
}
[DataObjectMethod(DataObjectMethodType.Update)]
public void UpdateRow(SampleRow updateRow) {
foreach (SampleRow row in _data) {
if (row.Id == updateRow.Id) {
row.Name =updateRow.Name;
row.Description = updateRow.Description;
break;
}
}
}
}
That code should be placed in an .asmx file on the server, for example DataService.asmx. Here, we're using static data to make the sample easy to set up and because database access is not the focus of this sample. Of course, in a real application, the data would come from a real database. The data that the service handles also needs to be marked with a few attributes:
public class SampleRow {
private string _name;
private string _description;
private int _id;
[DataObjectField(true, true)]
public int Id {
get { return _id; }
set { _id = value; }
}
[DataObjectField(false)]
[DefaultValue("New row")]
public string Name {
get { return _name; }
set { _name = value; }
}
[DataObjectField(false)]
[DefaultValue("")]
public string Description {
get { return _description; }
set { _description = value; }
}
public SampleRow() {
_id = -1;
}
public SampleRow(int id, string name, string description) {
_id = id;
_name = name;
_description = description;
}
}
If you want, you may also implement a data service by overriding GetDataImplementation and SaveDataImplementation. It may be more complex to write, but you'll get rid of the reflection and won't need to attribute the data class.
That's it for the server code we're going to write. Now let's write the client-side data access. For that, let's just add the following line between <components> and </components>:
<dataSource id="dataSource" serviceURL="DataService.asmx"/>
That's it, the dataSource just needs the address of the data service. It is a very important component because in Atlas, UI components will not communicate directly with the server. They will communicate with data sources that will centralize the changes and send them back to the server as needed and as a bulk update.
Now we need to connect a ListView (which will be our master control) and an ItemView (which will be our details view) to the data on the one hand and to the HTML markup on the other hand:
<listView id="masterRepeater" targetElement="masterView" itemTemplateParentElementId="masterTemplate">
<bindings>
<binding dataContext="dataSource" dataPath="data" property="data"/>
</bindings>
<layoutTemplate>
<template layoutElement="masterTemplate"/>
</layoutTemplate>
<itemTemplate>
<template layoutElement="masterItemTemplate">
<label targetElement="masterIndex">
<bindings>
<binding dataPath="_index" transform="Add" property="text"/>
</bindings>
</label>
<label targetElement="masterName">
<bindings>
<binding dataPath="Name" property="text"/>
</bindings>
</label>
<label targetElement="masterDescription">
<bindings>
<binding dataPath="Description" property="text"/>
</bindings>
</label>
</template>
</itemTemplate>
</listView>
A few things to explain here. First, the listView control points to the target element where the rendering will take place, and to the element in the template that will contain the item template. The template for the ListView is semantically complete, meaning that there is only one template that represents header, footer and item, and then the ListView only points to the different parts. That makes the whole thing a lot easier to design and makes sure the markup is valid at all times.
Then, we have a binding that ties the data property of the ListView to the data property of the DataSource. This ensures that any time the data changes, the list can rerender to accomodate the change.
Then we have the declaration of the different parts of the template. It is particularly interesting to look at the item template. Here, we're attaching Atlas controls to the HTML elements inside the template markup. Namely, we have three labels that are each attached to a span and bind their text property to a column of the current data row.
The details view follows the same pattern. It just has textboxes instead of labels and has bidirectional bindings. It also features an additional binding that will disable the UI if the data source is not ready (which happens when it is in the process of sending changes to the server or refreshing).
<itemView targetElement="detailsView" propertyChanged="onChange">
<bindings>
<binding dataContext="dataSource" dataPath="data" property="data"/>
<binding dataContext="dataSource" dataPath="isReady" property="enabled"/>
</bindings>
<itemTemplate>
<template layoutElement="detailsTemplate">
<textBox targetElement="nameField">
<bindings>
<binding dataPath="Name" property="text" direction="InOut"/>
</bindings>
</textBox>
<textBox targetElement="descriptionField">
<bindings>
<binding dataPath="Description" property="text" direction="InOut"/>
</bindings>
</textBox>
</template>
</itemTemplate>
</itemView>
The last thing we need to do is to wire up the buttons to make the UI fully interactive:
<button targetElement="previousButton">
<bindings>
<binding dataContext="detailsView" dataPath="canMovePrevious" property="enabled"/>
</bindings>
<click>
<invokeMethod target="detailsView" method="movePrevious" />
</click>
</button>
<label targetElement="rowIndexLabel">
<bindings>
<binding dataContext="detailsView" dataPath="dataIndex" property="text" transform="Add" />
</bindings>
</label>
<button targetElement="nextButton">
<bindings>
<binding dataContext="detailsView" dataPath="canMoveNext" property="enabled"/>
</bindings>
<click>
<invokeMethod target="detailsView" method="moveNext" />
</click>
</button>
<button targetElement="addButton">
<bindings>
<binding dataContext="dataSource" dataPath="isReady" property="enabled"/>
</bindings>
<click>
<invokeMethod target="detailsView" method="addItem" />
</click>
</button>
<button targetElement="delButton">
<bindings>
<binding dataContext="dataSource" dataPath="isReady" property="enabled"/>
</bindings>
<click>
<invokeMethod target="detailsView" method="deleteCurrentItem" />
</click>
</button>
<button targetElement="saveButton">
<bindings>
<binding dataContext="dataSource" dataPath="isDirtyAndReady" property="enabled"/>
</bindings>
<click>
<invokeMethod target="dataSource" method="update" />
</click>
</button>
<button targetElement="refreshButton">
<bindings>
<binding dataContext="dataSource" dataPath="isReady" property="enabled"/>
</bindings>
<click>
<invokeMethod target="dataSource" method="select" />
</click>
</button>
On each button, we have a binding that will disable it as appropriate, and there is a click handler that will invoke the relevant method. For the previous, next, add and delete buttons, it's just a matter of calling the right method on the details view, and for the save and refresh buttons, we're just calling update or select on the data source itself.
Thanks to bindings and change notifications, we are actually done, and all changes to the data will be centralized on the data source which is the only thing that communicates with the server. Everything propagates using these simple declarative bindings and we got to make a complete master/details page without writing a single line of client script. -
Excellent article on the features of the future VB 9
I just read this article on the features of the future VB 9 language. The features I like the most are Linq (for both SQL and XML) and extensions. I know extensions are going to be criticized by OOP fundamentalists, but it is oh so useful and will solve so many problems purists should really just relax and enjoy. Actually, if you take a close look to Linq, you may notice that it is made possible by extensions: the where, order by and other operators are really just extensions on enumerable types from what I understand. This, with some magic reflection and database interfacing, gives you the ability to query any object graph.
