Project Structure - By Artifact or Business Logic?
We're currently at a crossroads about how to structure projects. On one hand we started down the path of putting classes and files into folders that made sense according to programming speak. That it, Interfaces; Enums; Exceptions; ValueObjects; Repositories; etc. Here's a sample of a project with that layout:
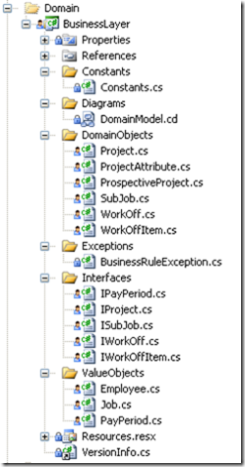
After some discussion, we thought it would make more sense to structure classes according to the business constructs they represent. In the above example, we have a Project.cs in the DomainObject folder; an IProject.cs interface in the interface folder; and a PayPeriod.cs value object (used to construct a Project object) in the ValueObjects folder. Additional objects would be added so maybe we would have a Repository folder which would contain a ProjectRepository.
Using a business aligned structure, it might make more sense to structure it according to a unit of work or use case. So everything you need for say a Project class (the class, the interface, the repository, the factory, etc.) would be in the same folder.
Here's the same project as above, restructured to put classes and files into folders (which also means namespaces as each folder is a namespace in the .NET world) that make sense to the domain.
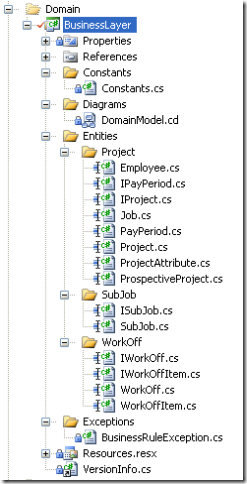
It may seem moot. Where do I put files in a solution structure? But I figured I would ask out there. So the question is, how do you structure your business layer and it's associated classes? Option 1 or Option 2 (or maybe your own structure). What are the pros and cons to each, or in the end, does it matter at all?