Archives
-
Test Detector Dialog From Hell
Got an interesting problem today. A client was using an application in a test environment. Problem was that he didn't realize it was test and entered production data values. Sometime later, the QA group needed to flush the environment. So whammy, there goes production data (we don't back up test data for obvious reasons). This created a problem with the user who claimed they didn't realize they were in a test environment.
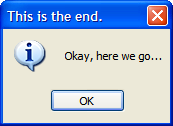
In fact, we distinctively set the caption on the application to include the environment:

And the Production version just includes the name and version:

This was actually done for two reasons. First, we needed the testers to run both QA and Production versions side-by-side so they had to be unique as far as ClickOnce was concerned. The application used a mutex to ensure only one copy of the application was running and if it was already running, it would just switch to it. The only way we found to create that mutex was by title (although on reflection there might be another) so creating a different caption would allow QA and Production to run side-by-side. In addition, the caption would include the version number and environment for quickly logging bugs and notes without having to go to an about dialog or something. The user had both versions installed (QA and Production) as they were one of the testers.
Of course this now proves to be a problem.
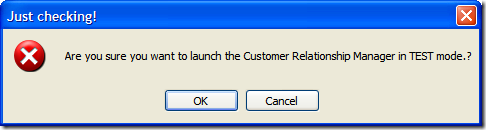
A solution we're pursuing is to pop up a confirmation dialog similar to the one below when the user was running in a non-production environment.
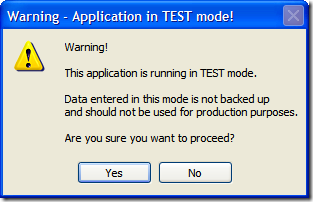
This would ensure that a) they knew they were running in a test environment and b) the confirmed they want to proceed which did a little CYA for us in case they forgot they were running this and entered in production data 4 hours later.
If the user answers "Yes" then they proceed as normal. If they answer "No" then the application shuts down. Fairly straight forward right?
Of course, I decided that one confirmation just wasn't nearly descriptive enough or sufficient for the terrible wrath that the user may be incurring upon themselves and after all, it's all about the user experience isn't it?
Sit back, relax. Imagine you're the user and you're going through these dialogs in order. I present to you a series of confirmations and messages I cal the "Test Detector Dialog From Hell".
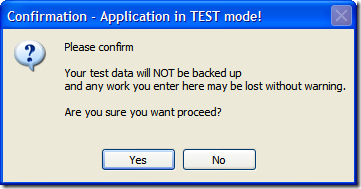
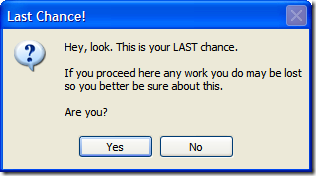
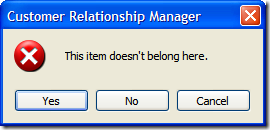
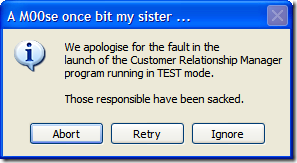
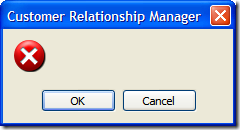
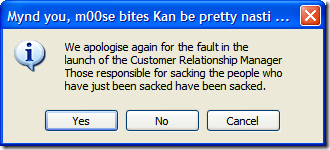
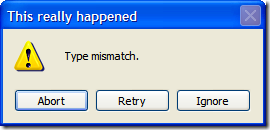
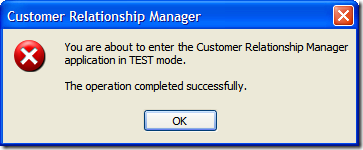
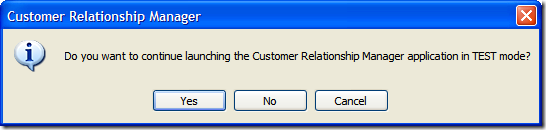
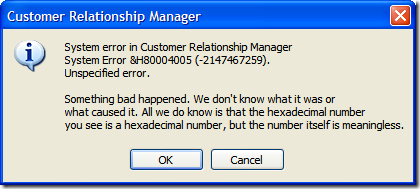
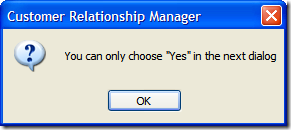
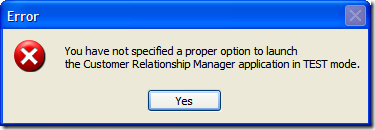
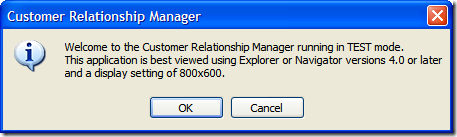
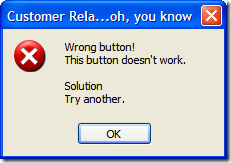

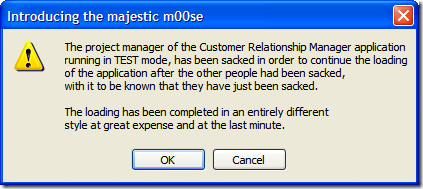

Of course, this is fine if they select "Yes", but what if they selected "No"? Well, we can't let them just quit the application. After all, maybe they didn't want to exit (or didn't even know that selecting "No" would terminate the application). So here's the first of a series of dialogs to confirm the user really wants to leave.