-
Atlas revealed at PDC
Atlas was revealed this morning at the PDC keynote. It was a very fast-paced demonstration by Scott Guthrie which started with the client-side querying of an Indigo service (which itself was exposing data extracted by C# 3.0's very cool query language integration) and ended with an impressive application that displays results in a templated ListView from which you can drag & drop items into a DetailsView (it's worth noting that Atlas drags and drops data and not just HTML) and then displays data on a Virtual Earth powered satellite picture of the area, complete with pinpoints, panning and zooming. And here's the best part: all that runs client-side, and it truly is cross-browser...
-
A simple ASP.NET photo album
In June, Dmitry posted a very simple photo album on his blog. I immediately liked it because it's both easy to set-up (just drop the ashx file into your web site's photo directory) and to manage (no need to upload images one by one using a clumsy web upload field, just upload new photos using ftp or the file system). It's also nice to browse. Sure, there are no fancy ratings or comments features, you can't add titles or descriptions, but frankly, I didn't need all these features.
-
Why don't callbacks send the latest values of the form fields?
I've been getting this question a lot lately. Yes, it will stay that way and yes, it will confuse people.
The reason for that is very complex but I'll try to explain briefly.
First, you need to know that it's impossible to update the viewstate during a callback because contrary to postbacks, there can be multiple simultaneous callbacks which could cause an inconsistency or concurrency issue in the state.
Now, if we sent the latest version of the form, because of that, change events would fire on every single callback, each of which could have side-effects.
But there's worse. Some complex callback controls, like TreeView, need to manage their own client-side state (like the list of nodes that have been expanded client-side or using populate on demand). This client-side, control-specific state is kept in a hidden field that's used on the next postback to replay the changes and update the viewstate. Rehydrating the state from ViewState is cheap, replaying changes is not because that may involve multiple calls to a database.
Again, if we sent the latest version of the form during a callback and if we want the state of the page to be consistent, the tree would replay all the changes that have been done client-side since the last postback, on every callback. That would result in an unacceptable performance drop.
And you'll have the exact same problem with any complex data control that needs to maintain client-side state about the changes that occurred since the last postback. The ViewState can't be used for this state because it can't be updated during callbacks, so to maintain a consistent state, you need to replay the changes during the next postback, but not during each callback because the changes could add up pretty fast, growing the total number of operations to replay as an o(n^2) function of the number of callbacks.
There are more intricate details involved but this is the big picture.
The good news is that the advice here is simple: you need to package any form fields you need to use to determine your callback response into your callback parameter. To help you package multiple, strongly-typed pieces of information into the single string callback parameter, check out my RefreshPanel library.
More details about that here. -
How to output HTML at the end of a WebForm from code?
With all this client-side activity that's going on lately, there's one particular need I've seen arise repeatedly. It is often useful to output contents at the end of a page (or at the end of the form, at least). The reasons why you would want to render contents not in the current position in the stream of the rendering page but at the end are diverse. One reason could be that you want only one instance of that contents on the page no matter how many controls require it. Another could be that you want controls to be able to add to a big chunk of data that you want to output in one piece at the end (that's a need we had in Atlas).
-
How to put a DIV over a SELECT in IE6?
Everybody who tried to implement an HTML menu knows it: in Internet Explorer 6, there are some elements like SELECT that always appear in front of all other elements no matter what z-index you apply to them. Other elements that present the same problem are ActiveX controls (including Flash movies), OBJECT tags, plug-ins and iFrames. That's because these elements are implemented as windows whereas other elements are just drawn on the existing background window.
-
How to deal with the July CTP ICallbackEventHandler breaking change?
As some have already noticed, there's been a change in the ICallbackEventHandler interface signature. The old interface had only one method, RaiseCallbackEvent, that took a single string parameter, and returned a single string response.
-
Brock Allen about ASP.NET callbacks and Ajax
Brock Allen wrote an interesting post on his blog comparing Ajax and the callback feature of ASP.NET. Most of the concerns he has about ASP.NET callbacks are addressed in my Fun with callbacks series and/or in the forthcoming Atlas project.
-
Finished Jade Empire
Wow, what a great game! I just finished Jade Empire in "evil mode". I'm very likely to do it again in "boy scout" mode. The immersion and richness of the universe are just amazing. The only thing I disliked is the tendancy Bioware has to explain to us that the evil path is somewhat as honorable as the virtuous one. I enjoy playing an evil character (I know the subtle difference between game and reality as almost every other gamer on the planet), but don't try to tell me that he's not evil. Some of the things they make you do in this mode are actually quite disturbing. I'm still waiting for the (good) game that will let you play a Dr. Evil-like character: evil, but in a funny way. Yes, Dungeon Keeper did that in a way, but that was a long time ago.
-
Some thoughts about server callbacks and Ajax.NET
Looking back at all the feedback I got from my ongoing Fun with callbacks series, I understood a few things about what most people expect from an Ajax-like framework.
-
Atlas project announced
Scott Guthrie announced the Atlas project in a recent blog post. The Atlas project aims at considerably simplifying and enriching the client script development experience. It includes but is not limited to AJAX/callbacks and cross-browser client-side declarative binding of elements and behaviors. One of our goals is to leverage the experience of client-side programming that exists inside Microsoft (see Outlook Web Access, MSN Spaces, MSN Virtual Earth, etc.) and give easy access to that technology to developers.
-
Fun with callbacks Part 4: what about postback events?
One thing that's certainly not that clear enough about callbacks is what happens with regular postback events and control state. During a callback, we reconstruct the state of the page as it was during the last postback. The reason we are doing this is that we want the logic in the callback method to be able to access the rest of the page with controls in the right state.
-
Die, marker! Die!
Did you ever notice how people can't ever throw a marker away? How many times have you seen this scene?
-
Fun with callbacks Part 3: Strongly-typed callbacks
I got a lot of feedback after the first two posts in this series pointing out the need for a more strongly-typed communication than just strings. Several comments also pointed me to the great AJAX.NET library. I like the AJAX.NET approach because it looks very much like Web Service proxying. It's a real accomplishment as it succeeds in reproducing a reasonable part of the .NET type system in JavaScript. On the downside, it's really oriented at client-side script writing, and it suffers from the same drawbacks as Web Service proxying, namely that it gives the illusion of a local object whereas a service-oriented approach should be taken, trying to mutualize the communications with the server as much as possible. At least, the asynchronousness of callbacks makes it more obvious that you're dealing with networked resources.
-
Unable to generate code for a value of type... Can you tell what's wrong?
I recently got this error when trying to run a WebControl that had a property that is a collection of objects that have a property that uses a type converter to convert its string persistence format to its real type (still following me?). Here's what the persisted format looks like:
-
Fun with callbacks, Part 2: The RefreshPanel
ASP.NET 2.0 makes it easier to develop Web applications that do out-of band calls, as we saw in the previous post. But one thing I noticed is that most applications will really just want to refresh and update some part of the page without touching the rest of it. In this case, the second client-side script, the one that receives the results from the callback and updates the page is always the same, something like element.innerHTML = response;.
-
Fun with callbacks Part 1: What's in the ASP.NET box?
There's a lot of buzz currently around Web out-of-band calls, aka XmlHttp, aka AJAX (the guy who coined this term must be some kind of marketing genius for imposing a new acronym for a technique that's been used for many years). It seems like the world is suddenly discovering that it is possible to get an update to a Web page from the server without posting back. Many techniques have been used for that purpose: Java applets (ASP classic was using this technique in Remote Scripting more than eight years ago), hidden frames and iframes, dynamically reloaded <script> elements and even reloading transparent images using cookies as the information transportation vessel. But the technique really became more than just a clever hack when Microsoft introduced the XmlHttpRequest object in Internet Explorer 5. The goal was to populate Xml data islands without sending back the whole page, hence the Xml prefix, but today it doesn't have much to do with Xml any more as the data that's transferred is most of the time not Xml. Client-side Xml never really happened.
-
Open() late, Close() early
One of the most common mistakes Web developers do is try to be smart about database connection management. Connections are expensive resources, and it seems like it would make a lot of sense to store an open connection, say, in a Session or Application variable, for later re-use, so that next time you need it, it's already there and ready to use.
-
No April Fool's jokes this year :(
Yesterday, all bloggers here at Microsoft received a memo from Steve Ballmer asking us not to do any April Fool's jokes on our blogs. Here's a citation from this memo:"This kind of joke can affect the image of the company negatively and spread false information. We'll have to be very strict on enforcing this policy and any employee who chooses not to obey this simple rule will have to face sanctions up to and including termination of their employment."That's really sad, I had a few good ones that I had been preparing. Oh well.Update: of course, this was written on April 1st, so none of this is true. SteveB never wrote such a memo. -
What's the difference between generic type parameters and parameters of type Type?
In other words, what's the difference between:
-
ObjectHierarchicalDataSource sample code
<my:ObjectHierarchicalDataSource runat=server ID=ObjectInstance1 TypeName="Categories">
<SelectMethods>
<my:SelectMethod TypeName="CatsCategory" Method="GetCats" />
<my:SelectMethod TypeName="Cat" PropertyNames="Color,Gender" />
</SelectMethods>
</my:ObjectHierarchicalDataSource>
<asp:TreeView Runat=Server ID=categoryTree DataSourceID=ObjectInstance1
ExpandDepth=0 PopulateNodesFromClient=true>
<DataBindings>
<asp:TreeNodeBinding TextField="#" ValueField="#" ToolTipField="#" PopulateOnDemand=true />
<asp:TreeNodeBinding DataMember="CatsCategory" TextField="Name" ValueField="Name"
ToolTipField="Name" PopulateOnDemand=true />
<asp:TreeNodeBinding DataMember="Cat" TextField="Name" ValueField="Name"
ToolTipField="Description" PopulateOnDemand=true />
<asp:TreeNodeBinding DataMember="Color" FormatString="Color: {0}" PopulateOnDemand="true"
SelectAction="None" TextField="Name" ValueField="Name" ToolTipField="#" />
<asp:TreeNodeBinding DataMember="Gender" PopulateOnDemand="true" SelectAction="None"
TextField="#" ValueField="#" ToolTipField="#" />
</DataBindings>
</asp:TreeView> -
World safe from mad scientists
After all, we may be safe from the mad scientists at CERN (just kidding: some of these guys are not yet entirely mad) producing low-velocity black holes that could have swallowed the Earth if Hawking radiation just happened not to work after all. Well, the mad scientists at RHIC may have just created black holes (or more correctly objects that act like black holes but may be supersymmetric dual objects to black holes (no, I don't really understand what I'm writing here, just pretending)) and observed them evaporate through Hawking radiation.If this is confirmed, it means three different things:- Black holes have been produced in a laboratory. Scary, but they are very small ones.
- Hawking radiation works
- Superstring effects have been observed
An of course, the Earth is safe from destruction by artificial black holes. So we're back to worrying about nuclear holocaust, climate changes, pollution, strangelets, massive epidemies, ateroids hitting the Earth. Ew, that was a close one.Source:through Julien Ellie. -
How do I reduce this ViewState thing?
ViewState is a hugely useful feature of ASP.NET, but it's easy to misuse. It's also a little difficult to apprehend for ASP.NET beginners as it's working behind the scenes. The only thing you see at first is this huge blob on your page source.If you don't know how ViewState works or what it's for, and even if you do, you should read this MSDN article. In a nutshell, ViewState is a state bag that's maintained from postback to postback. It materializes one of the scopes you can use to maintain state in your application:- Context: local to the request (equivalent in scope to a page property).
- ViewState: local to the page, survives postbacks (but if you open two browsers on the same page, they have separate versions of the ViewState).
- Session: local to the remote user session (if you open two browsers using CTRL+N, they share the same session, but if you open two completely different instances of the browser, they don't), has a finite lifespan (20 minutes idle time by default), does not survive the browser closing. The Session can be shared across servers in a Web Farm.
- Cookies: local to the remote user account, can survive the browser closing, has a finite lifespan.
- Cache: local to the web application, shared by all users, not shared in a farm, expires based on a lifespan or arbitrary dependancies.
- Application: local to the Web application, shared by all users, not shared in a farm, doesn't expire except if the application is recycled.
- Static variables: shared by the whole application domain. Don't use that in a web application. Use Application variables instead (unles you really really know what you're doing).
The way it works is by tracking all changes from the moment TrackViewState is called, which happens normally between Init and Load. This means that any change you make after Init will be persisted to ViewState.So the first thing you can do to reduce the viewstate is to do all initialization work during... yes, Init.The data that you do want to persist across postbacks must be loaded during... you guessed it, Load.The way it persists from postback to postback is by serializing all changes since tracking began into the __VIEWSTATE hidden HTML field. This is the big blob you see in your page. To avoid tampering, it is by default MAC-hashed.There are a few reasons why you could want to completely disable ViewState (which is done by setting EnableViewState to false in the page directive or on any Control):- Your page won't post back: pure contents pages, for example.
- Your page will post back, but the data will be completely different for every postback: a search results page where you handle the pagination logic using lazy loading, for example.
- Your page will post back, but you chose to rebind the data on every postback.
- The control does not handle postback data.
- The control does not persist any data.
- The control rebinds the data on every postback.