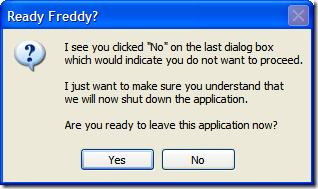
It's only a prototype at the moment, not sure if I'll put it into the application but I think it gets the point across, don't you?
P.S. An interesting side note I stumbled over as I was working on this. I was messing around with *all* of the options in MessageBox.Show and came across this dialog during testing:
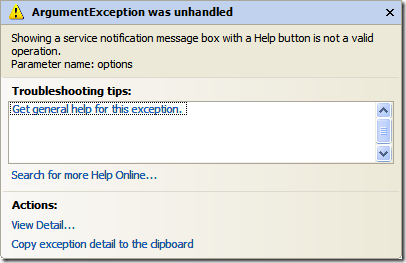
The ServiceNotification is an enumerated value from MessageBoxOptions, one of the parameters of the MessageBox.Show method. If you pass the next value in (to show a help button) as true and you pass in MessageBoxOptions.ServiceNotification in, you get this error. My question to MS, if this isn't a valid operation why let me code it! Surely you could throw a compile time error for this instead of a runtime error? Grant you, I didn't read the documentation for this (and frankly have never gone this far into the MessageBox.Show method) but still...
-
Cleaning invalid characters from SharePoint
I stumbled onto one of those "gotchas" you get with SharePoint. We were creating new document libraries based on user names in a domain. A change came in and we had to support multiple domains so a document library name would need a domain identifier (since you could have two of the same user names in two different domains). During acceptance testing we found that document libraries created with dashes in the names (as we were creating them using [domain]-[username] pattern) would strip the dash out (without telling you of course). This caused a bit of a headache with the email we send out with a link since the URL was invalid.
I remember this from a million years ago (as I'm replacing a few SharePoint brain cells with Ruby ones lately) so after a bit of Googling I found a great article by Eric Legault here on the matter.
Here's a small method with a unit test class to handle this cleansing of names.
public static string CleanInvalidCharacters(string name)
{string cleanName = name;// remove invalid characterscleanName = cleanName.Replace(@"#", string.Empty);
cleanName = cleanName.Replace(@"%", string.Empty);
cleanName = cleanName.Replace(@"&", string.Empty);
cleanName = cleanName.Replace(@"*", string.Empty);
cleanName = cleanName.Replace(@":", string.Empty);
cleanName = cleanName.Replace(@"<", string.Empty);
cleanName = cleanName.Replace(@">", string.Empty);
cleanName = cleanName.Replace(@"?", string.Empty);
cleanName = cleanName.Replace(@"\", string.Empty);
cleanName = cleanName.Replace(@"/", string.Empty);
cleanName = cleanName.Replace(@"{", string.Empty);
cleanName = cleanName.Replace(@"}", string.Empty);
cleanName = cleanName.Replace(@"|", string.Empty);
cleanName = cleanName.Replace(@"~", string.Empty);
cleanName = cleanName.Replace(@"+", string.Empty);
cleanName = cleanName.Replace(@"-", string.Empty);
cleanName = cleanName.Replace(@",", string.Empty);
cleanName = cleanName.Replace(@"(", string.Empty);
cleanName = cleanName.Replace(@")", string.Empty);
// remove periodswhile (cleanName.Contains("."))
cleanName = cleanName.Remove(cleanName.IndexOf("."), 1);// remove invalid start characterif (cleanName.StartsWith("_"))
{cleanName = cleanName.Substring(1);
}
// trim lengthif(cleanName.Length > 50)cleanName = cleanName.Substring(1, 50);
// Remove leading and trailing spacescleanName = cleanName.Trim();
// Replace spaces with %20cleanName = cleanName.Replace(" ", "%20");
return cleanName;}
[TestFixture]public class When_composing_a_document_library_name
{[Test]public void Spaces_should_be_converted_to_a_canonicalized_string()
{string invalidName = "Cookie Monster";
Assert.AreEqual("Cookie%20Monster", SharePointHelper.CleanInvalidCharacters(invalidName));
}
[Test]public void Remove_invalid_characters()
{string invalidName = @"#%&*:<>?\/{|}~+-,().";
Assert.AreEqual(string.Empty, SharePointHelper.CleanInvalidCharacters(invalidName));
}
[Test]public void Remove_invalid_underscore_start_character()
{string invalidName = "_CookieMonster";
Assert.AreEqual("CookieMonster", SharePointHelper.CleanInvalidCharacters(invalidName));
}
[Test]public void Remove_any_number_of_periods()
{string invalidName = ".Co..okie...Mon....st.er.";
Assert.AreEqual("CookieMonster", SharePointHelper.CleanInvalidCharacters(invalidName));
}
[Test]public void Names_cannot_be_longer_than_50_characters()
{string invalidName = "CookieMonster".PadRight(51, 'C');
Assert.AreEqual(50, SharePointHelper.CleanInvalidCharacters(invalidName).Length);
}
[Test]public void Leading_and_trailing_spaces_should_be_removed()
{string invalidName = " CookieMonster ";
Assert.AreEqual("CookieMonster", SharePointHelper.CleanInvalidCharacters(invalidName));
}
}
BTW, this would make for a nice 3.5 string extension method (string.ToSharePointName), but alas I'm stuck in 2.0 land for this project.