The third and sixth ones are particularly interesting because it's a decision you have to make in the context of your particular application. If the bandwidth the ViewState is eating costs you more than querying the database, then disable ViewState. Otherwise, keep it on but don't bloat it unnecessarily (by moving initialization code to Init and keeping persisted data loading in Load).If you choose to requery the data on every postback, consider doing it in Init. This way, you can keep the data out of ViewState and still use the ViewState for other properties: you get finer granularity.Another problem you may hit on ASP.NET 1.1 is that some controls do not like to have their ViewState disabled. DataGrid is one example of a control that more or less ceases to function properly without ViewState. That's why we introduced the concept of ControlState in ASP.NET 2.0. The ControlState is a part of ViewState that can't be disabled. It is used for these very few properties on each control that are absolutely necessary for the control to function. It could be the page number for a pagination control, for example. So in ASP.NET 2.0, you can safely disable ViewState on any of the new controls without them breaking down. GridView, which replaces DataGrid, is one of these controls. -
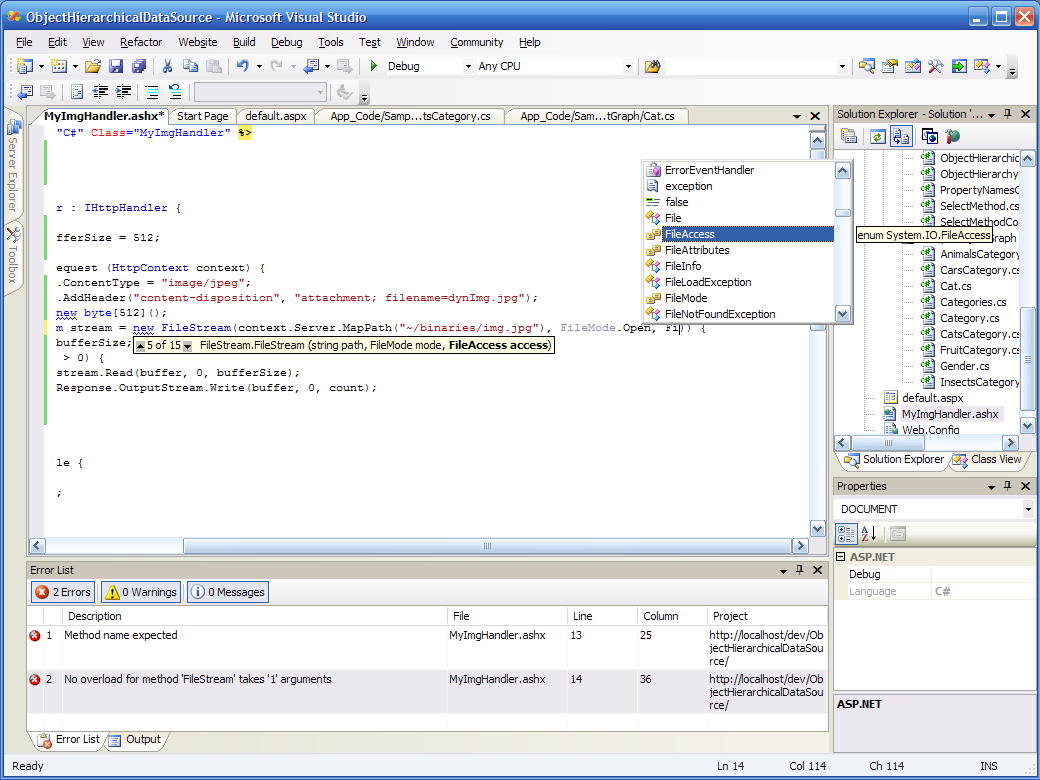
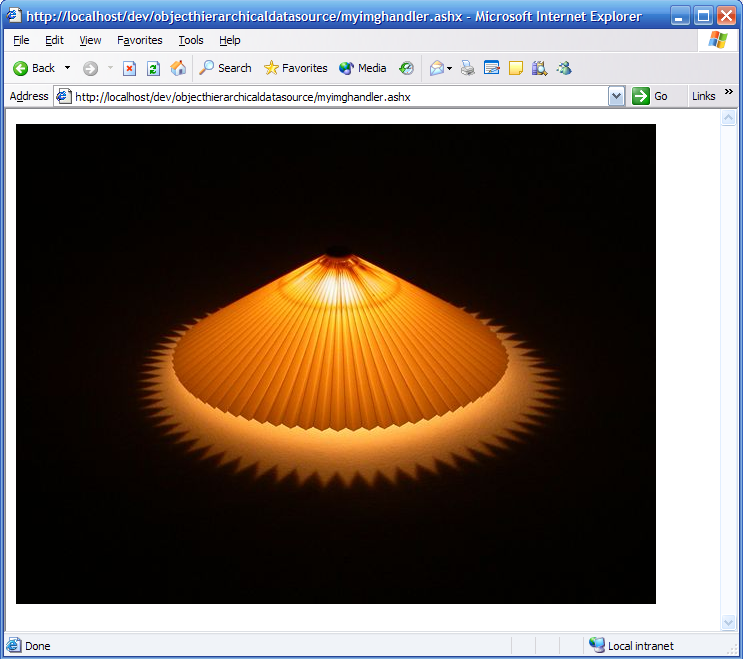
Develop a HttpHandler with full IntelliSense
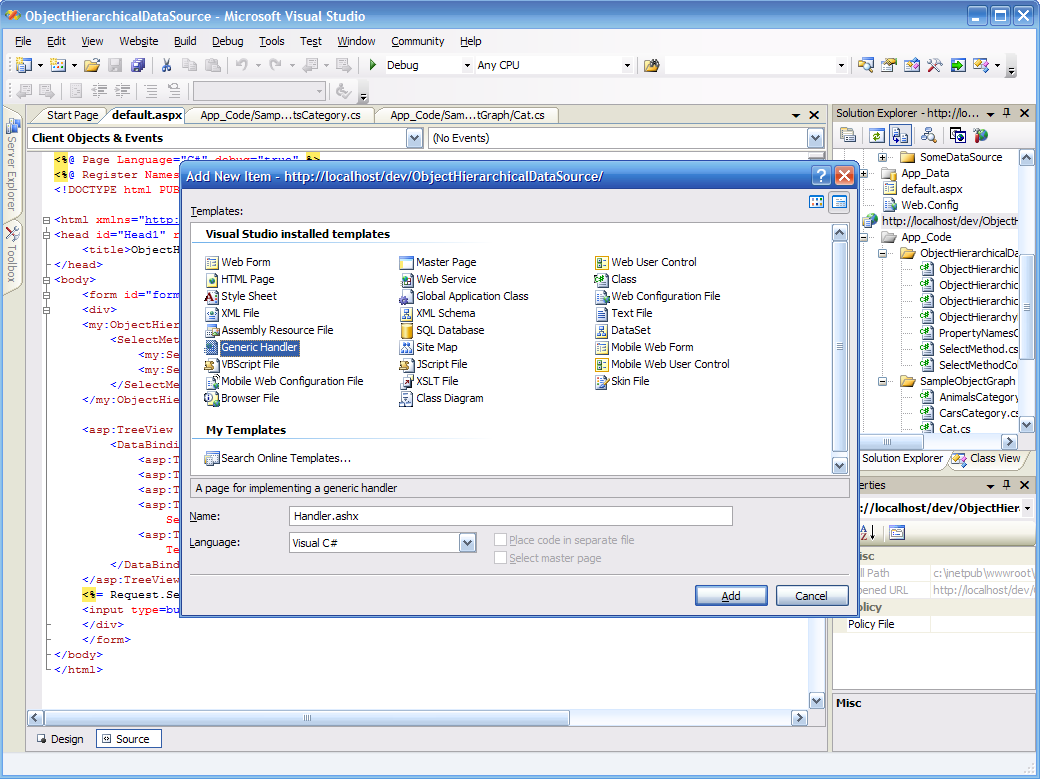
Ashx files have a bad reputation. There is little documentation about them in v1, and no support for them in Visual Studio 2003. With ASP.NET 2.0 and Visual Studio 2005, this changes, and it becomes as easy to develop an ashx file as any other class.But what is an ashx file, you may ask? It's an HttpHandler, a class that handles an http request. An ASP.NET page can be considered a kind of elaborate HttpHandler, for example. There are cases where you won't need all the Page infrastructure, WebControls, events and all that. Let's say that you want to stream a thumbnail image to the client, for example. All you need is a reference to the context (to be able to get some information from the QueryString, send data to the response, etc.). That's no more and no less than what the HttpHandler infrastructure gives you.So when you need raw treatment of a http request, use a handler instead of a page.I've made a few screen copies while developing a very simple handler, so that you can see how easy it becomes to develop an ashx file in Visual Studio 2005 (click on the images to get them at full resolution):
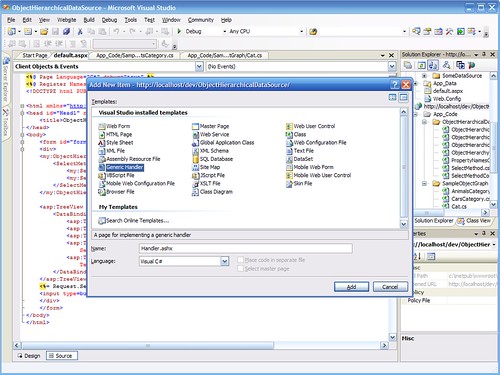 Step 1: Adding a new item to the project. I'm choosing "generic handler", which will create the ashx file with the code structure already there.
Step 1: Adding a new item to the project. I'm choosing "generic handler", which will create the ashx file with the code structure already there.
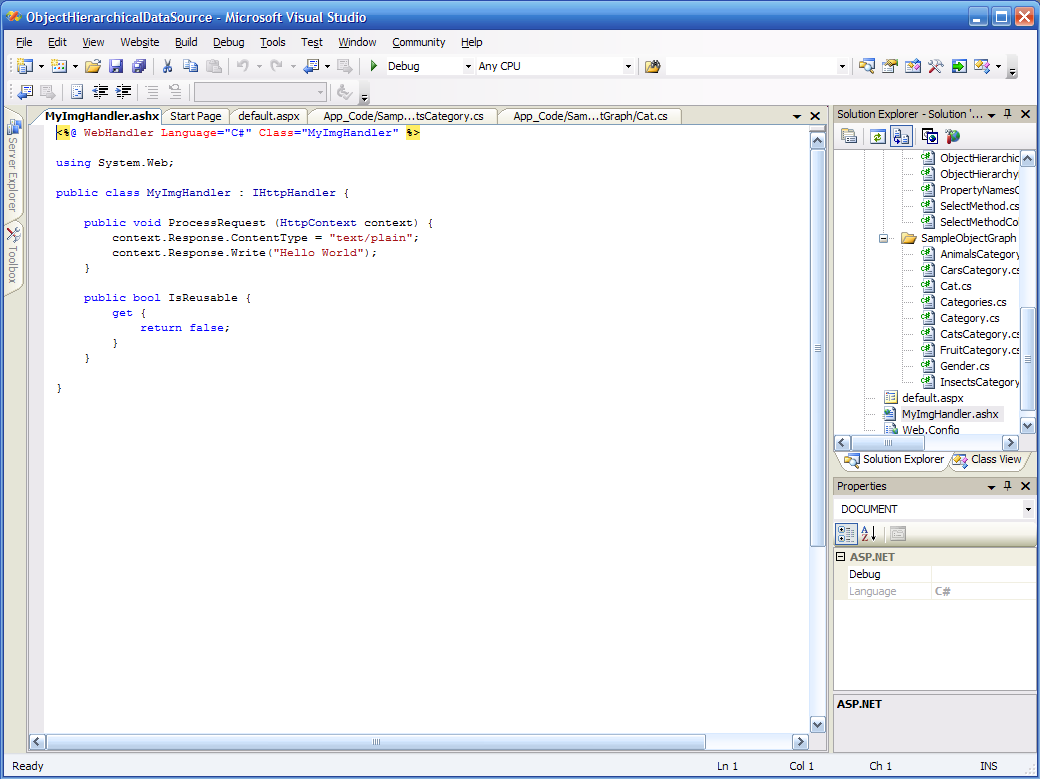
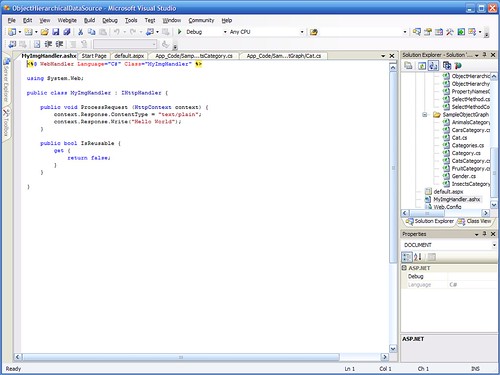 Step 2: This is the code structure that Visual Studio provides. I did not write a single character at this point.
Step 2: This is the code structure that Visual Studio provides. I did not write a single character at this point.