Enjoy!
-
If ALT.NET were the movie Aliens...
Dave Laribee would be Bishop.
Ayende Rahien would be the bad ass Powerloader Ripley uses at the end of the movie to kick the Alien Queen's butt!
Scott Bellware would be a male version of Vasquez.
The strangest things spew forth from Twitter. Idea by Chad Myers. Feel free to continue in comments or whatever...
-
altnetpedia.com
Looks like pr0n spam bots have airlifted in and wreaked havoc on the altnetpedia site. Our highly trained monkeys are looking to restore things back to normal so please chill in the lounge for awhile as we startup the silo. Thanks.
Update: Thanks to the uber-super-sleuthing skills of James "the Enforcer" Kovacs, the site is back online. We now return you to your regularily scheduled programming.
-
stackoverflow.HelloWorld(new stackoverflow.HelloWorld())
What happens when you get Jeff Atwood together with Joel Splosky and give them a microphone? You get a podcast where two guys chatter about life, the universe, and computers. The inaugural episode of the new podcast is alive and kicking on a new site and covers pretty much everything. Vista; Mac; FogBuz; Microsoft is evil (really? I didn't know); 9600 baud modems; iPhone; MSN; Google; Browsers; Coke vs. Pepsi; Vista; Wikis; Hardware; The Origin of the Species. You name it, it's there and delivered in style from top guys in the industry. Poor Jeff had to fish out his credit card and install Apple software to get the podcast published on iTunes, but it's there for the world to enjoy. Just listening to the first episode on the train ride in this morning. Great stuff! Check out the site here and you can grab the first episode (direct download) here.
-
SharePoint A To Z - The Blog Series
I'm embarking on a series of blog posts on SharePoint, that wonderful and whacky platform by Microsoft we all love to hate. In the series, I'll grab a single feature, tool, technology, or concept aligned to a letter in the alphabet (hence the SharePoint A To Z titles) and write a post on it.
Each post will be anywhere from 5-10 pages long and they'll be a whopping 26 of them, one for every letter in the English alphabet. Not sure how long it'll take to finish the series but bookmark this page as it's the landing page for the entire series and will be updated as each post comes out (a PDF will be available once they're all done).
All posts are generally developer related (with some tools thrown in for good measure) and should cover almost the entire SharePoint developer spectrum (at least that's the goal). Also these posts are strictly WSS 3.0/MOSS 2007 stuff as I won't be covering past or future versions (hey, there's only so many hours in a day!).
Depending on comments from you, some of the topics in the list might change (as my initial choices may be lame and boring) based on demand so feel free to drive this in whatever direction you want.
Okay, here's the list (updated with more catchy and descriptive titles and links to the posts as they become available):
A AJAX and SharePoint B BLOB Storage C CAML D DataSources and DataTables E Event Handlers F Features G Groups H Helper Classes I ICellProvider and ICellConsumer, Making Web Parts Talk J Jobs and Timers K Keywords, Queries, and Search L Lists M Mobile Development N Navigation O Optimizing Your Code P Permissions Q QuickLaunch R Records Repository S Sites and Meeting Workspaces T Test Driven Development and SharePoint U Updating and Upgrading V Views W Web Parts, Workflows, and Web Services X XML is here to stay Y Your Information - Social Networking with SharePoint Z Zones -
Continuous Integration Feature Matrix
This is just a post to direct people to the CI Feature Matrix that ThoughtWorks maintains. If you're up in the air about choosing a CI system, then this is the page for you. They maintain an unbiased view (their words, not mine) of all the CI systems out there (and there are a lot of them). So if you're wondering or looking for something, check it out.
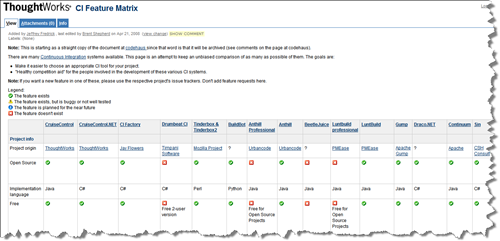
Note: TW says the page is unbiased and I believe them, however when anyone puts together a matrix like this sometimes they tend to include features that only *your* system has (so you can create a checkmark in that column) that no other system can measure up to. I don't feel TW did this here, but I do want to point out this for making your own unbiased comparison.
If anything, the matrix can be used as an idea generator. Wherever you see a red
 and the project is open source, maybe it's time to sit
down and write a plugin/patch/add-on and contribute!
Think about it and give it some consideration, it would
only make these projects even better with more
capabilities.
and the project is open source, maybe it's time to sit
down and write a plugin/patch/add-on and contribute!
Think about it and give it some consideration, it would
only make these projects even better with more
capabilities.