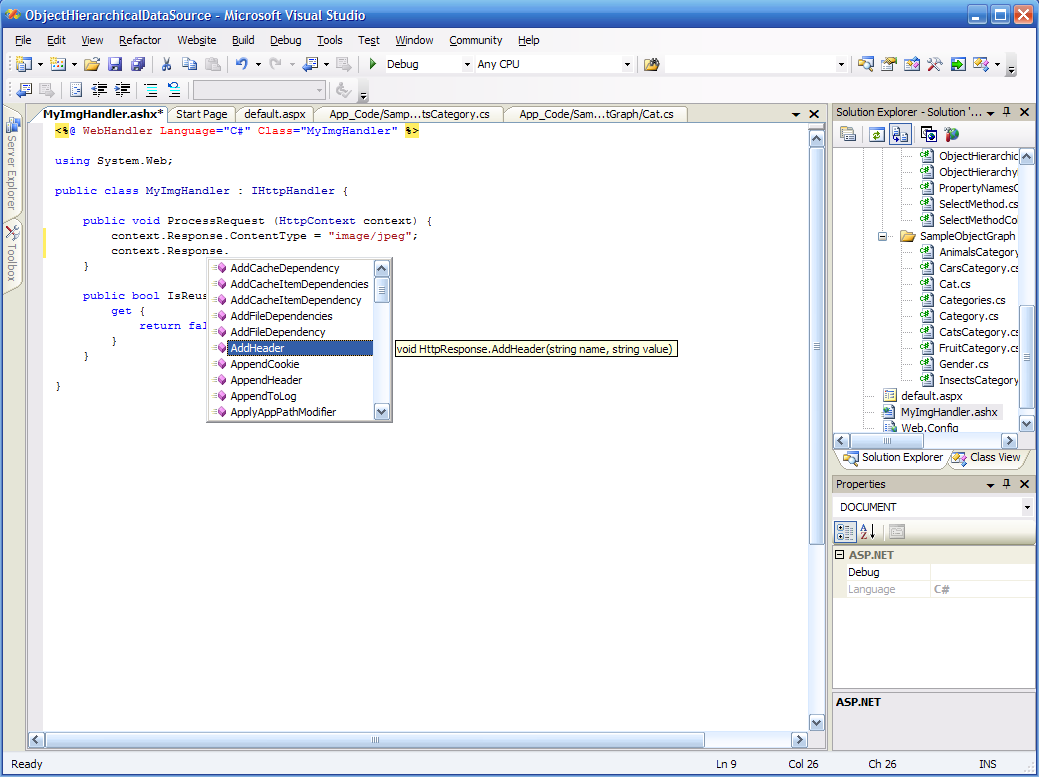
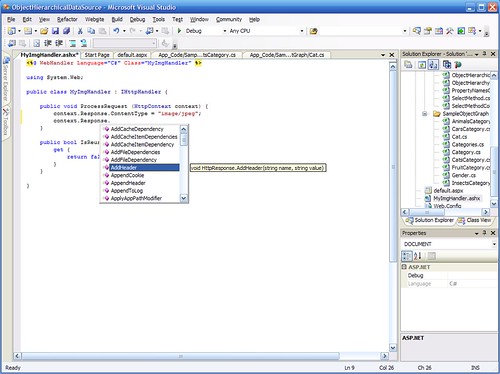 Step 3: I have full IntelliSense and code coloring on my code. Everything works exactly the same as in any other code file.
Step 3: I have full IntelliSense and code coloring on my code. Everything works exactly the same as in any other code file.
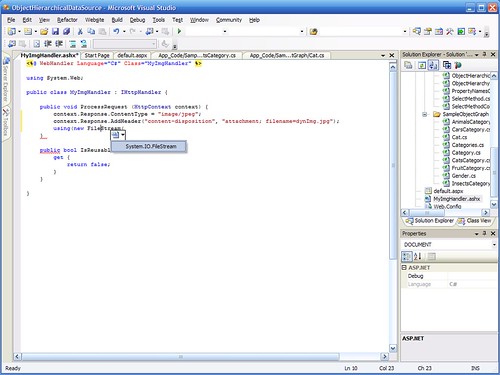 Step 4: I also have access to refactoring, immediate squiggly red lines under my syntax errors, etc.
Step 4: I also have access to refactoring, immediate squiggly red lines under my syntax errors, etc.
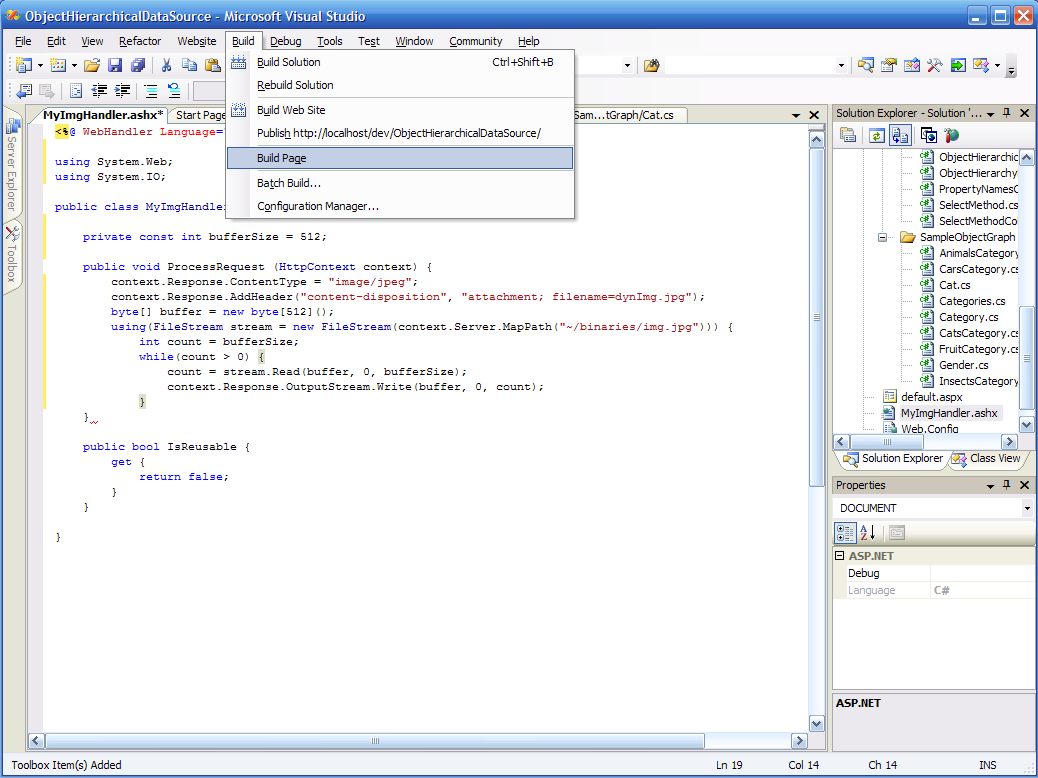
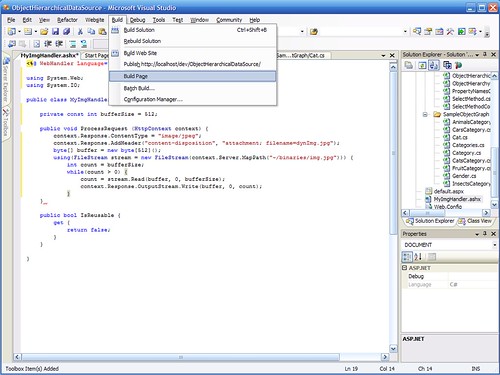 Step 5: I can build the page, the whole web site or the whole solution (or even just save and let the server auto-compile on the first request).