-
UI Exception Handling vs. AppDomain Exceptions
I'm building an uber-exception handling system for all of our apps at work (basically handle unexpected exceptions and post them to out bug tracker, JIRA) and wanted to clear up some confusion on the differences between unhandled exceptions. As an FYI, this information is just for WinForm apps.
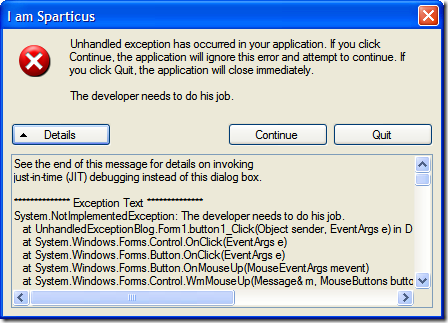
By default if you create a new WinForm app any unhandled exceptions are tossed into a dialog box like this:
Perhaps while you're debugging you've seen this:
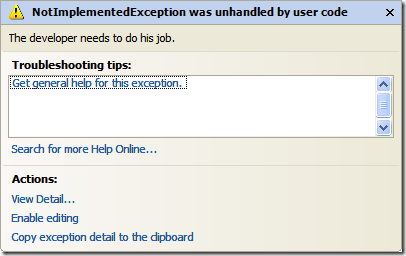
That's the built-in exception assistant Visual Studio provides. It kicks in when running your app from inside the IDE and lets you inspect your system. At this point you're basically screwed and something terrible has happened, so this is your last chance to maybe see what went wrong.
The exception assistant is useful as you can edit your code on the fly, crack open the exception (and investigate other values), or just continue along your merry way. If the exception assistant really irks you, you can go into the Debugger options for visual studio and disable it. When you do this, you'll get a dialog that looks like this:
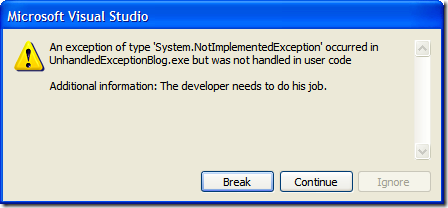
Not as descriptive as the exception assistant, but more intuitive if you just want to motor along (say to your own handler which is what we'll do).
Let's setup an unhandled exception catcher. Here's our main code before we add the handler:
[STAThread] static void Main() { Application.EnableVisualStyles(); Application.SetCompatibleTextRenderingDefault(false); Application.Run(new Form1()); }
Now my kung-fu design skillz kick in and we'll build a highly sophisticated UI to drive our exception handler. Behold the mighty user interface to end all user interfaces:
To create a handler we create a method and attach it to the ThreadException event handler. In our app we'll throw some exception and let the system handle it. Here's the updated code:
[STAThread] static void Main() { Application.EnableVisualStyles(); Application.SetCompatibleTextRenderingDefault(false); Application.ThreadException += Application_ThreadException; Application.Run(new Form1()); } static void Application_ThreadException(object sender, ThreadExceptionEventArgs e) { MessageBox.Show("Something terrible has happened."); }
We've tied into the ThreadException handler on the Application class with our own method that will dump the exception to a simple dialog box:
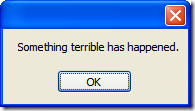
However in the AppDomain class there's an UnhandledException handler that you can tie into, just like we did with the ThreadException on the Application class above. The ThreadException is for dealing with exceptions thrown on that thread (and in this case, its our main form) but the AppDomain handler is for *any* unhandled exception thrown (for example, a SOAP call to a web service). So we should hook into that one as well like so:
[STAThread] static void Main() { ... AppDomain.CurrentDomain.UnhandledException += CurrentDomain_UnhandledException; ... } static void CurrentDomain_UnhandledException(object sender, UnhandledExceptionEventArgs e) { MessageBox.Show("Something else has happened."); }
You might also notice the signature is different. Rather then getting a ThreadExceptionEventArgs object we get an UnhandledExceptionEventArgs one. The differences are subtle:
- ThreadExceptionEventArgs contains a property of type Exception that is the exception that was thrown
- UnhandledExceptionEventArgs contains a property called ExceptionObject which is the exception thrown (except that it's of type object rather than an Exception)
- UnhandledExceptionEventArgs also contains a bool property called IsTerminating which tells you if the CLR is about to shut down
The question is, does that make our ThreadException handler obsolete? Not really but there's different behaviour around the exception handler based on another setting. In the Application class there's a method called SetUnhandledExceptionMode which lets you control how thread exceptions are handled:
[STAThread] static void Main() { ... Application.SetUnhandledExceptionMode(UnhandledExceptionMode.ThrowException); ...
}Adding this to your setup can result in two different behaviours:
- If you set it to ThrowException, then your CurrentDomain_UnhandledException method is called (even before the Visual Studio IDE gets ahold of it) and the Application_ThreadException method is never called.
- If you set it to CatchException, then your Application_ThreadException method is called. If you're running inside Visual Studio, the IDE steps in before this with it's own exception handler first then control is passed onto your method if you continue with execution.
One little extra note, if you choose option #1 and call SetUnhandledExceptionMode to ThrowException your AppDomain handler gets called but running outside the IDE you'll get this lovely dialog box:
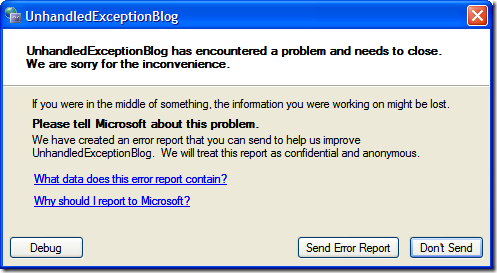
Your app generally shouldn't report information to Microsoft (unless you're really important), but this is what happens when running your app in normal user mode rather than developer mode. I'm not sure if there's a way to prevent having this bad boy popup on you when you hook into the AppDomain event handler (feel free to chime in on the blogs comments if you know how).
Hope that clears up a little on how exceptions work and the different behaviours you can get out of them. Happy exception handling!
-
3 Geeks in an Elevator
Recently at the MVP Summit, Scott Cate was stuck in an elevator for a short stint (last night actually as he told the world his ordeal via Twitter). Elsewhere in the universe, a video surfaced of Nicholas White who was trapped in a New York elevator back in 1999. For 41 hours. Being stuck in an elevator is one thing, being stuck there for 3 days without the ability to pee is a whole 'nuther world.
It piqued my curiosity though. If you were trapped in an elevator for 41 hours who would you want to have with you and what would you talk about? So here's my Internet meme experiment. Blog your idea and link back or leave a comment here on my blog. There are of course some rules:
-
You're allowed to spend your elevator time with 2 people and they must be living (that leaves Keith Richards and Charles Babbage out).
-
They must be of the geek persuasion. This could be anyone from famous to unknown (Bill Gates, Steve Wozniak, Ward Cunningham, or even Justice Gray, be creative).
-
You have 41 hours with them in an elevator and no access to the Internet, a laptop or any other technology to speak of. Just you, two geeks, and your powers of conversation.
Being locked up with someone for this long, what would you talk about? Would you pit Linus Torvalds against Bill Gates on an open source discussion, or pair up Martin Fowler with Donald Belcham to discuss the finer points of Canadian whiskey?
Okay, go.
-
-
First Looks: Mingle 2.0
I have Mingle 2.0 upgraded in our test environment and have been going through the new features, upgrade woes, and some remarks from the peanut gallery. Here's the rundown on this Agile planning tool.

Upgrading
Upgrading was a bit of a pain. To do the test I backed up our Mingle db and restored it to sandbox database on the same MySQL instance and installed a clean copy of Mingle 1.1. Then upgraded 2.0 over top of it (once the 1.1 was working with the new db).
Mingle didn't know what port I originally installed on (my test install was on 888) and defaults to 8080. This can be confusing to a user who's installing an upgrade and didn't perform the original install or doesn't know what port was originally used.
I have unlocker running and it briefly kicked in on some .rb file (it flashed by so quickly you couldn't tell what it was). Didn't seem to be a problem but the Mingle upgrade killed off a whole bunch of processes running on my desktop. For example WinZip, Unlocker, and my anti-virus were all killed off (which might explain the brief flash of Unlocker as it went down) during the install. I know it's "traditional" to shut down all running processes during an install of something new, but I think it's a little over the top to shut them down for you (and especially since it did it without warning)
After the install browsing to localhost:888 failed. I checked the logs and found it had a problem trying to add a column to the db that was already there. After a 10 minute restore/reset (with a couple of well-placed reboots after each install) the install finally worked.
It was painful and luckily I was working on a test database. For sure I recommend doing a backup and upgrade over a temporary working database. Then if all goes well, backup your production db and do the upgrade (backing out if it doesn't work). Don't get too torqued if the browse to the instance doesn't work after the upgrade, just reboot the server (I know, pretty severe) and it should be all fine when you get back.
All in all, the upgrade wasn't horrible. You'll probably want/need to go in and make some mass changes to cards and stories in play in order to leverage the new features but it's fairly quick and painless with the Web 2.0 UI they've built on.
For sure check out the Mingle forums on upgrading/installing as there are a few people trying it on different systems and experiencing various pain points.
New Project Creation
The new project creation screen is basically the same. They have upgraded the Agile hybrid, Scrum, and Xp templates to version 2.0 (but only left the Xp 1.1 template, not sure why here). A minor change in the UI in 2.0 is they added a header/footer with the "Create Project | Cancel | Back to project list" links which is handy.
Project Admin
There's some minor shifts in project admin that are both cosmetic and functional. The Project Settings screen now has the SVN repository info separated out and adds a new field, Numeric Precision. This lets you deal with precision in your numbers on cards, stories, etc. By default it's set to 2 but you can increase it if you need it. I don't recall seeing this as a high priority feature but whatever. It's there now.
Like I said, the Project Repository settings (for integration into source control) has been pulled out into it's own screen. This is for good reason. The first thing you do is pick the version control system you're using from a drop down. Only Subversion is supported in this release, but you can see where it's going (perhaps with support from 3rd party providers). Somewhere in my browsing today I saw TW announce a future release to incorpoate Clear Case or some other SCM so others won't be far behind.