Step 5: I can build the page, the whole web site or the whole solution (or even just save and let the server auto-compile on the first request).
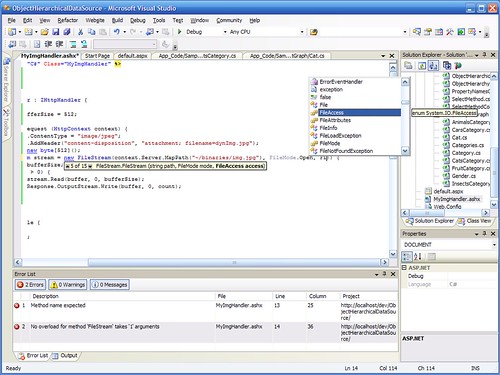 Step 6: I can see build errors (I made stupid errors on purpose here, in real life I know how to initialize an array) and click on them to get to the faulty source code.
Step 6: I can see build errors (I made stupid errors on purpose here, in real life I know how to initialize an array) and click on them to get to the faulty source code.
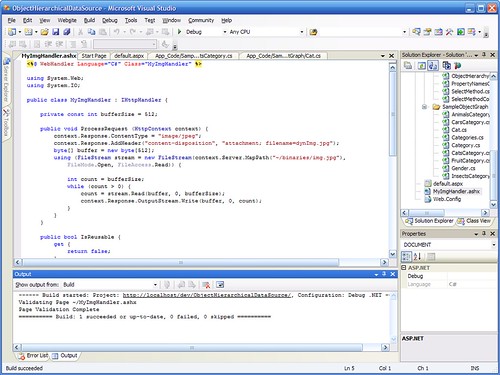 Step 7: I'm almost done. The handler compiles.
Step 7: I'm almost done. The handler compiles.
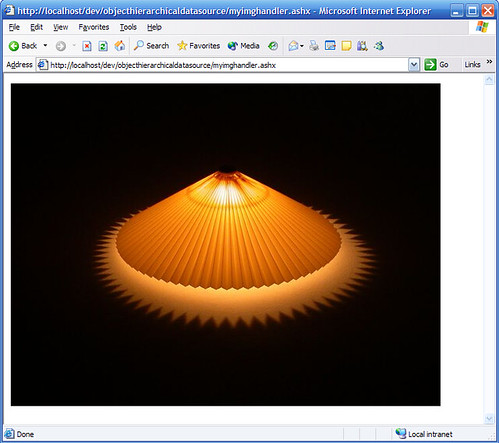 Step 8: And it works perfectly!Update: Scott Hanselman has a great HttpHandler template to get you started.
Step 8: And it works perfectly!Update: Scott Hanselman has a great HttpHandler template to get you started. -
Clean Office automation on the server... at last!
One of the very common requests we see on the ASP.NET forums is how to generate Excel or Word documents on the server? There are currently three approaches to answer this need:- Output HTML or XML and just change the mimetype so that the relevant Office application opens the stream. All Office applications being quite HTML and XML friendly, chances are you'll get a pretty good result while leaving server resources reasonably untapped. But it's hacky to say the least, and what you get is not a real Office document, just some HTML or XML document open in Office. This means that you won't be able to use most of the features of the Office application (like formulas in Excel, which is quite a large drawback). If you're brave, you may generate a proper Office XML format (the keywords here are WordprocessingML and SpreadsheetML), but you may want to fall back on 2:
- Use a third party server library that generates well-formed Office documents. There are quite a few floating around.
GoogleMSN Search is your friend. - Install Office on the server, spawn one of the Office applications and automate it from the server. You shouldn't do this if you can avoid it, as this KB article explains. The problems (apart from licensing) are due to Office applications being built to be desktop applications, not scalable server components. Read the KB article for more details, but in a nutshell, you'll have to deal with singletons, queues, cleanup procedures, etc. and even if you do it relatively cleanly, it will perform poorly. It just does not seem worth the trouble. The Office Web Components are also client-side objects that won't give good results server-side.
Starting with Visual Studio Tools for Office (VSTO) 2005, server-side objects are provided that solve this problem. It's like option 2., only it's done by Microsoft.Check out the article here: -
Brian Goetz on micro-benchmarks
Brian Goetz writes on micro-benchmarks and discourages people from writing any. The first part of the article details why some particular banchmark is flawed, which is only mildly interesting unless you're interested in lock performance in Java (and why wouldn't you be?), but the second part gives excellent advice on performance testing in general.I thought I would give a pointer to his article as I've been guilty of micro-benchmarking myself on this blog more than once. To my defense, I've always said that these gave only a rough idea of performance in a real-life scenario, and that any performance testing should be made in the context of the real application.The problem for us API developers is that our users ask for guidance on when to use this or that particular technique. We can still give some general answers based on reasonable micro-benchmarking and analysis of the IL code in some very simple cases, and that's enough for most users. But nothing will ever replace a good profiler and a lot of experimentation on the real application when it's being used in real-life conditions.Read the article here: -
More on string concatenation performance
This one is kind of obvious when you think about it, but I've seen code like this so many times it's probably worth showing. Strangely enough, I've seen this kind of code in VB most of the time.The reason why people write this kind of code is to construct a SQL query while keeping the source code easily readable by splitting the string across several lines of code. The code looks like this:
string a = "Some string that we want to build";
a += " from several strings for better";
a += " source code readability:";
a += " we don't want a long string on one line.";Notice how the string has the new bit added to itself using concatenation (in VB, you would use &= instead of +=). This is of course not very efficient because real concatenations happen. Here's the IL that this code compiles to:ldstr "Some string that we want to build"stloc.0ldloc.0ldstr " from several strings for better"call string [mscorlib]System.String::Concat(string, string)stloc.0ldloc.0ldstr " source code readability:"call string [mscorlib]System.String::Concat(string, string)stloc.0ldloc.0ldstr " we don't want a long string on one line."call string [mscorlib]System.String::Concat(string, string)It's much more efficient to really split the line without ending it, this way:
string a = "Some string that we want to build"
+ " from several strings for better"
+ " source code readability:"
+ " we don't want a long string on one line.";The IL that this code compiles to is exactly equivalent to what you'd get if you had left the string on one line because the compiler knows that only static strings are concatenated here:ldstr "Some string that we want to build from several str"+ "ings for better source code readability: we don't want a long string on"+ " one line."+ signs here are an artefact of ILDASM for readability, similar to what we're trying to do in our source code, and are not real concatenations: notice how the lines are split at different places when compared to our source. To make it perfectly clear: the + signs here are *not* real. If you read the exe file with a hex editor, you'll see that the string is in one piece. No quotes, no concatenation, nothing.So you get both readability and optimal performance.In VB, of course, you can use the line continuation symbol (underscore: _ ) and the & operator. The compiler will also optimize it to a single string. -
Three common mistakes in JavaScript / EcmaScript
Here are three common mistakes I've seen recently in script files.- Undefined is not null, except that it is.
If you've been writing code in a strongly-typed language recently, you're used to checking the nullity of objects before you use them, like this:
if (SomeObject.foo !== null) {
Well, in JavaScript, something that has not been assigned to is not null, it's undefined. Undefined is different from null when using !== but not when using the weaker != because JavaScript does some implicit casting in this case. Well, anyways, you can use typeof to explicitly check for undefined, or use the weaker equality operators, but the shortest way to deal with this, and also the one that best expresses your intention of checking if an object is safe to use is probably to just rely on the type-sloppiness of JavaScript and count on it to evaluate null and undefined as false in a boolean expression, like this:
if (SomeObject.foo) {
It's very important to keep the undefined case in mind. Another case is when you expect a function to return a boolean value. What if the function forgets to return a value in some cases? Well, its return value is then undefined, which is false. So if your own default value should be true, you should really write this:
if (SomeFunction() !== false) {
Which is different from if (SomeFunction()). By the way, note the strict equality here, which preserves you from strange things like "" == 0).
But let me summarize and potentially add to the confusion before we move on to the next trick:
undefined false (SomeObject.foo) false false (SomeObject.foo != null) false true (SomeObject.foo !== null) true true (SomeObject.foo != false) true false (SomeObject.foo !== false) true false - You can't overload a function.
Developers who are used to languages like Java and C# overload methods all the time. Well, in JavaScript, there are no overloads, and if you try to define one, you won't even get an error. The interpreter will just pick the latest-defined version of the function and call it. The earlier versions will just be ignored.
The way you simulate overloading is twofold. First, if a parameter is omitted, it is undefined. And second, there is a special variable, arguments, which is an array of the function parameters. Based on the type of each parameter, you can do different things. But it's kind of ugly.
- Undeclared variables are global.
Always, always declare your variables using the var keyword. If you don't, your variable is global. So anyone who makes the same mistake as you (or more likely, if you do the same mistake in two different places) will create nice conflicts which give rise to very difficult-to-track bugs. Even loop counters should be properly declared.
There is actually a good way to do some basic sanity checks on your script files (like multiple declarations, forgotten declarations, unassigned variables, etc.): in Firefox, go to the about:config url and look for the javascript.options.strict entry. Set it to true. Now, you can point the browser to your JavaScript file. You'll get a lot of new warnings that will point to the problems in your code (if any, but I doubt that you'll get zero warnings the first time you do that).UPDATE: removed the useless rant at the beginning (I now quite like JavaScript) and corrected some mistakes in #1. - Undefined is not null, except that it is.
-
Separating Object Querying Languages from O/R mapping tools
Sebastien Ros just published a free library that enables you to query an arbitrary object graph using an XPath-like syntax.It's definitely a great idea to finally separate OQL from O/R mappers. The syntax here seems very intuitive.
It brings us closer to Cw. By the way, wouldn't it be even greater if the Navigator object could be extensible?This way, you could give it an XML document, for example, or a DataTable, or an object that has a property that is an XML document and be able to seemlessly query across the heterogeneous parts?But maybe I'm asking too much...Update: another, similar approach, but more standards-based: http://www.byte-force.com/sdfxpath/doc/ (source TSS.NET) -
Stupid tests!
So OK, so it seems like I'm a supreme nerd:
-
How to multiply a Unit by a number?
Unit Multiply(Unit indent, int depth) {
if (indent.IsEmpty) {
return Unit.Empty;
}
if (indent.Value == 0) {
return indent;
}
double indentValue = indent.Value * depth;
// I'd love not to hardcode this but Unit.MaxValue is currently private.
if (indentValue < 32767) {
return new Unit(indentValue, indent.Type);
}
else {
return new Unit(32767, indent.Type);
}
} -
A Gates paradox
I was reading this very informative interview of Bill Gates about rights management and the way it ends made me smile:Gizmodo: But I think we just disagree.Gates: No, I actually don't think we disagree.So can we agree to disagree? Or agree not to disagree about our disagreements, at least? Oh well, I'm confused. -
Are StringBuilders always faster than concatenation?
Console.WriteLine(DateTime.Now.ToString("HH:mm:ss.fffffff"));
for (int c = 0; c < 5000000; c++) {
int i = 0;
string a = "a" + i++ + "a" + i++ + "a" + i++ + "a" + i++ + "a" + i++ + "a" + i++ + "a" + i++ + "a";
}
Console.WriteLine(DateTime.Now.ToString("HH:mm:ss.fffffff"));
for (int c = 0; c < 5000000; c++) {
int i = 0;
StringBuilder sb = new StringBuilder(15);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
sb.Append(i++);
sb.Append("a");
string a = sb.ToString();
}
Console.WriteLine(DateTime.Now.ToString("HH:mm:ss.fffffff")); -
Callbacks are getting momentum, not only in ASP.NET
The recent launch of the Google Suggest beta attracted a lot of attention to XmlHttp callbacks. Such features where client-side script asks the server for very focused updates to the page without reposting it entirely have been possible ever since frames and javascript exist (I've done a web-based chat application and treeview based on hidden frame posting more than 4 years ago), but the XmlHttp APIs first found in IE 5 and then in Mozilla, Safari and Opera (without the need to use an ActiveX, which is a great improvement) have made it a lot easier and a lot less hacky. There's even an ongoing W3C attempt at standardizing such APIs (which unfortunately adds a third syntax to the IE and Mozilla syntaxes).So everyone is now realizing what potential it holds to make better web applications. Here's an interesting blog entry about the Google implementation.But even this very nice Google feature has been available for ASP.NET developers under an easy to reuse form for years: check out this excellent WebControl.This being said, to my knowledge, ASP.NET 2.0 remains the only server-side technology to natively support callbacks with ready-to-use server and client-side event-driven APIs.