They've introduced the notion of "Project variables". Think of NAnt properties or something that can be used in cards or views. For example you can create a project variable called "Current Release" and give it a value of "1" or "3.2 GA" or whatever (with various data types including numeric, text, date, etc.). Wherever you use this it'll just replace that value. Then you can change en-mass "3.2 GA" to "4.0 RC1" or something and anywhere it's being used it gets swapped out.
The new advanced admin feature is recaluating project aggregates. We'll talk about aggregates later but if you find the numbers might be out of whack, go to Advanced prroject admin to recalculate them.
In 1.1, any view could be saved. From the "Saved views & tabs option" you could take a view a make a tab out of it. Now the feature is called "Favorites & tabs". Favorites are saved views that have not been added as tabs and there's two tables here to show you tabs vs. views. Tomatoe, tomatoe.
Card trees are available to edit or delete so let's talk about this in-depth.
Card trees

Card trees let you define a heirachy that works for your system. You can check out a video here that explains it well. For example, tasks can roll up under stories that roll up into features that roll up in epics. This is the ultimate in flexibility and lets you move things around as sets. There's a new Card explorer that lets you drag and drop cards from the right hand flyout so you can quickly (and visually) move your cards around in the view.
This is great and how I work. I usually break a system down by epics which then might flow into features which are made up of stories (I personally don't like getting down to the task level but YMMV). Now I can lay my project out visually and see where everything fits in and this lets me do things like track stories against a feature or bugs against a story. The notion of Done, Done, Done gets much clearer with Mingle 2.0.
Aggregates
In addition to Card trees there are attributes in cards trees called Aggregates that will allow you to roll up information into swimlanes. For example I can sum up all the story points in a feature or functional areas and in the Grid display, show that value. At a glance I see how many points I can deliver for that group. This is great for say release planning where you create a plan showing the sum of all points for each story in the sprint. Knowing your velocity of say 12, you know you can't drag more than 12 points into a sprint. Nice.
The UI is improved and starts to border on a video game like approach to Agile planning. If you drag an aggregate root, all it's children will follow. This makes for easily positioning things on the screen and moving things around, and is pretty fun to watch. Also I would hope a future feature will be a PNG or JPEG export of the tree (much like the image export from Visual Studio's class designer) as you might need an image for documentation or discussion where you don't have online access to Mingle.
Configuration
There's a new option on the main screen, configure email settings. This allows you to change where you SMTP server is and who the email comes from and includes a test link. A huge improvement over having to hunt for the config file and edit it by hand. I know screens like this start bloating out the product which is very lean, but I feel it's better served to have configuration this way rather than 100 text files buried in the file system somewhere. And the test feature is nice as it helps you as you go.
Templates
I didn't get a chance to look at all the templates but the updates to the include some new transitions. Transitions are one of the lesser-known features of Mingle and lets you set up a pseudo-workflow for Cards. In the new Scrum 2.0 template for example there are transitions that let you do a single click "Complete Development" or "Soft Delete". Transitions have filters and constraints (for example you can only invoke a transition if the card type is a Story and was created Today) and just make it easier to use Mingle. Check out the ones in the new templates and create your own. The new Scrum template includes a new dashboard (the Overview page) with story metrics (project status by points) and new graphs like a burndown chart and % of completed tasks per story. These use the new aggregate functions and quite useful to get a quick overview of the project.
Overall
Overall I'm happy with the upgrade. Even though it was a little painful and didn't work initially, in the end it's for the better. The heirachial cards feature is great and there are lots of nice little improvements everywhere (for example the consistent command bar on forms) that make this product even more useful for Agile planning. They spoke of better documentation and I'm looking to integrate Mingle with LDAP. I see there's a new LDAP configuration page but like most Mingle documenation, it's just a rehash of what you might see on the screen or lines in a config file with no real explanation of what is valid and what isn't.
I guess it's part trial-and-error, part knowledge, but I had hoped for more detailed documentation. Perhaps in the future they'll provide something like a wiki interface to the documentation and allow contributions from users to improve the readability of topics and additions of scenarios. To me, that's of the best things with projects like MySQL and PHP (and to a lesser extent the MSDN documentation). Hopefully TW will follow in these footsteps.
With the short release cycles ThoughtWorks employs I don't have to wait a year to see new improvements to a overall good product. Well done guys!
For a list of the top 10 new features in Mingle 2.0, check out this page by ThoughtWorks. Happy upgrading!
-
Being Agile is our favorite thing
When ThoughtWorkers watch too many Julie Andrews movies:
-
Unit Test Projects or Not?
 It's funny how the world works. A butterfly flaps it's
wings in Brazil, and a tornado forms in Texas 1,000
miles away.
Phil Haack
posted
a poll about unit test project structure
and asked the very question we've come to on our current
project. Should unit tests belong in their own project
or as part of the system? I was going to post a comment
on Phil's entry, but figured I would drag my explanation
and description out to a full post here.
It's funny how the world works. A butterfly flaps it's
wings in Brazil, and a tornado forms in Texas 1,000
miles away.
Phil Haack
posted
a poll about unit test project structure
and asked the very question we've come to on our current
project. Should unit tests belong in their own project
or as part of the system? I was going to post a comment
on Phil's entry, but figured I would drag my explanation
and description out to a full post here.
In the past I've *always* created a separate test project. Tree Surgeon by default does this (and now I'm looking at adding an option to let you decide at code generation time) and most projects I know of work this way. You create your MyApp.Core project (containing your domain logic) and a MyApp.Test project with all the unit tests. More recently I've been creating MyApp.Specs project but that's just a different evolution.
In the next project we're working on, we're looking to shift this approach. A shift to include unit tests in our MyApp.Core project. Here's some reasons and thinking behind it.
With unit tests (or specifications) in a separate project you end up mimicking the structure of your domain and create a namespace hierarchy. By default .NET assemblies have a default namespace for your application and then the name of any folder in the project is appended to the default namespace. So if your assemblies default namespace is MyApp.Core (and the namespace defaults to the name of the assembly) and you create a folder called Customer, all classes in that folder will be in the MyApp.Core.Customer namespace. In your test project you have a similar thing and usually you'll have the default namespace to be MyApp.Test (the name of the assembly).
Since there is only one test assembly (assuming you don't break them up that is) then you don't necessarily want to create a folder called CustomerSpecs (or CustomerTests or even Customer) so you might create a folder called Domain. After all, you're unit testing the domain but then they'll be the UI, Presenters, Factories, Data Access, etc. Do you create a separate test assembly for all of these? Probably not.
Let's see, we have an assembly (MyApp.Core), a class (Customer) in a namespace (MyApp.Core.Customer). Now you've got a test assembly (MyApp.Test), a set of Customer tests (CustomerSpecs.cs or CustomerTests.cs or whatever) in a domain namespace (MyApp.Test.Domain). This is getting a little complicated, but no big deal from a resolution perspective. You'll just bring in the namespaces you need and bang (or BAM!).
However two things seem to arise out of this setup.
First (which might kick off it's own huge debate) you need access to your Customer class and potentially other classes, enumerations, etc. that it uses which are locked away in MyApp.Core.dll. That means you have two options. Either you make the Customer class public or you use the InternalsVisibleTo attribute to let MyApp.Test.dll see the stuff inside of MyApp.Core.dll. There's another option here, slam all the files into one assembly and don't worry about it from a testing perspective. That might alleviate the problem but that's a different blog entry.
The second thing that comes out of this is a fairly deep and wide namespace hierarchy in your test assembly. That might not be a big deal unto itself, but could be an inconvenience. In addition the deep impact this might cause, let's say you have 30 domain classes and the subsequent 30 or so fixtures (or more, or less, doesn't really matter). And these are scattered around in various folders. Each time you touch the fixture to write a test or look at the domain object and create some test, you're playing hunt and peck inside your test assembly to find the right spot to match the folder structure. Of course if you don't care and toss everything into a single folder you won't care, but I think that's a different type of maintenance you don't want to get into. Then, let's say you restructure your domain (which can happen a few times throughout a project) and now some of the classes relating to Customer move into some other place in the hierarchy in your domain. That's easy enough with ReSharper and a move like this is pretty low-maintenance. Except now your test folder structure doesn't match your logical domain structure (or folder structure for that matter).
Okay, that's the side of the conversation about issues that we've come to on using a separate test project. Now the positives on including your tests with the code you're testing.
- I don't need a separate Test project. There's a bit of debate in the blog-o-sphere around number of projects and what's right and what's too much so keeping things lean is good.
- I don't have to go hunting for a fixture in some hierarchy that may (or may not) be valid or the same as my domain. With ReSharper it's easy to find files/classes, but using a separate test project I have double maintenance to deal with. If I want to keep them in sync, it's more work.
- I don't have to expose my domain to my tests. As everything is in one project I can use OO principles and maintain encapsulation. When you create a new class, there's a damn good reason it's marked as internal and not public. If my entire domain is internal I can choose to expose what I need outside of the system/assembly as needed rather than "make it public so the test assembly can see it". True, there are tricks to expose MyApp.Core.dll to MyApp.Test.dll but they're hacks IMHO.
- I can leverage my unit testing framework in my runtime environment. This is probably the biggest advantage I see when I do something like create a Test folder under my Customer folder in my domain project. I can choose to ship my unit testing framework tools (MbUnit.Framework.dll or MbUnit.Gui.exe) with my system. This would be useful say in a QA or User Acceptance environment where I can run my tests against the real environment. This might not be something you want to do all the time, but I think it's good to have the option.
Here are some arguments I've heard for including your test code with production code that I'll address.
"If my tests are in my domain, I have a reliance on my unit test framework assemblies" - Yeah? So. If I wrap log4net I have a dependency on deploying log4net.dll as well. I'm not sure I see a disadvantage to this. There's been people saying they were "bitten" by this, but I'm sure what the bite is like or what the impact of that bite might be. Optionally, when we deploy we can decide to deploy our test code and it's dependencies as needed. Just because it's there doesn't mean it needs to go out the door. If we use our NAnt build scripts, we can not include the *Test* code and omit the MbUnit.Framework.dll files. Clean and lean.
"I want to see my tests and only my tests in one project and what I'm testing in another" - Again, not sure the advantage to this. If anything, keeping them together reduces the amount of "jumping" around you do in your IDE from this project to a test project, then back again. I'm not convinced or sure why you "want" to see tests in one project.
"Production code is production code and not test code!" - Not sure what this means, since I consider *all* code production code, tests, classes, etc. The ability to unit test my "production code" in a "production environment" rather than some simulation is a bonus for me.
All in all there's no clear cut answer here. What works for you works and I think the general mass keep tests in a separate project. I want to buck the norm here and for the next project we're going to try it out differently. I think there's advantages to it (and potentially disadvantages, like having to potentially clutter up my .Core assembly with a bunch of ObjectMother classes for example) but we'll see how it goes.
I don't like not trying something because "that's the way we always did it". Doesn't make it right. So give it a shot if you want, try it out, share your experience, or leave a comment that I'm a mad coder and putting my devs through unnecessary torture.
Like Phil said, this is not "a better way" or "the right" or "wrong" way to do things. I'm going with a Test folder under my aggregate classes in my domain and we'll how that goes. YMMV.
-
var award = new { Product = "SharePoint Server", Name = "Bil Simser", Year = 2008 };
It's that time of the year for me again. The MVP cycle is upon us (it happens 3 or 4 times a year, my cycle lands ironically on April 1st). So as much of a joke as it may be, I'm here for another year. Yes, Mr. TooManyProjectsOnHisPlate is a SharePoint Server MVP again. Maybe I'll get off my laurels and pump something cool out this year. Or maybe I'll just sit on my big fat buttocks and think up clever ways to incorporate comic book art into blog entries. In any case, SharePoint MVP April 2008-April 2009 again (4th year running now. Or is it 5? I've lost count).
-
Sorting Out The Pursefights
 Okay, by now all of you with a few ounces of grey
matter have figured out that today's earlier post was an
April Fools joke. I am not the ALT.NET pursefight guy
and in fact, the blog post wasn't even written by me.
Okay, by now all of you with a few ounces of grey
matter have figured out that today's earlier post was an
April Fools joke. I am not the ALT.NET pursefight guy
and in fact, the blog post wasn't even written by me.
Here's skinny. A few days ago ex-Canadian cool kat Kyle came up with the plan (yes, he's the mastermind behind this madness). We would all post about something and post on each other's blogs, thereby confusing said reader (that would be you) and hilarity should ensure.
Various topics were thrown out (Google, Yahoo, Geeks who get laid, best goat raping techniques, etc.) but one seemed to be an interesting diamond in a bed of coal. The elusive identity of the ALT.NET Pursefight blogger (whom to this day I still don't know who it is).
The schedule was set and we all went to create our masterpieces. Of course The Mad Mexican made his appearance, albeit in the shower and in video. I'm not sure if I'm still over the Beth Massi affair in Vancouver so seeing MM in the shower just threw my whole day off.
In any case, here's the lowdown on who posted what and where:
- Donald Belcham posted his entry here on my site
- I posted my blog entry on Dave Woods site
- Dave Woods posted his entry on D'Arcy's site
- D'Arcy posted his entry on Sergio Pereira's site
- Sergio posted his on Tom's site
- Tom Opgenorth posted his entry on Kyle's site
- Kyle posted his entry on Derik Wittaker's site
- Derik Wittaker posted his entry on Donald's site
And Sean Chambers, who wasn't really in this little ALT.NET pursefight meme of ours, went ahead and posted his own claim to fame. Good for you Mr. Glory Hound ;)
There you have it. The circle is now complete. The kimono is open and the magicians have shown you how we sawed the lady in half.
See you next year!
-
I Am Pursefight
The darkness of anonymity has finally gotten to me. I can't take it any more. First it was a group of alcoholics that I hung around with who decided to go 'anonymous' *. Then it was my poker buddies **. It finally got to me and before I knew it I was an anonymous blogger. Oh, you knew it all along folks. I'm the bad ass, Perez Hilton wanna-be exposing the dirty laundry of the Alt.Net world. I am Pursefight.

Today I'm coming clean and claiming what is rightfully mine. I've been silent for some time now as I've wrestled with this decision. I'm not sure I'm ready for the lime light, the paparazzi or the fame. I know that if it starts to be a burden I will post to the newsgroup asking you for your opinion and guidance. The initial four weeks of discussion will be spent deciding on how, or even if, we should define 'fame'. After that we will settle down into a fine bit of Alt.Net name calling and personal attacks.
Regardless, I have been, and will continue to be, here for you. Every day I will be at the pier waiting for you...for I am Pursefight.
* While I don't condone binge drinking, I sure hate a quitter.
** I don't suggest gambling away your child's pre-school tuition. I named her Vista though...I'm guessing that pre-school isn't going to help her get over that.
-
The Justice Gray Credit Card, get yours today!
Capital One is offering the ability to design your own credit card. So I did. Naturally I chose the first thing the popped into my head.
Fluffy Kittens?

Nope.
Giant Monster Trucks.

No way.
Hugo Chavez?

Nah.
Well of course, I picked my favourite blogger.
Ladies and Gentlemen, I present to you the Justice Gray Capital One card.

Don't leave home without him!